Baza danych może zawierać setki tysięcy rekordów. Wstawianie i wybieranie tych rekordów jest łatwe za pomocą systemów zarządzania bazami danych, takich jak SQL Server lub MySQL itp. Jednak wyświetlanie tysięcy rekordów na jednej stronie internetowej lub w aplikacji komputerowej nie jest łatwe. Ograniczenia przestrzeni i pamięci utrudniają jednoczesne wyświetlanie ogromnej liczby rekordów.
Częstym rozwiązaniem takiego problemu jest zaimplementowanie stronicowania. (Uwaga, nie jest to stronicowanie pamięci zaimplementowane przez systemy operacyjne) Stronicowanie w programowaniu odnosi się do wyświetlania danych za pośrednictwem serii stron. Losowe wyszukiwanie w Google może dać tysiące wyników. Google używa stronicowania do wyświetlania tych wyników. Jeśli przewiniesz stronę Google z wynikami wyszukiwania, zobaczysz:

Tutaj możesz zobaczyć liczbę stron, na które podzielony jest wynik wyszukiwania. Możesz kliknąć link Dalej, aby zobaczyć więcej stron.
W tym artykule zobaczymy, jak operatory OFFSET FETCH NEXT mogą być używane do implementacji stronicowania w aplikacjach typu front-end. Zaczniemy od prostego przykładu z użyciem operatora OFFSET FETCH NEXT, a następnie zobaczymy, jak można go praktycznie wykorzystać za pomocą procedury składowanej.
Używanie OFFSET FETCH NEXT do stronicowania w SQL Server
SQL Server zawiera operatory OFFSET i NEXT do implementacji stronicowania. Operator OFFSET przesuwa następną liczbę K wyników wyszukiwania od początku, podczas gdy operator FETCH NEXT pobiera NEXT wyników, gdzie K i N są liczbami całkowitymi.
Przygotowywanie fikcyjnych danych
Zanim zobaczymy w akcji OFFSET FETCH NEXT, stwórzmy fikcyjną bazę danych z 200 rekordami. Możesz użyć działającej bazy danych, jeśli masz 100% pewności, że jej kopia zapasowa jest prawidłowo utworzona. W tym celu wykonaj następujący skrypt:
CREATE Database ShowRoom; GO USE ShowRoom; CREATE TABLE Cars ( id INT PRIMARY KEY IDENTITY, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL )
W powyższym skrypcie tworzymy fikcyjną bazę danych ShowRoom z jedną tabelą o nazwie Samochody. Dodajmy kilka fikcyjnych rekordów w tej bazie danych. Wykonaj następujący skrypt:
USE ShowRoom DECLARE @count INT SET @count = 1 DECLARE @carname VARCHAR (50) DECLARE @company_name VARCHAR (50) WHILE (@count <= 200) BEGIN SET @carname = 'Car - ' + LTRIM(@count) SET @company_name = 'Company - '+ LTRIM(@count) INSERT INTO Cars VALUES (@carname, @company_name, @count * 5) SET @count = @count + 1 END
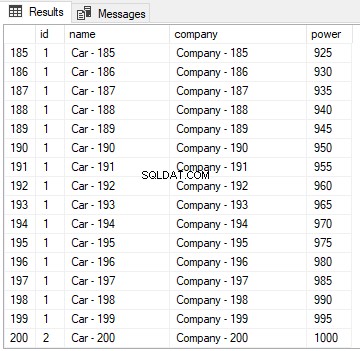
Przyjrzyj się uważnie powyższemu skryptowi. Powyższy skrypt wstawia 200 fikcyjnych rekordów do tabeli Samochody. Skrypt używa pętli while dla 200 iteracji. Każda iteracja dodaje słowo „Samochód -” do numeru iteracji, a wynik jest wstawiany do kolumny nazwy w tabeli Samochody. Podobnie słowo „Firma -” jest dołączane do numeru iteracji i wstawiane do kolumny firmy w każdej iteracji. Na koniec, z każdą iteracją, numer iteracji jest mnożony przez 5, a wynik jest wstawiany do kolumny potęgi. Teraz, jeśli wybierzesz wszystkie rekordy z tabeli Samochody, zobaczysz 200 rekordów w zestawie wyników. W tym celu wykonaj następujące zapytanie:
SELECT * FROM Cars
Zrzut ekranu częściowego wyniku powyższego zapytania jest następujący. Możesz zobaczyć 200 wierszy w wyniku.
