Wysoka dostępność jest wymogiem dla wielu systemów, niezależnie od używanej technologii. Jest to szczególnie ważne w przypadku baz danych, ponieważ przechowują one dane, na których opierają się aplikacje. W zależności od wymagań istnieją różne sposoby wdrożenia środowiska wysokiej dostępności dla PostgreSQL, ale zawsze konieczne jest użycie dodatkowego narzędzia, ponieważ natywne funkcje PostgreSQL nie wystarczą.
W tym blogu zobaczymy, jak wdrożyć Percona Distribution dla PostgreSQL w celu zapewnienia wysokiej dostępności i jakie narzędzia są do tego niezbędne.
Dystrybucja Percona dla PostgreSQL
Jest to zbiór narzędzi pomagających w zarządzaniu systemem baz danych PostgreSQL. Instaluje PostgreSQL i uzupełnia go o wybór rozszerzeń, które umożliwiają efektywne rozwiązywanie podstawowych praktycznych zadań, w tym:
- pg_repack :Odbudowuje obiekty bazy danych PostgreSQL.
- pgaudit :Zapewnia szczegółowe rejestrowanie audytu sesji lub obiektu za pośrednictwem standardowej funkcji rejestrowania PostgreSQL.
- pgBackRest :Jest to rozwiązanie do tworzenia kopii zapasowych i przywracania dla PostgreSQL.
- Patroni :Jest to rozwiązanie wysokiej dostępności dla PostgreSQL.
- pg_stat_monitor :Zbiera i agreguje statystyki dla PostgreSQL i dostarcza informacje o histogramie.
- Zbiór dodatkowych rozszerzeń contrib PostgreSQL.
Wysoka dostępność w PostgreSQL
Istnieją różne architektury wysokiej dostępności PostgreSQL, ale najczęstszą jest topologia Master-Slave (Primary-Standby). Opiera się na jednej podstawowej bazie danych z co najmniej jednym węzłem rezerwowym. Te rezerwowe bazy danych pozostaną zsynchronizowane (lub prawie zsynchronizowane) z bazą podstawową, w zależności od tego, czy replikacja jest synchroniczna, czy asynchroniczna. Jeśli główny serwer ulegnie awarii, rezerwa zawiera prawie wszystkie dane głównego serwera i może zostać szybko przekształcona w nowy podstawowy serwer bazy danych.
Jednak konfiguracja master-slave nie wystarczy, aby skutecznie zapewnić wysoką dostępność, ponieważ trzeba również radzić sobie z awariami. Po wykryciu awarii powinieneś być w stanie wybrać węzeł rezerwowy i przejść do niego awaryjnie z możliwie najmniejszym opóźnieniem. Sam PostgreSQL nie zawiera automatycznego mechanizmu przełączania awaryjnego, więc do tej automatyzacji będzie potrzebny niestandardowy skrypt lub narzędzia innych firm.
Po wystąpieniu awarii, aplikacje muszą zostać odpowiednio powiadomione, aby mogły zacząć korzystać z nowego węzła podstawowego. Ponadto należy ocenić stan naszej architektury po przełączeniu awaryjnym, ponieważ można uruchomić w sytuacji, w której działa tylko nowa podstawowa (tj. przed problemem miałeś węzeł podstawowy i tylko jeden zapasowy). W takim przypadku będziesz musiał jakoś dodać nowy węzeł gotowości, aby odtworzyć konfigurację master-slave, którą pierwotnie miałeś dla wysokiej dostępności.
Aby to zadziałało, będziesz potrzebować różnych narzędzi/usług, które pomogą Ci w tym zadaniu.
Systemy równoważenia obciążenia
Systemy równoważenia obciążenia to narzędzia, których można użyć do zarządzania ruchem z Twojej aplikacji, aby jak najlepiej wykorzystać architekturę bazy danych.
Przydaje się nie tylko do równoważenia obciążenia naszych baz danych, ale także pomaga przekierowywać aplikacje do dostępnych/zdrowych węzłów, a nawet określać porty z różnymi rolami.
