Wprowadzenie
W tym artykule omówimy używanie nvarchar typ danych. Zbadamy, jak SQL Server przechowuje ten typ danych na dysku i jak jest przetwarzany w pamięci RAM. Zbadamy również, jak rozmiar nvarchar może wpływać na wydajność.
Rzeczywisty rozmiar danych:nchar vs nvarchar
Używamy nvarchar kiedy rozmiar wpisów danych w kolumnie prawdopodobnie będzie się znacznie różnić. Rozmiar pamięci (w bajtach) jest dwukrotnie większy od rzeczywistej długości wprowadzonych danych + 2 bajty. Pozwala nam to zaoszczędzić miejsce na dysku w porównaniu z użyciem nchar typ danych. Rozważmy następujący przykład. Tworzymy dwie tabele. Jedna tabela zawiera kolumnę nvarchar, inna tabela zawiera kolumny nchar. Rozmiar kolumny to 2000 znaków (4000 bajtów).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
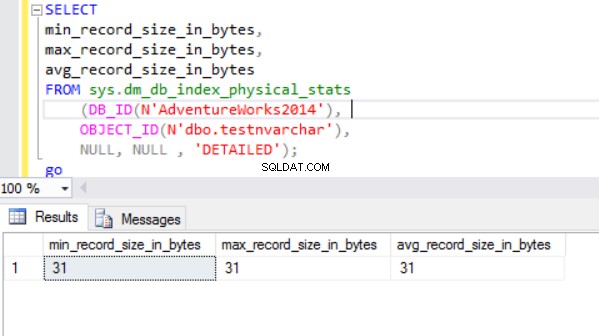
Rzeczywisty rozmiar wiersza to:
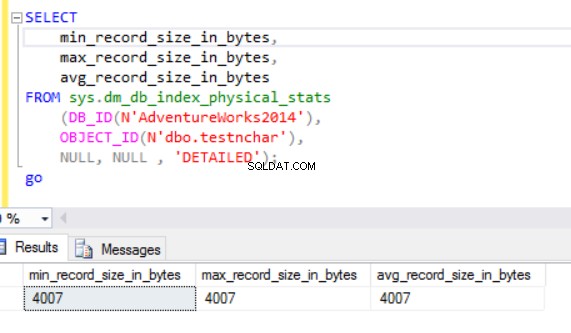
Jak widać, rzeczywisty rozmiar wiersza typu danych nvarchar jest znacznie mniejszy niż typ danych nchar. W przypadku typu danych nchar używamy ~4000 bajtów do przechowywania 10 symboli ciągu znaków. Używamy ~20 bajtów do przechowywania tego samego ciągu znaków w przypadku typu danych nvarchar.
Silnik SQL Server przetwarza dane w pamięci RAM (pula buforów). A co z rozmiarem wiersza w pamięci?
Rzeczywisty rozmiar danych:HDD vs RAM
Wykonajmy następujące zapytanie:
SELECT col1 FROM dbo.testnchar;

Nie ma różnicy między wykorzystaniem dysku i pamięci RAM w przypadku ciągu znaków o stałej długości.
SELECT col1 FROM dbo.testnvarchar;

Widzimy, że silnik SQL Server zażądał pamięci tylko dla połowy zadeklarowanego rozmiaru wiersza (2000 bajtów zamiast rzeczywistych 20 bajtów) i kilku bajtów na dodatkowe informacje. Z jednej strony zmniejszamy wykorzystanie miejsca na dysku, ale z drugiej możemy nadmuchać żądaną pamięć RAM. Jest to efekt uboczny używania różnych typów danych znaków. Ten efekt uboczny może w niektórych przypadkach mieć duży wpływ na zasoby.
FORMAT():Żądana pamięć RAM a wykorzystana pamięć RAM
Używamy funkcji FORMAT, która zwraca sformatowaną wartość z określonym formatem i opcjonalną kulturą. Zwracana wartość to nvarchar lub null. Długość zwracanej wartości jest określona przez format . FORMAT(getdate(), „rrrrMMdd”, „en-US”) da wynik „20170412”. Potrzebujemy 16 bajtów, aby zapisać ten wynik w kolumnie na dysku (wynikiem będzie nvarchar(8)). Jaki jest rozmiar danych w pamięci RAM dla poszczególnych danych?
Wykonajmy następujące zapytanie. Używamy następującego środowiska:
- AdventureWorks2014
- Wersja rozwojowa MS SQL 2016
- dbo.Klient (19 820 000 rekordów) zawiera dane ze sprzedaży.Klient (19 820 rekordów przesłano 1000 razy)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
Plan wykonania zapytania jest dość prosty:

Pierwsza operacja to „Skanowanie indeksu klastrowego” w tabeli dbo.Customer. Przeczytano ~19 000 000 rekordów. Szacowany rozmiar danych to 435 MB.
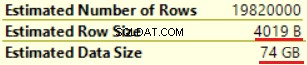
Następna operacja to „Oblicz skalar” (obliczanie funkcji FORMAT()). Wynik jest dość nieoczekiwany, ponieważ formatujemy 16-bajtowy ciąg znaków. Rozmiar wiersza drastycznie wzrósł z 23 bajtów do 4019 bajtów. To samo z szacowanym rozmiarem danych — od 435 MB do 74 GB. Widzimy, że FORMAT() zwraca NVARCHAR(4000).
MS SQL Server 2016 ma świetną zdolność do pokazywania nadmiernego przydziału pamięci. Widzimy ostrzeżenie w ostatniej operacji (T-SQL SELECT INTO):
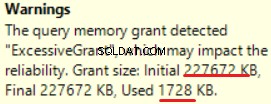
Jest to „nadmierna ilość” pamięci:ponad 90% przyznanej pamięci nie jest używane.
Statystyki czasu zapytania to:
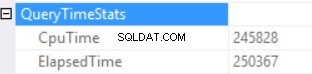
Długi czas wykonania zależy od nieefektywnego wykonania funkcji skalarnej i efektu wstecznego przyznania nadmiernej pamięci – Hash Match (Right Outer Join). Mamy skumulowany efekt dwóch różnych przyczyn:wielokrotne wykonywanie funkcji skalarnych i nadmierne przydzielanie pamięci.
Aparat SQL Server może przyznać nie więcej niż 25% dozwolonej pamięci na zapytanie. Wartość tę możemy zmienić w wersji Enterprise serwera MS SQL Server za pomocą gubernatora zasobów. Przyznana pamięć składa się z dwóch części:wymaganej i dodatkowej. Wymagana pamięć jest wykorzystywana na potrzeby wewnętrzne – do sortowania i operacji łączenia mieszającego. Dodatkowa pamięć jest oparta na szacowanym rozmiarze danych. Jeśli zarówno wymagana, jak i dodatkowa pamięć przekracza limit 25%, silnik SQL Server przyznaje kolejne 25% dostępnej pamięci. Przeczytaj wpis o przyznaniu pamięci SQL Server, aby uzyskać szczegółowe informacje.
Wykonajmy to samo zapytanie bez funkcji FORMAT().
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
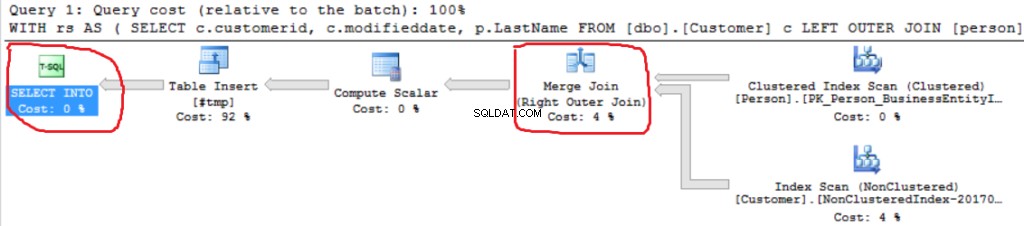
Możemy zobaczyć kolejną implementację Right Outer Join (Merge Join zamiast Hash Join).
Informacja o przyznaniu pamięci to (jeśli nie sortowanie i Hash Join SQL Server nie może przyznać pamięci):
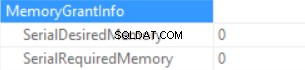
Czas zapytania Statystyki to (czas jest przewidywalnie skrócony:brak wykonania funkcji skalarnej, szacowany rozmiar danych jest mniejszy niż w poprzedniej próbce):

