Wystarczy trochę podrasować i ulepszyć zapytania Postgres SQL, aby zmniejszyć ilość powtarzającego się, podatnego na błędy kodu aplikacji wymaganego do połączenia z bazą danych. Częściej nie, taka zmiana poprawia również wydajność kodu aplikacji.
Oto kilka wskazówek i trików, które mogą pomóc Twojej aplikacji w zleceniu większej ilości pracy PostgreSQL oraz sprawić, że Twoja aplikacja będzie cieńsza i szybsza.
Przejdź
Od wersji 9.5 Postgresa można określić, co ma się stać, gdy wstawienie nie powiedzie się z powodu „konfliktu”. Konflikt może być naruszeniem unikalnego indeksu (w tym klucza podstawowego) lub dowolnego ograniczenia (utworzonego wcześniej przy użyciu narzędzia CREATE CONSTRAINT).
Ta funkcja może być wykorzystana do uproszczenia logiki wstawiania lub aktualizowania aplikacji do pojedynczej instrukcji SQL. Na przykład, mając podaną tabelę kv z kluczem i wartość kolumn, poniższe oświadczenie wstawi nowy wiersz (jeśli tabela nie ma wiersza z kluczem='host') lub zaktualizuje wartość (jeśli tabela ma wiersz z kluczem='host'):
CREATE TABLE kv (key TEXT PRIMARY KEY, value TEXT);
INSERT INTO kv (key, value)
VALUES ('host', '10.0.10.1')
ON CONFLICT (key) DO UPDATE SET value=EXCLUDED.value;
Zwróć uwagę, że kolumna key jest jednokolumnowym kluczem podstawowym tabeli i jest określony jako klauzula konfliktu. Jeśli masz klucz podstawowy z wieloma kolumnami, zamiast tego podaj nazwę indeksu klucza podstawowego.
Zaawansowane przykłady, w tym określanie częściowych indeksów i ograniczeń, można znaleźć w dokumentacji Postgres.
Wstaw .. powracający
Instrukcja INSERT może również zwrócić jeden lub więcej wierszy, takich jak instrukcja SELECT. Może zwracać wartości generowane przez funkcje, słowa kluczowe, takie jak current_timestamp i seryjny /sequence/identity kolumn.
Na przykład tutaj jest tabela z automatycznie wygenerowaną kolumną tożsamości i kolumną, która zawiera znacznik czasu utworzenia wiersza:
db=> CREATE TABLE t1 (id int GENERATED BY DEFAULT AS IDENTITY,
db(> at timestamptz DEFAULT CURRENT_TIMESTAMP,
db(> foo text);
Możemy użyć instrukcji INSERT .. RETURNING, aby określić tylko wartość dla kolumny foo i niech Postgres zwróci wartości, które wygenerował dla id i o kolumny:
db=> INSERT INTO t1 (foo) VALUES ('first'), ('second') RETURNING id, at, foo;
id | at | foo
----+----------------------------------+--------
1 | 2022-01-14 11:52:09.816787+01:00 | first
2 | 2022-01-14 11:52:09.816787+01:00 | second
(2 rows)
INSERT 0 2
W kodzie aplikacji użyj tych samych wzorców/interfejsów API, których używasz do uruchamiania instrukcji SELECT i wczytywania wartości (takich jak executeQuery() w JDBC lub db.Query() w Go).
Oto kolejny przykład, ten ma automatycznie wygenerowany UUID:
CREATE TABLE t2 (id uuid PRIMARY KEY, foo text);
INSERT INTO t2 (id, foo) VALUES (gen_random_uuid(), ?) RETURNING id;
Podobnie jak INSERT, instrukcje UPDATE i DELETE mogą również zawierać klauzule RETURNING w Postgresie. Klauzula RETURNING jest rozszerzeniem Postgres i nie jest częścią standardu SQL.
Dowolny w zestawie
Jak na podstawie kodu aplikacji utworzyć klauzulę WHERE, która musi dopasować wartość kolumny do zestawu akceptowalnych wartości? Gdy liczba wartości jest znana wcześniej, SQL jest statyczny:
stmt = conn.prepareStatement("SELECT key, value FROM kv WHERE key IN (?, ?)");
stmt.setString(1, key[0]);
stmt.setString(2, key[1]);
Ale co, jeśli liczba kluczy nie wynosi 2, ale może być dowolną liczbą? Czy skonstruowałbyś instrukcję SQL dynamicznie? Łatwiejszą opcją jest użycie tablic Postgres:
SELECT key, value FROM kv WHERE key = ANY(?)