HAProxy to moduł równoważenia obciążenia, który rozdziela ruch z jednego źródła do jednego lub więcej miejsc docelowych i może zdefiniować określone reguły i/lub protokoły dla tego zadania. Jeśli którykolwiek z miejsc docelowych przestanie odpowiadać, jest oznaczany jako offline, a ruch jest przesyłany do pozostałych dostępnych miejsc docelowych.
Keepalived to usługa, która umożliwia skonfigurowanie wirtualnego adresu IP w ramach aktywnej/pasywnej grupy serwerów. Ten wirtualny adres IP jest przypisany do aktywnego serwera. Jeśli ten serwer ulegnie awarii, adres IP zostanie automatycznie przeniesiony do „dodatkowego” serwera pasywnego, umożliwiając mu dalszą pracę z tym samym adresem IP w sposób przejrzysty dla systemów.
Aby zaimplementować wszystkie te rzeczy, możesz to zrobić ręcznie, co oznacza dodatkową pracę i czasochłonne zadania, lub możesz to zrobić w jednym systemie za pomocą ClusterControl.
Zobaczmy, jak zaimportować istniejącą dystrybucję Percona dla PostgreSQL do ClusterControl, a następnie jak skonfigurować środowisko wysokiej dostępności za pomocą HAProxy i Keepalived wokół tej konfiguracji z przyjaznego i łatwego w użyciu interfejsu.
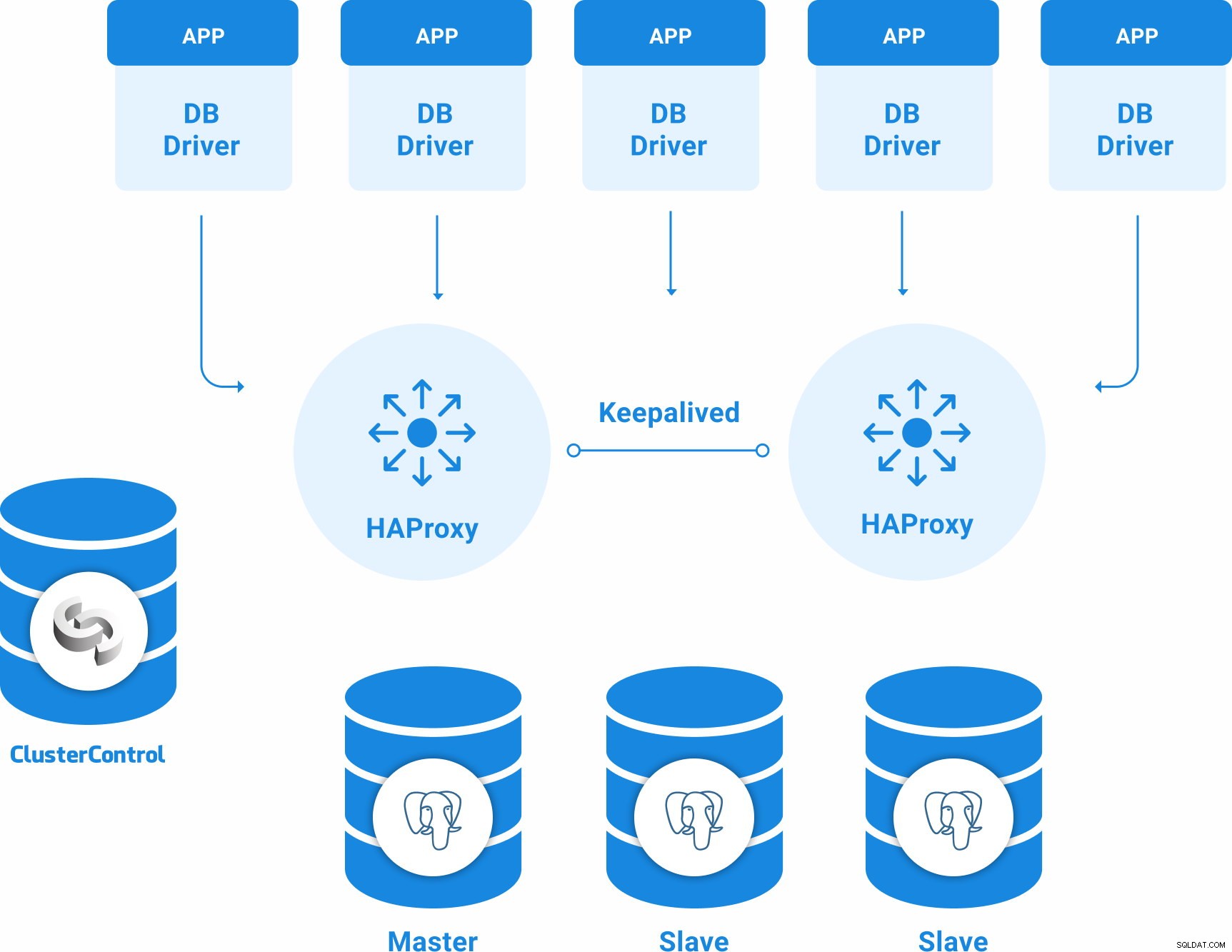
Topologia PostgreSQL zapewniająca wysoką dostępność
Podstawową topologią wysokiej dostępności dla PostgreSQL może być:
- 3 serwery PostgreSQL 12 (jeden węzły podstawowe i dwa węzły rezerwowe).
- 2 systemy równoważenia obciążenia HAProxy.
- Utrzymuj konfigurację między serwerami równoważenia obciążenia.
- 1 serwer ClusterControl
Więc będziesz mieć następującą topologię:
Jak zainstalować Percona Distribution dla PostgreSQL
