Krok 1:Zwolnij hamulce ręczne
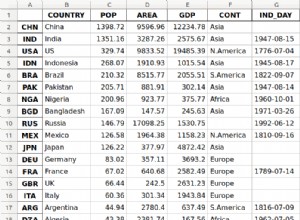
SELECT to_char(MIN(ts)::timestamptz, 'YYYY-MM-DD HH24:MI:SS TZ') AS min_time
,SUM(CASE WHEN sensor_id = 572 THEN value ELSE 0.0 END) AS nickname1
,SUM(CASE WHEN sensor_id = 542 THEN value ELSE 0.0 END) AS nickname2
,SUM(CASE WHEN sensor_id = 571 THEN value ELSE 0.0 END) AS nickname3
FROM sensor_values
-- LEFT JOIN sensor_values_cleaned s2 USING (sensor_id, ts)
WHERE ts >= '2013-10-14T00:00:00+00:00'::timestamptz::timestamp
AND ts < '2013-10-18T00:00:00+00:00'::timestamptz::timestamp
AND sensor_id IN (572, 542, 571, 540, 541, 573)
GROUP BY ts::date AS day
ORDER BY 1;
Główne punkty
-
Zastąp słowa zastrzeżone (w standardowym SQL) w identyfikatorach.
timestamp->tstime->min_time -
Ponieważ sprzężenie jest na identycznych nazwach kolumn, możesz użyć prostszego
USINGklauzula w warunku dołączenia:USING (sensor_id, ts)
Jednak od drugiej tabelisensor_values_cleanedjest w 100% nieistotne dla tego zapytania, całkowicie je usunąłem. -
Jak już radził @joop, przełącz
min()ito_char()w pierwszej kolumnie wyjścia. W ten sposób Postgres może określić minimum na podstawie oryginalnej wartości kolumny , który jest zazwyczaj szybszy i może być w stanie wykorzystać indeks. W tym konkretnym przypadku zamawianie wedługdatejest również tańsze niż zamawianie za pomocątext, które również musiałyby uwzględniać zasady sortowania. -
Podobna uwaga dotyczy Twojego
WHEREwarunek:GDZIE ts::timestamptz>='2013-10-14T00:00:00+00:00'::timestamptzWHERE ts >= '2013-10-14T00:00:00+00:00'::timestamptz::timestampDrugi to sargable i może używać zwykłego indeksu na
ts- świetny wpływ na wydajność przy dużych stołach! -
Korzystanie z
ts::datezamiastdate_trunc('day', ts). Prostszy, szybszy, ten sam wynik. -
Najprawdopodobniej drugi warunek WHERE jest nieco niepoprawny. Zasadniczo wykluczyłbyś górną granicę :
AND ts <= '2013-10-18T00:00:00+00:00' ...AND ts < '2013-10-18T00:00:00+00:00' ... -
Podczas mieszania
timestampitimestamptztrzeba być świadomym efektów. Na przykład TwójWHEREwarunek nie jest odcinany o godzinie 00:00 czasu lokalnego (z wyjątkiem sytuacji, gdy czas lokalny pokrywa się z czasem UTC). Szczegóły tutaj:
Całkowite ignorowanie stref czasowych w Rails i PostgreSQL
Krok 2:Twoja prośba
I przypuszczam, że masz na myśli:
... różnicę między wartością najnowsze i najwcześniejsze znaczniki czasu...
W przeciwnym razie byłoby to znacznie prostsze.
Użyj funkcji okien
w tym celu, w szczególności first_value() i last_value() . Uważaj na kombinację, potrzebujesz nie -standardowa rama okienna
dla last_value() w tym przypadku. Porównaj:
Agregacja PostgreSQL lub funkcja okna zwracająca tylko ostatnią wartość
Łączę to z DISTINCT ON
, co jest w tym przypadku wygodniejsze niż GROUP BY (co wymagałoby innego poziomu podzapytania):
SELECT DISTINCT ON (ts::date, sensor_id)
ts::date AS day
,to_char((min(ts) OVER (PARTITION BY ts::date))::timestamptz
,'YYYY-MM-DD HH24:MI:SS TZ') AS min_time
,sensor_id
,last_value(value) OVER (PARTITION BY ts::date, sensor_id ORDER BY ts
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
- first_value(value) OVER (PARTITION BY ts::date, sensor_id ORDER BY ts)
AS val_range
FROM sensor_values
WHERE ts >= '2013-10-14T00:00:00+0'::timestamptz::timestamp
AND ts < '2013-10-18T00:00:00+0'::timestamptz::timestamp
AND sensor_id IN (540, 541, 542, 571, 572, 573)
ORDER BY ts::date, sensor_id;
Krok 3:Tabela przestawna
W oparciu o powyższe zapytanie używam crosstab()
z dodatkowego modułu tablefunc :
SELECT * FROM crosstab(
$$SELECT DISTINCT ON (1,3)
ts::date AS day
,to_char((min(ts) OVER (PARTITION BY ts::date))::timestamptz,'YYYY-MM-DD HH24:MI:SS TZ') AS min_time
,sensor_id
,last_value(value) OVER (PARTITION BY ts::date, sensor_id ORDER BY ts RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
- first_value(value) OVER (PARTITION BY ts::date, sensor_id ORDER BY ts) AS val_range
FROM sensor_values
WHERE ts >= '2013-10-14T00:00:00+0'::timestamptz::timestamp
AND ts < '2013-10-18T00:00:00+0'::timestamptz::timestamp
AND sensor_id IN (540, 541, 542, 571, 572, 573)
ORDER BY 1, 3$$
,$$VALUES (540), (541), (542), (571), (572), (573)$$
)
AS ct (day date, min_time text, s540 numeric, s541 numeric, s542 numeric, s571 numeric, s572 numeric, s573 numeric);
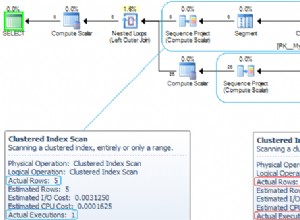
Zwroty (i dużo szybciej niż wcześniej):
day | min_time | s540 | s541 | s542 | s571 | s572 | s573
------------+--------------------------+-------+-------+-------+-------+-------+-------
2013-10-14 | 2013-10-14 03:00:00 CEST | 18.82 | 18.98 | 19.97 | 19.47 | 17.56 | 21.27
2013-10-15 | 2013-10-15 00:15:00 CEST | 22.59 | 24.20 | 22.90 | 21.27 | 22.75 | 22.23
2013-10-16 | 2013-10-16 00:16:00 CEST | 23.74 | 22.52 | 22.23 | 23.22 | 23.03 | 22.98
2013-10-17 | 2013-10-17 00:17:00 CEST | 21.68 | 24.54 | 21.15 | 23.58 | 23.04 | 21.94