FETCH FETCH NEXT Przykład
Teraz spójrzmy na OFFSET NEXT w akcji. Składnia OFFSET NEXT jest następująca:
SELECT * FROM Table_Name ORDER BY COLUMN_NAME/S OFFSET Number_of_rows_to_Skip ROWS FETCH NEXT Number_of_rows_to_Fetch ROWS ONLY
Należy tutaj wspomnieć, że musisz użyć klauzuli ORDER BY z klauzulami OFFSET FETCH NEXT.
Zobaczmy prosty przykład OFFSET FETCH NEXT, w którym uporządkujemy dane według kolumny id tabeli Cars, pominiemy pierwsze 20 wierszy i pobierzemy kolejne 10 wierszy. Wykonaj następujący skrypt:
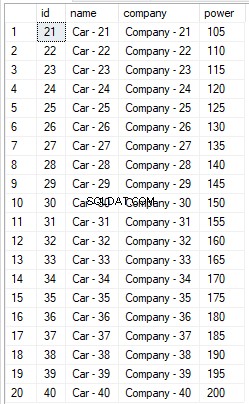
USE ShowRoom SELECT * FROM Cars ORDER BY id OFFSET 20 ROWS FETCH NEXT 10 ROWS ONLY
W wyniku powyższego skryptu zobaczysz rekordy o wartości identyfikatora od 21 do 30, ponieważ pominęliśmy pierwsze 20 rekordów i pobraliśmy następne 10.
Używanie OFFSET FETCH NEXT z procedurą zapisaną
Jeśli wdrażasz stronicowanie w aplikacji frontonu, takiej jak witryna internetowa lub aplikacja komputerowa, zazwyczaj wysyłasz wartości numeru i rozmiaru strony do serwera za pomocą procedury składowanej. W zależności od wartości numeru strony i rozmiaru strony procedura składowana zwróci poprawny zestaw wierszy. Napiszmy taką procedurę składowaną, która przyjmuje numer strony i rozmiar strony jako parametry i zwraca odpowiednie rekordy.
Spójrz na następujący skrypt:
USE ShowRoom GO CREATE PROC spGetRecordsByPageAndSize @Page INT, @Size INT AS BEGIN SELECT * FROM Cars ORDER BY id OFFSET (@Page -1) * @Size ROWS FETCH NEXT @Size ROWS ONLY END
W powyższym skrypcie tworzymy procedurę składowaną spGetRecordsByPageAndSize, która przyjmuje 2 parametry @Page i @Size. Procedura składowana używa OFFSET FETCH NEXT do filtrowania rekordów według liczby stron i rozmiaru strony. Na przykład, jeśli numer strony to 2, a rozmiar to 20, PRZESUNIĘCIE będzie wynosić:
(2 – 1) * 20 =20
A wartość dla FETCH next będzie równa @Size czyli 20. Dlatego zostaną zwrócone rekordy o identyfikatorach od 21 do 40. Wykonaj powyższy skrypt, aby utworzyć procedurę składowaną.
Po utworzeniu procedury składowanej wykonaj następujący skrypt, aby zobaczyć, co jest zwracane, gdy numer strony wynosi 2, a rozmiar strony wynosi 20.
EXECUTE spGetRecordsByPageAndSize 2, 20
Wynik powyższego skryptu wygląda tak:
Podobnie, jeśli chcesz pobrać rekordy dla czwartej strony z 15 rekordami na stronę, następujące zapytanie pobiera rekordy od id 46 do id 60.
EXECUTE spGetRecordsByPageAndSize 4, 15
Wynik działania wygląda tak:
Wniosek
OFFSET FETCH NEXT to niezwykle przydatne narzędzie, zwłaszcza jeśli chcesz wyświetlić dużą liczbę rekordów pogrupowanych w strony. W tym artykule zobaczyliśmy, jak jest on używany w połączeniu z procedurą składowaną do implementacji stronicowania w aplikacjach typu front-end.