Zacznijmy od instalacji Percona Distribution dla PostgreSQL. W tym przykładzie użyjemy CentOS 7 i PostgreSQL 12.
Jeśli masz zainstalowany klaster, przejdź do następnej sekcji, aby zaimportować istniejącą bazę danych do ClusterControl.
Zainstaluj epel-release i percona-release
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmWłącz repozytorium PostgreSQL 12
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!Zainstaluj pakiet serwera
$ yum install percona-postgresql12-serverPamiętaj, że ten pakiet nie zainstaluje wszystkich składników Percona Distribution. Aby zainstalować te komponenty, użyj odpowiednich opcjonalnych pakietów, jak pokazano poniżej:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribZainicjuj bazę danych
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKUpewnij się, że masz poprawną konfigurację, aby móc skonfigurować replikację PostgreSQL, podobnie jak:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onNastępnie uruchom usługę bazy danych
$ systemctl start postgresql-12Teraz, jeśli chcesz dodać węzły rezerwowe, powtórz kroki 1, 2 i 3 we wszystkich węzłach, które chcesz dodać do klastra. W przypadku tych węzłów nie musisz nic więcej konfigurować, ponieważ ClusterControl utworzy odpowiednią konfigurację.
Importowanie dystrybucji Percona dla PostgreSQL w ClusterControl
Dzięki ClusterControl możesz wdrażać lub importować różne silniki baz danych typu open source z tego samego systemu, a do korzystania z niego wymagany jest tylko dostęp SSH i uprzywilejowany użytkownik.
Przejdź do sekcji „Importuj” i uzupełnij wymagane informacje o swoim serwerze PostgreSQL.
