Chociaż w przyszłości większość serwerów bazodanowych (szczególnie tych obsługujących obciążenia podobne do OLTP) będzie korzystać z pamięci masowej opartej na pamięci flash, to jeszcze nie jesteśmy – pamięć flash jest nadal znacznie droższa niż tradycyjne dyski twarde, a wiele systemów korzysta z kombinacji dysków SSD i HDD. Oznacza to jednak, że musimy zdecydować, jak podzielić bazę danych – co powinno trafić na wirującą rdze (HDD) i co jest dobrym kandydatem na pamięć flash, która jest droższa, ale znacznie lepiej radzi sobie z przypadkowymi operacjami we/wy.
Istnieją rozwiązania, które próbują obsłużyć to automatycznie na poziomie pamięci masowej, automatycznie wykorzystując dyski SSD jako pamięć podręczną, automatycznie zachowując aktywną część danych na dysku SSD. Urządzenia pamięci masowej / SAN często robią to wewnętrznie, są hybrydowe dyski SATA/SAS z dużym dyskiem HDD i małym dyskiem SSD w jednym pakiecie i oczywiście są rozwiązania, które pozwalają to zrobić bezpośrednio na hoście – na przykład pamięć podręczna dm w Linuksie, LVM również otrzymał taką możliwość (zbudowaną na bazie dm-cache) w 2014 roku i oczywiście ZFS ma L2ARC.
Ale zignorujmy wszystkie te automatyczne opcje i powiedzmy, że mamy dwa urządzenia podłączone bezpośrednio do systemu – jedno oparte na dyskach twardych, drugie oparte na flashu. Jak podzielić bazę danych, aby uzyskać jak najwięcej korzyści z drogiego flasha? Jednym z powszechnie używanych wzorców jest robienie tego według typu obiektu, w szczególności tabel i indeksów. Ogólnie rzecz biorąc, ma to sens, ale często widzimy ludzi umieszczających indeksy w pamięci SSD, ponieważ indeksy są powiązane z losowymi operacjami we/wy. Chociaż może się to wydawać rozsądne, okazuje się, że jest to dokładnie przeciwieństwo tego, co powinieneś robić.
Pozwólcie, że pokażę wam test porównawczy…
Pozwólcie, że zademonstruję to na systemie z pamięcią masową HDD (RAID10 zbudowany z 4 dysków SAS 10 tys.) i pojedynczym urządzeniem SSD (Intel S3700). System ma 16 GB RAM, więc użyjmy pgbencha z wagami 300 (=4,5 GB) i 3000 (=45 GB), czyli takiego, który bez problemu mieści się w RAM i wielokrotności RAM. Następnie umieśćmy tabele i indeksy w różnych systemach pamięci masowej (za pomocą obszarów tabel) i zmierzmy wydajność. Klaster bazy danych został odpowiednio skonfigurowany (współdzielone bufory, limity WAL itp.) pod względem zasobów sprzętowych. WAL został umieszczony na oddzielnym urządzeniu SSD, podłączonym do kontrolera RAID współdzielonego z dyskami SAS.
Na małym (4,5 GB) zestawie danych wyniki wyglądają tak (zauważ, że oś y zaczyna się od 3000 tps):
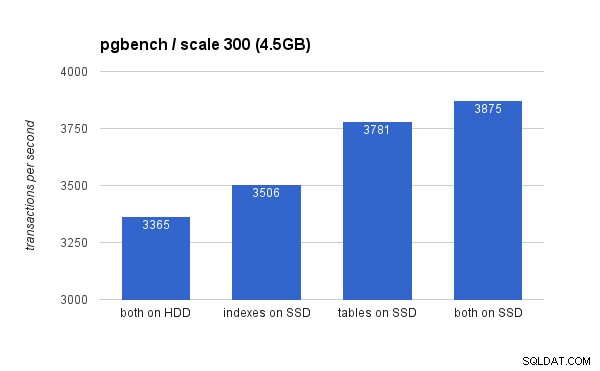
Oczywiście umieszczenie indeksów na dysku SSD daje mniejsze korzyści w porównaniu z używaniem dysku SSD do tworzenia tabel. Chociaż zestaw danych łatwo mieści się w pamięci RAM, zmiany muszą w końcu zostać zapisane na dysku, a chociaż kontroler RAID ma pamięć podręczną zapisu, tak naprawdę nie może konkurować z pamięcią flash. Nowe kontrolery RAID prawdopodobnie działałyby nieco lepiej, podobnie jak nowe dyski SSD.
Na dużym zestawie danych różnice są znacznie bardziej znaczące (tym razem oś y zaczyna się od 0):
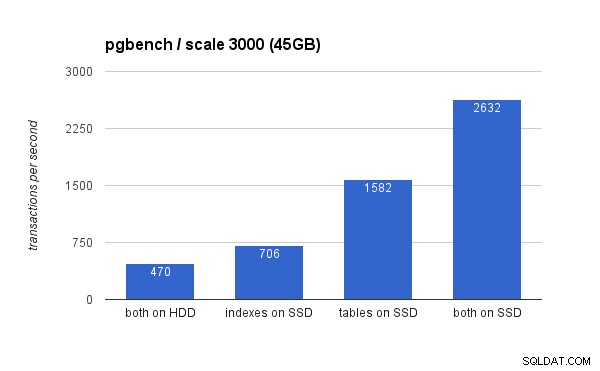
Umieszczenie indeksów na dysku SSD powoduje znaczny wzrost wydajności (prawie 50%, biorąc za punkt odniesienia pamięć HDD), ale przeniesienie tabel na dysk SSD z łatwością pokonuje ten wynik, zyskując ponad 200%. Oczywiście, jeśli umieścisz zarówno tabele, jak i indeks na dyskach SSD, uzyskasz dalszą poprawę wydajności – ale jeśli możesz to zrobić, nie musisz się martwić o inne przypadki.
Ale dlaczego?
Uzyskanie lepszej wydajności z umieszczania tabel na dyskach SSD może wydawać się nieco sprzeczne z intuicją, więc dlaczego tak się zachowuje? Cóż, prawdopodobnie jest to kombinacja kilku czynników:
- indeksy są zwykle znacznie mniejsze niż tabele, dzięki czemu łatwiej mieszczą się w pamięci
- strony w poziomach indeksów (w drzewie) są zwykle dość gorące i dlatego pozostają w pamięci
- podczas skanowania i indeksowania wiele rzeczywistych operacji we/wy ma charakter sekwencyjny (szczególnie w przypadku stron liści)
Konsekwencją tego jest to, że zaskakująca ilość operacji we/wy w stosunku do indeksów albo nie występuje w ogóle (dzięki buforowaniu), albo jest sekwencyjna. Z drugiej strony indeksy są doskonałym źródłem losowych operacji we/wy w tabelach.
Jest to bardziej skomplikowane, chociaż…
Oczywiście był to tylko prosty przykład i na przykład wnioski mogą być różne w przypadku znacznie różnych obciążeń. Podobnie, ponieważ dyski SSD są droższe, systemy mają zwykle więcej miejsca na dyskach HDD niż na dyskach SSD, więc tabele mogą nie zmieścić się na dysku SSD, podczas gdy indeksy tak. W takich przypadkach konieczne jest bardziej rozbudowane rozmieszczenie – na przykład biorąc pod uwagę nie tylko rodzaj obiektu, ale także to, jak często jest on używany (i tylko przenoszenie intensywnie używanych tabel na dyski SSD), a nawet podzbiory tabel (np. poprzez stopniowe przenoszenie starych dane z dysku SSD na dysk twardy).