Powyższy operator ANY przyjmuje tablicę jako argument. Klauzula klucz =DOWOLNY(?) zaznacza wszystkie wiersze, w których wartość klucza jest jednym z elementów dostarczonej tablicy. Dzięki temu kod aplikacji można uprościć do:
stmt = conn.prepareStatement("SELECT key, value FROM kv WHERE key = ANY(?)");
a = conn.createArrayOf("STRING", keys);
stmt.setArray(1, a);
Takie podejście jest możliwe dla ograniczonej liczby wartości, jeśli masz wiele wartości do dopasowania, rozważ inne opcje, takie jak łączenie z (tymczasowymi) tabelami lub widokami zmaterializowanymi.
Przenoszenie wierszy między tabelami
Tak, możesz usunąć wiersze z jednej tabeli i wstawić je do innej za pomocą jednej instrukcji SQL! Główna instrukcja INSERT może pobierać wiersze do wstawienia za pomocą CTE, które otacza DELETE.
WITH items AS (
DELETE FROM todos_2021
WHERE NOT done
RETURNING *
)
INSERT INTO todos_2021 SELECT * FROM items;
Wykonanie równoważnika w kodzie aplikacji może być bardzo szczegółowe, obejmujące przechowywanie całego wyniku usunięcia w pamięci i używanie go do wykonywania wielu operacji INSERT. To prawda, że przenoszenie wierszy może nie jest powszechnym przypadkiem użycia, ale jeśli wymaga tego logika biznesowa, oszczędność pamięci aplikacji i objazdy bazy danych, jakie zapewnia to podejście, sprawiają, że jest to idealne rozwiązanie.
Zestaw kolumn w tabeli źródłowej i docelowej nie musi być identyczny, możesz oczywiście zmienić kolejność, zmienić kolejność i użyć funkcji do manipulowania wartościami na listach wyboru/zwracania.
Połącz
Przekazanie wartości NULL w kodzie aplikacji zwykle wymaga dodatkowych kroków. Na przykład w Go musisz używać typów takich jak sql.NullString; w Javie/JDBC działa jak resultSet.wasNull() . Są kłopotliwe i podatne na błędy.
Jeśli można obsłużyć, powiedzmy NULL jako puste ciągi lub liczby całkowite NULL jako 0, w kontekście konkretnego zapytania można użyć funkcji COALESCE. Funkcja COALESCE może zamienić wartości NULL na dowolną konkretną wartość. Rozważmy na przykład to zapytanie:
SELECT invoice_num, COALESCE(shipping_address, '')
FROM invoices
WHERE EXTRACT(month FROM raised_on) = 1 AND
EXTRACT(year FROM raised_on) = 2022
który pobiera numery faktur i adresy wysyłkowe faktur wystawionych w styczniu 2022 r. Przypuszczalnie adres_wysyłki jest NULL, jeśli towary nie muszą być wysyłane fizycznie. Jeśli kod aplikacji po prostu chce wyświetlić gdzieś pusty ciąg w takich przypadkach, powiedzmy, prościej jest po prostu użyć COALESCE i usunąć kod obsługujący NULL z aplikacji.
Możesz także użyć innych ciągów zamiast pustego ciągu:
SELECT invoice_num, COALESCE(shipping_address, '* NOT SPECIFIED *') ...
Możesz nawet uzyskać pierwszą wartość inną niż NULL z listy lub zamiast tego użyć określonego ciągu. Na przykład, aby użyć adresu rozliczeniowego lub adresu wysyłki, możesz użyć:
SELECT invoice_num, COALESCE(billing_address, shipping_address, '* NO ADDRESS GIVEN *') ...
Sprawa
CASE to kolejna pomocna konstrukcja do radzenia sobie z rzeczywistymi, niedoskonałymi danymi. Powiedzmy, że zamiast mieć NULL w adresie_wysyłki w przypadku przedmiotów, których nie można wysłać, nasze niezbyt doskonałe oprogramowanie do tworzenia faktur umieściło opcję „NIE OKREŚLONO”. Chciałbyś zmapować to na NULL lub pusty ciąg podczas wczytywania danych. Możesz użyć CASE:
-- map NOT-SPECIFIED to an empty string
SELECT invoice_num,
CASE shipping_address
WHEN 'NOT-SPECIFIED' THEN ''
ELSE shipping_address
END
FROM invoices;
-- same result, different syntax
SELECT invoice_num,
CASE
WHEN shipping_address = 'NOT-SPECIFIED' THEN ''
ELSE shipping_address
END
FROM invoices;
CASE ma niezgrabną składnię, ale jest funkcjonalnie podobny do instrukcji switch-case w językach podobnych do C. Oto kolejny przykład:
SELECT invoice_num,
CASE
WHEN shipping_address IS NULL THEN 'NOT SHIPPING'
WHEN billing_address = shipping_address THEN 'SHIPPING TO PAYER'
ELSE 'SHIPPING TO ' || shipping_address
END
FROM invoices;
Wybierz .. union
Dane z dwóch (lub więcej) oddzielnych instrukcji SELECT można łączyć za pomocą UNION. Na przykład, jeśli masz dwie tabele, jedną zawierającą aktualnych użytkowników, a drugą usuniętą, oto jak wysyłać zapytania do obu jednocześnie:
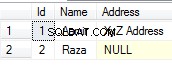
SELECT id, name, address, FALSE AS is_deleted
FROM users
WHERE email = ?