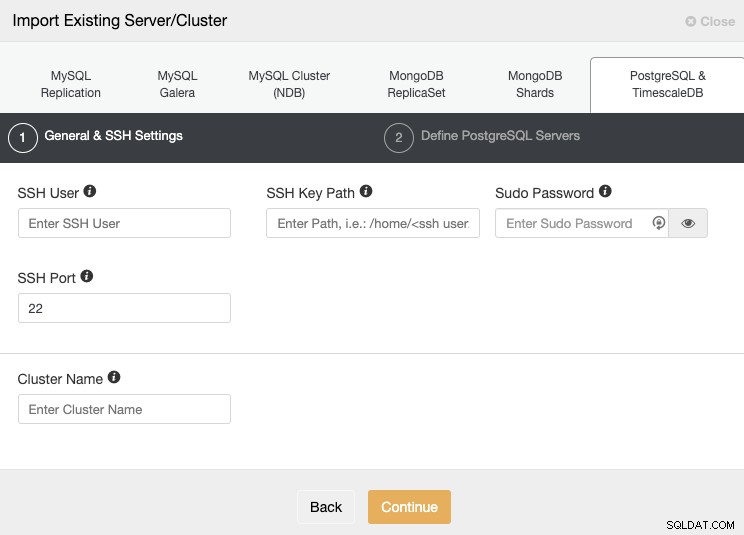
Musisz określić użytkownika, klucz lub hasło oraz port, aby połączyć się przez SSH do swoich serwerów. Potrzebujesz również nazwy dla swojego nowego klastra, w przeciwnym razie ClusterControl przypisze Ci ogólną.
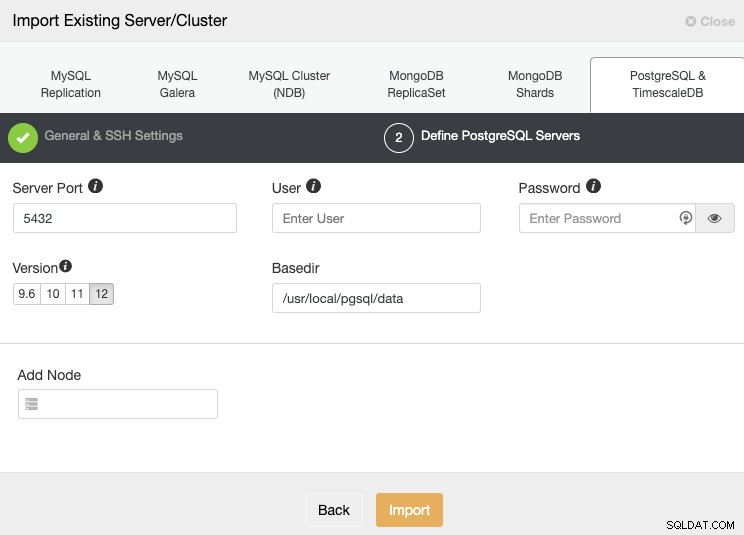
Po skonfigurowaniu informacji dostępowych SSH należy zdefiniować poświadczenia bazy danych, wersja, basedir i adres IP lub nazwa hosta dla każdego węzła bazy danych.
Jeśli nie masz jeszcze skonfigurowanej replikacji, wystarczy dodać adres IP lub nazwę hosta dla węzła podstawowego, ponieważ później pokażemy, jak dodać pozostałe węzły.
Upewnij się, że podczas wprowadzania nazwy hosta lub adresu IP wyświetlany jest zielony haczyk, co oznacza, że ClusterControl może komunikować się z węzłem. Następnie kliknij przycisk Importuj i poczekaj, aż ClusterControl zakończy swoje zadanie. Możesz monitorować proces w sekcji Aktywność ClusterControl. Po zakończeniu zobaczysz nowy klaster na głównym ekranie ClusterControl. Aby dodać nową replikę, przejdź do działań klastra i wybierz opcję „Dodaj podrzędną replikację”.
