W poprzednim poście na blogu pokrótce wyjaśniłem, w jaki sposób otrzymaliśmy liczby wydajności opublikowane w ogłoszeniu pglogicznym. W tym poście na blogu chciałbym omówić ogólnie ograniczenia wydajności rozwiązań replikacji logicznej, a także ich zastosowanie do pgLogic.
replikacja fizyczna
Najpierw zobaczmy, jak działa replikacja fizyczna (wbudowana w PostgreSQL od wersji 9.0). Nieco uproszczona postać z dwoma zaledwie dwoma węzłami wygląda tak:
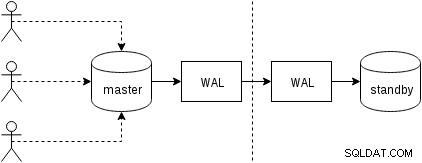
Klienci wykonują zapytania w węźle głównym, zmiany są zapisywane w dzienniku transakcji (WAL) i kopiowane przez sieć do WAL w węźle rezerwowym. Proces odzyskiwania w trybie gotowości w trybie gotowości odczytuje następnie zmiany z WAL i stosuje je do plików danych, tak jak podczas odzyskiwania. Jeśli tryb gotowości jest w trybie „hot_standby”, klienci mogą wysyłać zapytania tylko do odczytu w węźle, gdy to się dzieje.
Jest to bardzo wydajne, ponieważ jest bardzo mało dodatkowego przetwarzania — zmiany są przesyłane i zapisywane w trybie gotowości jako nieprzezroczysty binarny obiekt blob. Oczywiście odzyskiwanie nie jest bezpłatne (zarówno pod względem procesora, jak i we/wy), ale trudno jest uzyskać bardziej wydajne niż to.
Oczywistymi potencjalnymi wąskimi gardłami w przypadku replikacji fizycznej są przepustowość sieci (przenoszenie warstwy WAL z urządzenia nadrzędnego do gotowości), a także operacje we/wy w trybie gotowości, które mogą być nasycone przez proces odzyskiwania, który często generuje wiele losowych żądań we/wy ( w niektórych przypadkach bardziej niż mistrz, ale nie zagłębiajmy się w to).
replikacja logiczna
Replikacja logiczna jest nieco bardziej skomplikowana, ponieważ nie zajmuje się nieprzezroczystym binarnym strumieniem WAL, ale strumieniem „logicznych” zmian (wyobraźmy sobie instrukcje INSERT, UPDATE lub DELETE, chociaż nie jest to całkowicie poprawne, ponieważ mamy do czynienia ze strukturalną reprezentacją dane). Posiadanie zmian logicznych pozwala robić interesujące rzeczy, takie jak rozwiązywanie konfliktów, replikowanie tylko wybranych tabel, do innego schematu lub między różnymi wersjami (lub nawet różnymi bazami danych).
Istnieją różne sposoby uzyskania zmian — tradycyjne podejście polega na użyciu wyzwalaczy rejestrujących zmiany w tabeli i umożliwianie procesowi niestandardowemu ciągłe odczytywanie tych zmian i stosowanie ich w trybie gotowości poprzez uruchamianie zapytań SQL. A wszystko to jest sterowane przez zewnętrzny proces demona (lub prawdopodobnie wiele procesów działających na obu węzłach), jak pokazano na następnym rysunku

To właśnie robią slony lub londiste i chociaż działało to całkiem dobrze, oznacza to duże obciążenie – na przykład wymaga przechwytywania zmian danych i wielokrotnego zapisywania danych (do oryginalnej tabeli i do tabeli „log”, a również do WAL dla obu tych tabel). Inne źródła kosztów ogólnych omówimy później. Chociaż pglogical musi osiągnąć te same cele, osiąga je w inny sposób, dzięki kilku funkcjom dodanym do ostatnich wersji PostgreSQL (a więc niedostępnych w czasie wdrażania innych narzędzi):

Oznacza to, że zamiast utrzymywać osobny log zmian, pglogical opiera się na WAL – jest to możliwe dzięki logicznemu dekodowaniu dostępnemu w PostgreSQL 9.4, które pozwala na wyodrębnienie logicznych zmian z logu WAL. Dzięki temu pglogical nie potrzebuje żadnych kosztownych wyzwalaczy i zazwyczaj może uniknąć dwukrotnego zapisywania danych na master (z wyjątkiem dużych transakcji, które mogą rozlać się na dysk).
