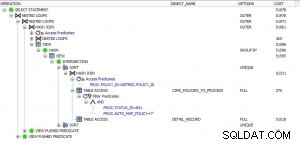
Jest tylko kilka rzeczy, które pomogą w tym zapytaniu:
-
Samo skanowanie nie wydaje się być problemem (zajęło 42 sekundy), ale gdyby tabelę można było przechowywać w pamięci RAM, mogłoby to być szybsze.
-
Twoim głównym problemem jest rodzaj, który PostgreSQL już zrównoleglał.
Jest kilka rzeczy, które możesz dostroić:
-
Zwiększ
work_memjak najwięcej, co przyspieszy sortowanie. -
Zwiększ
max_worker_processes(będzie to wymagało ponownego uruchomienia),max_parallel_workersimax_parallel_workers_per_gatheraby więcej rdzeni mogło być użytych w zapytaniu.PostgreSQL ma wewnętrzną logikę obliczania maksymalnej liczby równoległych procesów roboczych, których jest gotowy do użycia dla tabeli:uwzględni tyle równoległych procesów roboczych, ile
log3 (rozmiar tabeli /
min_parallel_table_scan_size)Możesz zmusić go do użycia większej liczby procesów za pomocą:
ALTER TABLE ohlcv SET (parallel_workers = 20);Ale
max_parallel_workersnadal jest górną granicą.
-
Jeśli w tabeli nie ma żadnych usunięć ani aktualizacji, a dane są wstawiane w kolejności sortowania, możesz po prostu pominąć ORDER BY klauzula, pod warunkiem, że ustawisz synchronize_seqscans = off .