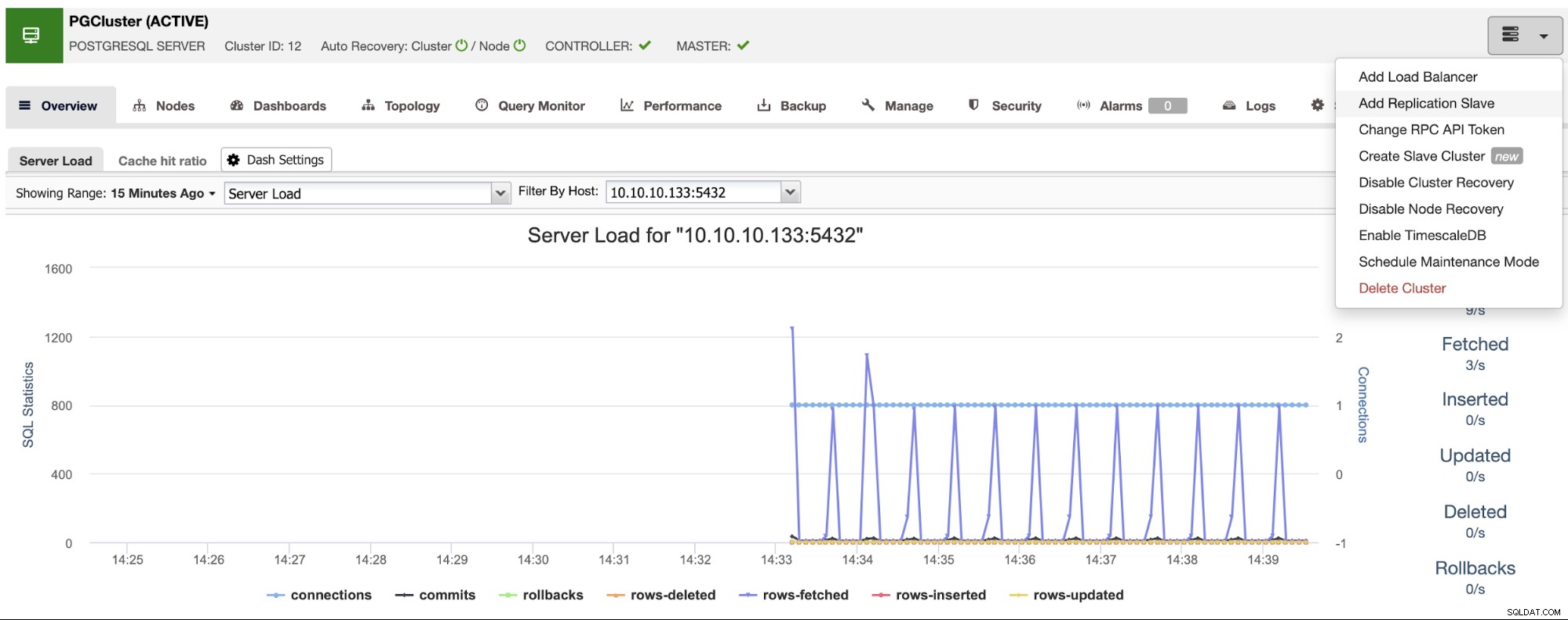
Jeśli wykonałeś poprzednie kroki, będziesz mieć zainstalowany Percona Distribution dla PostgreSQL we wszystkich węzłach gotowości, więc musisz wyłączyć „Zainstaluj oprogramowanie PostgreSQL” w tej sekcji.
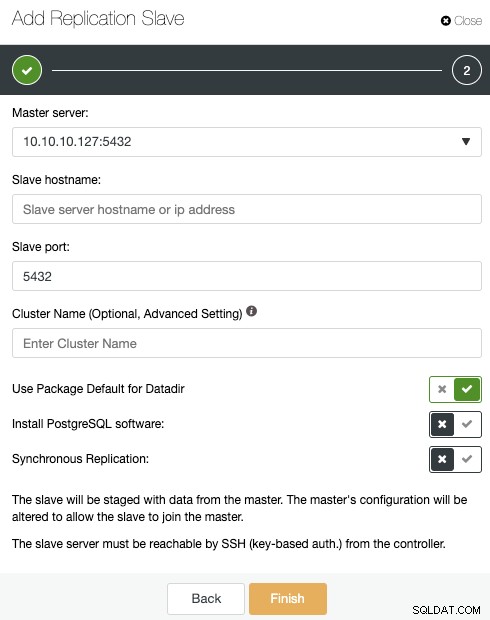
W ten sposób ClusterControl użyje zainstalowanych pakietów Percona Distribution for PostgreSQL instalacji oficjalnych pakietów PostgreSQL.