UNION
SELECT id, name, address, TRUE AS is_deleted
FROM deleted_users
WHERE email = ?
Dwa zapytania powinny mieć tę samą listę wyboru, to znaczy powinny zwracać tę samą liczbę i typ kolumn.
UNION usuwa również duplikaty. Zwracane są tylko unikalne wiersze. Jeśli wolisz zachować zduplikowane wiersze, użyj „UNION ALL” zamiast UNION.
Uzupełnieniem UNION jest również INTERSECT i EXCEPT, zobacz dokumentację PostgreSQL, aby uzyskać więcej informacji.
Wybierz .. odrębne na
Zduplikowane wiersze zwracane przez SELECT można łączyć (tzn. zwracane są tylko unikatowe wiersze), dodając słowo kluczowe DISTINCT po SELECT. Chociaż jest to standardowy SQL, Postgres udostępnia rozszerzenie „DISTINCT ON”. Jest to trochę trudne w użyciu, ale w praktyce jest to często najbardziej zwięzły sposób na uzyskanie potrzebnych wyników.
Rozważ klientów tabela z wierszem na klienta i zakupami tabela z jednym wierszem na zakupy dokonywane przez (niektórych) klientów. Poniższe zapytanie zwraca wszystkich klientów wraz z każdym z ich zakupów:
SELECT C.id, P.at
FROM customers C LEFT OUTER JOIN purchases P ON P.customer_id = C.id
ORDER BY C.id ASC, P.at ASC;
Każdy wiersz klienta jest powtarzany dla każdego dokonanego przez niego zakupu. Co jeśli chcemy zwrócić tylko pierwszy zakup klienta? Zasadniczo chcemy posortować wiersze według klientów, pogrupować wiersze według klientów, w każdej grupie posortować wiersze według czasu zakupu, a na koniec zwrócić tylko pierwszy wiersz z każdej grupy. Właściwie jest krócej napisać to w SQL z DISTINCT ON:
SELECT DISTINCT ON (C.id) C.id, P.at
FROM customers C LEFT OUTER JOIN purchases P ON P.customer_id = C.id
ORDER BY C.id ASC, P.at ASC;
Dodana klauzula „DISTINCT ON (C.id)” robi dokładnie to, co opisano powyżej. To dużo pracy z kilkoma dodatkowymi literami!
Używanie liczb w kolejności według klauzuli
Rozważ pobranie z tabeli listy nazwisk klientów i numerów kierunkowych ich numerów telefonów. Zakładamy, że numery telefonów w USA są przechowywane w formacie (123) 456-7890 . W przypadku innych krajów jako numer kierunkowy powiemy „POZA USA”.
SELECT last_name, first_name,
CASE country_code
WHEN 'US' THEN substr(phone, 2, 3)
ELSE 'NON-US'
END
FROM customers;
To wszystko w porządku i mamy też konstrukcję CASE, ale co, jeśli musimy teraz posortować ją według numeru kierunkowego?
To działa:
SELECT last_name, first_name,
CASE country_code
WHEN 'US' THEN substr(phone, 2, 3)
ELSE 'NON-US'
END
FROM customers
ORDER BY
CASE country_code
WHEN 'US' THEN substr(phone, 2, 3)
ELSE 'NON-US'
END ASC;
Ale ugh! Powtarzanie klauzuli case jest brzydkie i podatne na błędy. Moglibyśmy napisać zapisaną funkcję, która pobiera kod kraju i telefon oraz zwraca numer kierunkowy, ale w rzeczywistości jest ładniejsza opcja:
SELECT last_name, first_name,
CASE country_code
WHEN 'US' THEN substr(phone, 2, 3)
ELSE 'NON-US'
END
FROM customers
ORDER BY 3 ASC;
„ORDER BY 3” oznacza kolejność według trzeciego pola! Musisz pamiętać, aby zaktualizować numer, gdy zmieniasz kolejność listy wyboru, ale zwykle warto.