Tak więc zwiększamy „przyznaną pamięć” do 222 MB (i zużywamy mniej niż 2 MB) za pomocą funkcji FORMAT(). Ilość danych w przykładzie jest niewielka.
Zapytanie o wykonanie długiego czasu
Rozważ prawdziwe zapytanie SQL ze środowiska produkcyjnego. To zapytanie zostało wykonane podczas procesu ładowania wsadowego (nie w klasycznym scenariuszu transakcyjnym). Korzystamy z MS SQL Server uruchomionego na Amazon Web Services (AWS, Amazon Relational Database Service). Charakterystyki instancji DB to 160 GB pamięci RAM (nie więcej niż ~30 GB pamięci RAM można przyznać na zapytanie) i 40 vCPU. Zapytanie SQL było prawie takie samo jak w powyższym przykładzie (różnica polega na ilości tabel i wielkości danych):CTE zawierało łączenie między 6 tabelami. „Tabela główna” (tabela w klauzuli FROM) zawiera ~175 000 000 rekordów, a rozmiar danych wynosi 20 GB. Tabele przeglądowe (prawa tabela w klauzuli JOIN) są małe (w porównaniu z tabelą główną). Zapytanie SQL zawiera dwa wywołania funkcji FORMAT() (parametrem tej funkcji są dwie kolumny z tabeli „tabela główna”).
Zapytanie produkcyjne wygląda tak:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
„Obraz” planu wykonania znajduje się poniżej (plan wykonania jest prosty:łączenia sekwencyjne i sortowanie (słowa kluczowe DISTINCT) na górze):

Pozwól nam szczegółowo zbadać informacje.
Pierwsza operacja to „Skanowanie tabeli” (wszystko się zgadza, bez niespodzianek):

Operacja „Obliczenia skalarne” radykalnie zwiększa szacowany rozmiar wiersza, a także szacowany rozmiar wiersza (z 19 GB do 1,3 TB). Dwa wywołania funkcji FORMAT() dodały około 8000 bajtów do szacowanego rozmiaru wiersza (ale rzeczywisty rozmiar danych jest mniejszy).

Jedna z operacji JOIN (Hash Match, Right Outer Join) używa nieunikatowych kolumn z prawej tabeli. W przypadku kilku płyt nie ma to znaczenia. To nie jest nasz przypadek. W rezultacie szacowany rozmiar danych wzrasta do ~2,4 TB.

Pojawia się również ostrzeżenie (brak wystarczającej ilości pamięci RAM do przetworzenia tej operacji):
Zapytanie SQL zawiera na górze operację „Distinct Sort”, która wygląda jak wisienka na torcie. Widzimy tam to samo ostrzeżenie.
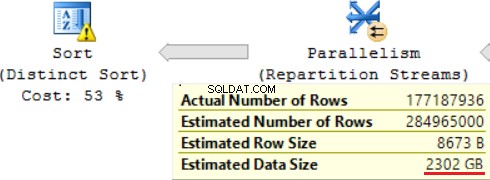
Efektem użycia funkcji skalarnej jest długi czas wykonania zapytania:24 godziny. Jedną z przyczyn tego problemu jest nieprawidłowe oszacowanie żądanego rozmiaru danych na podstawie „Szacowanego rozmiaru danych”. Bez użycia funkcji FORMAT(), MS SQL Server wykonuje to zapytanie w ciągu 2 godzin.
Wniosek
Deweloperzy powinni zachować ostrożność podczas używania typów danych nvarchar i varchar. Wybór redundantnych typów danych dla kolumn może prowadzić do zawyżenia wymaganej pamięci. W rezultacie pamięć RAM zostanie zmarnowana, a wydajność bazy danych spadnie.