Kiedy to skończysz, zobaczysz wszystkie węzły w klastrze i ich status w sekcji przeglądu.
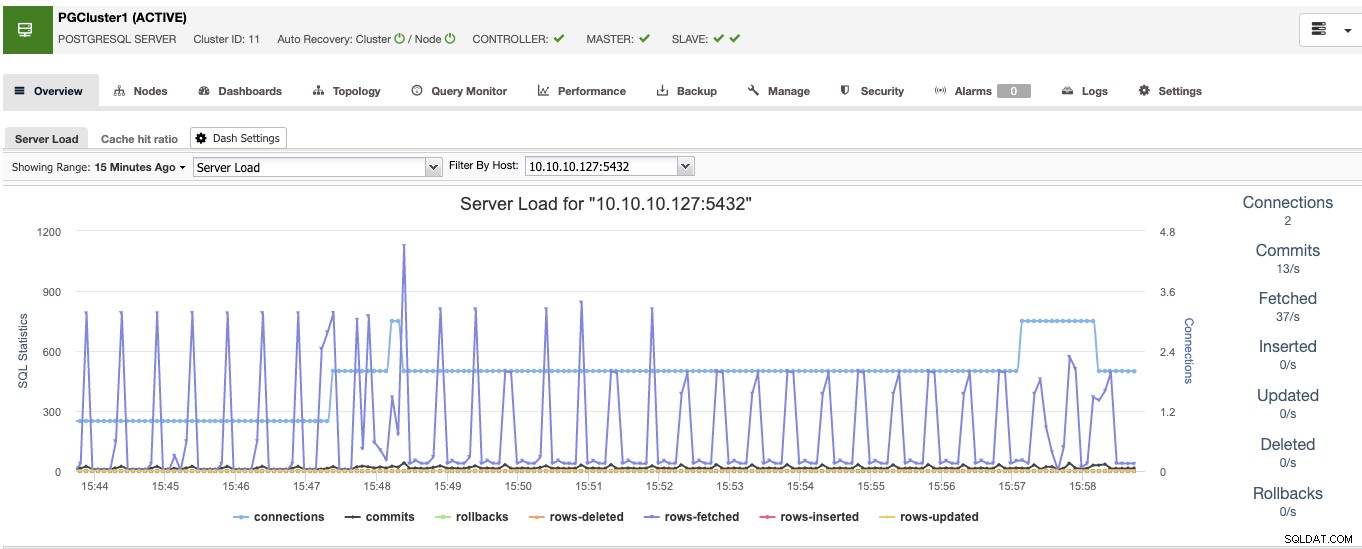
Teraz masz przygotowaną stronę bazy danych, zobaczmy, jak ukończyć Dostępność środowiska poprzez dodanie pozostałych narzędzi za pomocą ClusterControl.
Wdrażanie systemu równoważenia obciążenia
Aby przeprowadzić wdrożenie load balancera, wybierz opcję „Dodaj Load Balancer” w akcjach klastra i wypełnij wymagane informacje. 