Po zdekodowaniu każdej transakcji jest ona przekazywana do rezerwowej bazy danych, a proces wprowadzania wprowadza jej zmiany do rezerwowej bazy danych. pglogical nie stosuje zmian, uruchamiając zwykłe zapytania SQL, ale na niższym poziomie, omijając narzut związany z analizowaniem i planowaniem zapytań SQL. Daje to pglogical znaczną przewagę nad istniejącymi rozwiązaniami, które wszystkie przechodzą przez warstwę SQL (a tym samym opłaca się analizowanie i planowanie).
potencjalne wąskie gardła
Oczywiście replikacja logiczna jest podatna na te same wąskie gardła, co replikacja fizyczna, tj. możliwe jest nasycenie sieci podczas przesyłania zmian oraz we/wy w trybie gotowości podczas ich stosowania w trybie gotowości. Istnieje również spora ilość narzutu z powodu dodatkowych kroków, których nie ma w fizycznej replikacji.
Musimy w jakiś sposób zebrać zmiany logiczne, podczas gdy fizyczna replikacja po prostu przekazuje WAL jako strumień bajtów. Jak już wspomniano, istniejące rozwiązania zwykle opierają się na wyzwalaczach zapisujących zmiany w tabeli „log”. pglogical zamiast tego opiera się na dzienniku zapisu z wyprzedzeniem (WAL) i logicznym dekodowaniu, aby osiągnąć to samo, co jest tańsze niż wyzwalacze, a także w większości przypadków nie wymaga dwukrotnego zapisywania danych (z dodatkową premią, że automatycznie stosujemy zmiany w kolejności zatwierdzenia).
Nie oznacza to, że nie ma możliwości dodatkowej poprawy — na przykład dekodowanie odbywa się obecnie dopiero po zatwierdzeniu transakcji, więc w przypadku dużych transakcji może to zwiększyć opóźnienie replikacji. Replikacja fizyczna po prostu przesyła strumieniowo zmiany WAL do drugiego węzła, a zatem nie ma tego ograniczenia. Duże transakcje mogą również rozlać się na dysk, powodując zduplikowane zapisy, ponieważ nadrzędny musi je przechowywać do momentu zatwierdzenia i można je wysłać do dalszego.
Planowane są przyszłe prace, które pozwolą pglogical rozpocząć przesyłanie strumieniowe dużych transakcji, podczas gdy są one nadal w toku, w sieci nadrzędnej, zmniejszając opóźnienie między zatwierdzaniem wstępnym i podrzędnym oraz redukując wzmocnienie zapisu nadrzędnego.
Po przeniesieniu zmian do stanu gotowości proces aplikacyjny musi je jakoś zastosować. Jak wspomniano w poprzedniej sekcji, istniejące rozwiązania zrobiły to, konstruując i wykonując polecenia SQL, podczas gdy pglogical całkowicie omija warstwę SQL i związane z nią obciążenie.
Nie oznacza to jednak, że aplikacja jest całkowicie darmowa, ponieważ nadal musi wykonywać takie czynności, jak wyszukiwanie klucza podstawowego, aktualizowanie indeksów, wykonywanie wyzwalaczy i wykonywanie różnych innych kontroli. Ale jest znacznie tańszy niż podejście oparte na SQL. W pewnym sensie działa podobnie jak COPY i jest szczególnie szybki w przypadku prostych tabel bez wyzwalaczy, kluczy obcych itp.
We wszystkich rozwiązaniach replikacji logicznej każdy z tych kroków (dekodowanie i zastosowanie) odbywa się w jednym procesie, więc czas procesora jest dość ograniczony. Jest to prawdopodobnie najbardziej palące wąskie gardło we wszystkich istniejących rozwiązaniach, ponieważ możesz mieć dość rozbudowaną maszynę z dziesiątkami, a nawet setkami klientów wykonujących równolegle zapytania, ale wszystko to musi przejść przez jeden proces dekodowania tych zmian (na master) i jeden proces stosujący te zmiany (w trybie gotowości).
Ograniczenie „pojedynczego procesu” można nieco złagodzić, używając oddzielnych baz danych, ponieważ każda baza danych jest obsługiwana przez oddzielny proces. Jeśli chodzi o pojedynczą bazę danych, planowane są przyszłe prace mające na celu równoległe zastosowanie za pośrednictwem puli pracowników działających w tle, aby złagodzić to wąskie gardło.