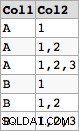
Nazwy kolumn są identyfikatorami, a krwawe szczegóły składni identyfikatorów są opisane w:
https://www.postgresql .org/docs/current/static/sql-syntax-lexical.html#SQL-SYNTAX-IDENTIFIERS
TL;DR :użyj U&"..." składnia do wstrzykiwania niedrukowalnych znaków do identyfikatorów poprzez ich punkty kodowe Unicode i nie ma możliwości ujednolicenia CR,LF z LF sam.
Jak odwołać się do kolumny w jednym wierszu
Możemy używać sekwencji ucieczki Unicode w identyfikatorach, więc zgodnie z dokumentacją działa:
select U&"first\000asecond" from Two;
jeśli to tylko znak nowej linii między dwoma słowami.
Co się dzieje z zapytaniami w pierwszej tabeli
Tabela jest tworzona za pomocą:
CREATE TABLE One("first\nsecond" text);
Ponieważ znak odwrotnego ukośnika nie ma tutaj specjalnego znaczenia, ta kolumna nie zawiera żadnej nowej linii. Zawiera first po którym następuje \ po którym następuje n po którym następuje second .Więc:
SELECT "first\nsecond" from One;
działa, ponieważ jest taki sam, jak w CREATE TABLE
podczas gdy
SELECT "first
second" from One;
kończy się niepowodzeniem, ponieważ w tym SELECT znajduje się nowy wiersz, w którym rzeczywista nazwa kolumny w tabeli zawiera ukośnik odwrotny, po którym następuje n .
Co się dzieje z zapytaniami w drugiej tabeli
To przeciwieństwo „Jeden”.
CREATE TABLE Two("first
second" text);
Nowa linia jest brana dosłownie i jest częścią kolumny.Więc
SELECT "first
second" from Two;
działa, ponieważ znak nowej linii znajduje się dokładnie tak, jak w CREATE TABLE, z osadzonym znakiem nowej linii, podczas gdy
SELECT "first\nsecond" from Two;
nie powiedzie się, ponieważ jak poprzednio \n w tym kontekście nie oznacza nowej linii.
Zwrot karetki, po którym następuje nowa linia lub cokolwiek dziwniejszego
Jak wspomniano w komentarzach i Twojej edycji, może to być powrót karetki i znak nowej linii, w takim przypadku powinno wystarczyć:
select U&"first\000d\000asecond" from Two;
chociaż w moim teście, wciśnięcie Enter w środku kolumny z psql w systemach Unix i Windows ma ten sam efekt:pojedynczy znak nowej linii w nazwie kolumny.
Aby sprawdzić, jakie dokładnie znaki znalazły się w nazwie kolumny, możemy sprawdzić je w systemie szesnastkowym.
Po zastosowaniu do przykładu tworzenia tabeli, z wnętrza psql pod Uniksem:
CREATE TABLE Two("first
second" text);
select convert_to(column_name::text,'UTF-8')
from information_schema.columns
where table_schema='public'
and table_name='two';
Wynik:
convert_to
----------------------------
\x66697273740a7365636f6e64
W bardziej złożonych przypadkach (np. znaki inne niż ASCII z kilkoma bajtami w UTF-8), bardziej zaawansowane zapytanie może pomóc, aby uzyskać łatwe do odczytania punkty kodowe:
select c,lpad(to_hex(ascii(c)),4,'0') from (
select regexp_split_to_table(column_name::text,'') as c
from information_schema.columns
where table_schema='public'
and table_name='two'
) as g;
c | lpad
---+------
f | 0066
i | 0069
r | 0072
s | 0073
t | 0074
+| 000a
|
s | 0073
e | 0065
c | 0063
o | 006f
n | 006e
d | 0064