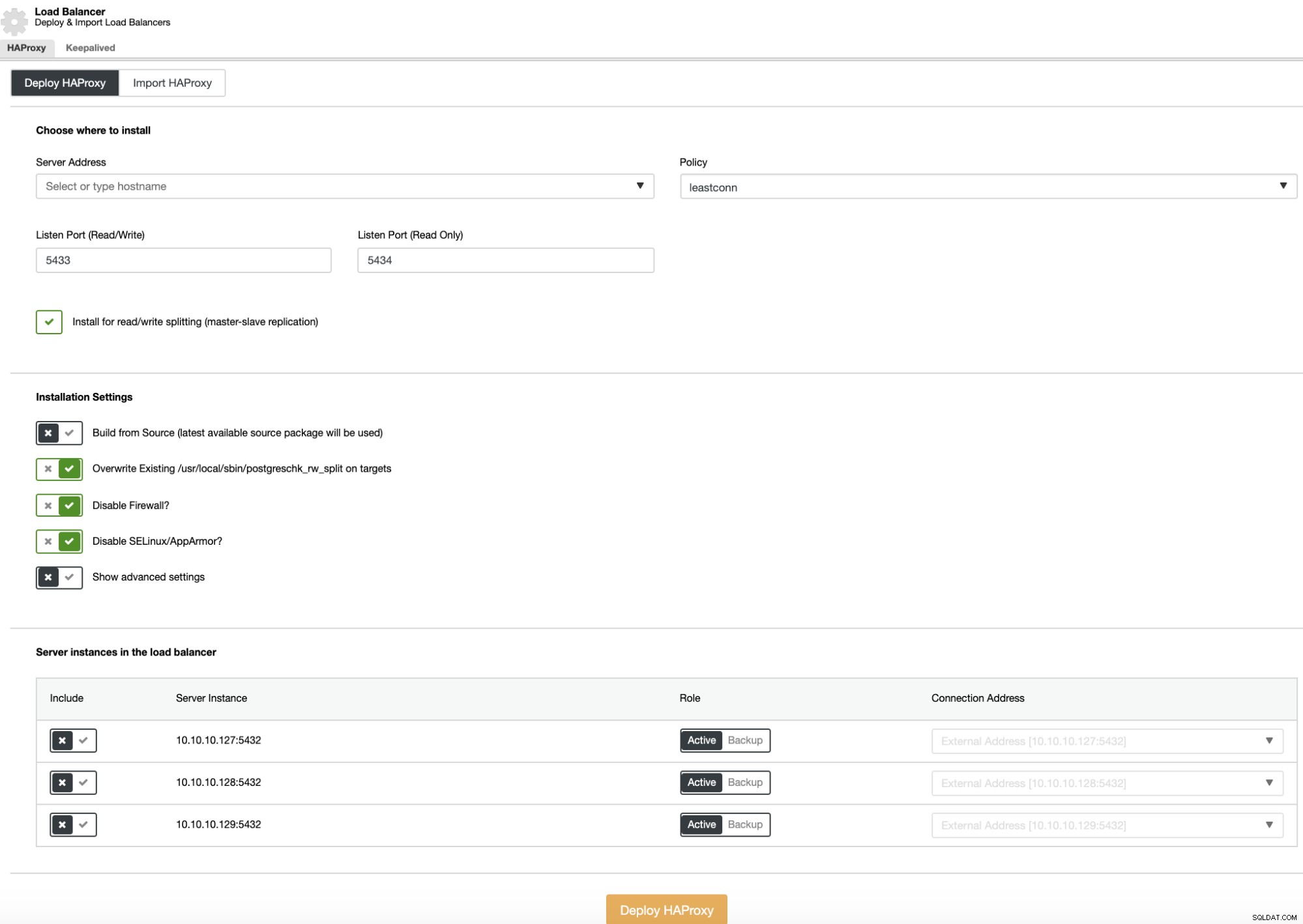
Wystarczy dodać adres IP lub nazwę hosta, port, zasady i węzły, które zamierzasz dodać do konfiguracji równoważenia obciążenia.
Utrzymywane wdrażanie
Aby przeprowadzić wdrożenie Keepalved, wybierz klaster, przejdź do działań klastra, wybierz „Dodaj Load Balancer”, a następnie przejdź do sekcji „Keepalived”.
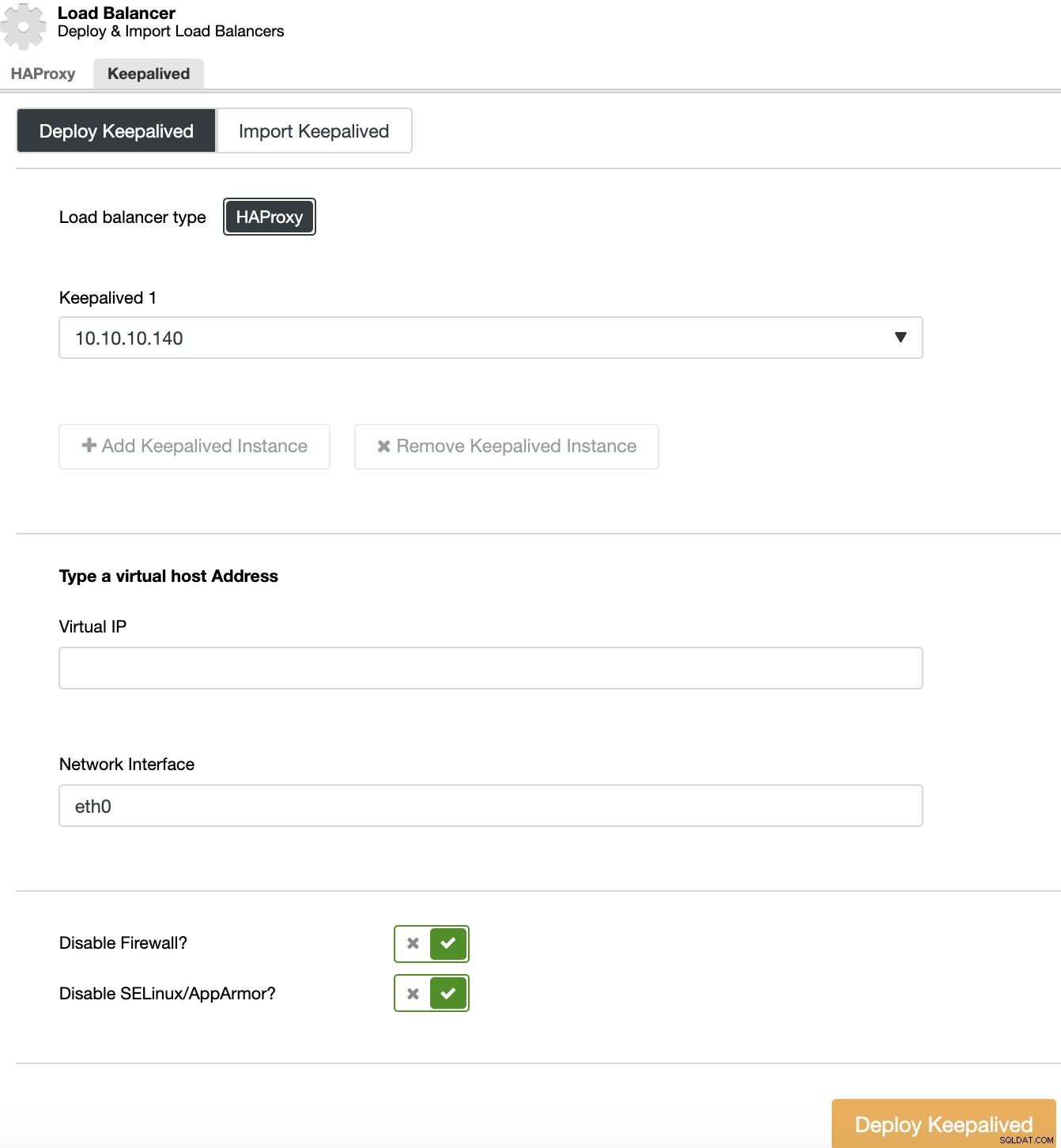
Dla środowiska wysokiej dostępności musisz wybrać serwery równoważenia obciążenia i wirtualny adres IP, których będziesz potrzebować, aby uzyskać dostęp do klastra. Keepalived konfiguruje ten wirtualny adres IP w aktywnym systemie równoważenia obciążenia i migruje go z jednego systemu równoważenia obciążenia do drugiego w przypadku awarii, dzięki czemu konfiguracja może nadal działać normalnie.
Wnioski
Ponieważ nie można jeszcze wdrożyć Percona Distribution for PostgreSQL bezpośrednio z ClusterControl, w tym blogu pokazaliśmy, jak zarządzać nią za pomocą ClusterControl oraz jak dodawać różne narzędzia, takie jak HAProxy i Keepalved, aby mieć środowisko wysokiej dostępności w łatwy sposób.