Baza danych jest krytyczną i istotną częścią każdej firmy lub organizacji. Rosnące trendy przewidują, że 82% przedsiębiorstw spodziewa się wzrostu liczby baz danych w ciągu najbliższych 12 miesięcy. Głównym wyzwaniem każdego administratora baz danych jest odkrycie, jak radzić sobie z ogromnym wzrostem ilości danych, a to będzie najważniejszy cel. Jak zwiększyć wydajność bazy danych, obniżyć koszty i wyeliminować przestoje, aby zapewnić użytkownikom jak najlepsze wrażenia? Czy kompresja danych jest opcją? Zacznijmy i zobaczmy, jak niektóre z istniejących funkcji mogą być przydatne w takich sytuacjach.
W tym artykule dowiemy się, w jaki sposób rozwiązanie do kompresji danych może pomóc nam zoptymalizować rozwiązanie do zarządzania danymi. W tym przewodniku omówimy następujące tematy:
- Przegląd kompresji
- Zalety kompresji
- Zarys danych to techniki kompresji
- Omówienie różnych rodzajów kompresji danych
- Fakty dotyczące kompresji danych
- Zagadnienia dotyczące implementacji
- i więcej…
Kompresja
Kompresja jest techniką, a zatem operacją wrażliwą na zasoby, ale wymaga kompromisów sprzętowych. Należy pomyśleć o wdrożeniu kompresji danych, aby uzyskać następujące korzyści:
- Skuteczne zarządzanie przestrzenią
- Skuteczna technika redukcji kosztów
- Łatwość zarządzania kopiami zapasowymi bazy danych
- Efektywne wykorzystanie przepustowości N/W
- Bezpieczne i szybsze odzyskiwanie lub przywracanie
- Lepsza wydajność – zmniejsza zużycie pamięci systemu
Uwaga: Jeśli SQL Server jest ograniczony procesorem lub pamięcią, kompresja może nie pasować do Twojego środowiska.
Kompresja danych dotyczy:
- Stopy
- Indeksy klastrowe
- Indeksy nieklastrowe
- Partycje
- Zindeksowane widoki
Uwaga: Duże obiekty nie są kompresowane (na przykład LOB i BLOB)
Najlepiej nadaje się do następujących zastosowań:
- Tabele dzienników
- Tabele kontrolne
- Tabele faktów
- Raportowanie
Wprowadzenie
Kompresja danych to technologia, która istnieje od SQL Server 2008. Idea kompresji danych polega na tym, że można selektywnie wybierać tabele, indeksy lub partycje w bazie danych. We/Wy nadal stanowi wąskie gardło w przenoszeniu informacji między wejściem i wyjściem z bazy danych. Kompresja danych wykorzystuje ten typ i pomaga zwiększyć wydajność bazy danych. Ponieważ wiemy, że prędkości sieci są znacznie wolniejsze niż prędkość przetwarzania, można znaleźć wzrost wydajności, wykorzystując moc obliczeniową do kompresji danych w bazie danych, dzięki czemu podróżuje ona szybciej. A następnie ponownie użyj mocy obliczeniowej, aby zdekompresować dane na drugim końcu. Ogólnie kompresja danych zmniejsza przestrzeń zajmowaną przez dane. Technika kompresji danych jest dostępna dla każdej bazy danych i jest obsługiwana przez wszystkie edycje SQL Server 2016 SP1. Wcześniej był dostępny tylko w wersjach SQL Server Enterprise lub Developer, a nie w wersji Standard lub Express.
Obsługa funkcji

Typy kompresji danych
W SQL Server dostępne są dwa rodzaje kompresji danych, na poziomie wiersza i na poziomie strony.
Kompresja na poziomie wiersza działa w tle i konwertuje dowolne typy danych o stałej długości na typy o zmiennej długości. Założenie jest tutaj takie, że często dane są przechowywane w typie o stałej długości, na przykład char 100, i nie wypełniają one w rzeczywistości całych 100 znaków dla każdego rekordu. Małe korzyści można osiągnąć, usuwając tę dodatkową przestrzeń ze stołu. Oczywiście, jeśli twoje tabele danych nie używają pól tekstowych i numerycznych o stałej długości lub jeśli tak jest i faktycznie przechowujesz w pełni dozwoloną liczbę znaków i cyfr, wówczas przyrosty kompresji w schemacie na poziomie wiersza będą minimalne w najlepszym razie.
Koncepcja kompresji została rozszerzona na wszystkie typy danych o stałej długości, w tym char, int i float. SQL Server pozwala zaoszczędzić miejsce, przechowując dane tak, jakby były typu o zmiennej wielkości; dane pojawią się i będą zachowywać jak stała długość.
Na przykład, jeśli zapisałeś wartość 100 w int kolumna, SQL Server nie musi używać wszystkich 32 bitów, zamiast tego używa po prostu 8 bitów (1 bajt).
Kompresja na poziomie strony przenosi rzeczy na inny poziom. Po pierwsze, automatycznie stosuje kompresję na poziomie wiersza w polach danych o stałej długości, dzięki czemu domyślnie otrzymujesz te korzyści. Następnie stosuje coś, co nazywa się kompresją prefiksów i inną technikę zwaną kompresją słownika.
Kompresja wierszy
Kompresja wierszy to wewnętrzny poziom kompresji, który przechowuje stałe ciągi znaków przy użyciu formatu o zmiennej długości, nie przechowując pustych znaków. Podczas kompresji na poziomie wiersza wykonywane są następujące kroki.
- Wszystkie liczbowe typy danych, takie jak int , pływający , dziesiętny, i pieniądze są konwertowane na typy danych o zmiennej długości. Na przykład 125 przechowywanych w kolumnie i typ danych kolumny to liczba całkowita. Wtedy wiemy, że 4 bajty są używane do przechowywania wartości całkowitej. Ale 125 może być przechowywane w 1 bajcie, ponieważ 1 bajt może przechowywać wartości od 0 do 255. Tak więc 125 może być przechowywany jako mały int , dzięki czemu można zapisać 3 bajty.
- Char i Nchar typy danych są przechowywane jako typy danych o zmiennej długości. Na przykład „SQL” jest przechowywany w znaku (20) wpisz kolumnę. Ale po kompresji będą używane tylko 3 bajty. Po kompresji danych żaden pusty znak nie jest przechowywany w tego typu danych.
- Metadane rekordu są zmniejszone.
- Wartości NULL i 0 są zoptymalizowane i nie zajmuje miejsca.
Kompresja strony
Kompresja strony to zaawansowany poziom kompresji danych. Domyślnie kompresja strony implementuje również kompresję na poziomie wiersza. Kompresja strony jest podzielona na dwa typy
- Kompresja prefiksu i
- Kompresja słownika.
Kompresja prefiksu
W przypadku kompresji prefiksu dla każdej strony, dla każdej kolumny na stronie, ze wszystkich wierszy pobierana jest wspólna wartość i przechowywana pod nagłówkiem w każdej kolumnie. Teraz w każdym wierszu przechowywane jest odwołanie do tej wartości zamiast zwykłej wartości.
Kompresja słownika
Kompresja słownika jest podobna do kompresji przedrostków, ale wspólne wartości są pobierane ze wszystkich kolumn i przechowywane w drugim wierszu po nagłówku. Kompresja słownika szuka dokładnych dopasowań wartości we wszystkich kolumnach i wierszach na każdej stronie.
Możemy wykonać kompresję na poziomie wiersza i strony dla następujących obiektów bazy danych.
- Tabela przechowywana na stercie.
- Cała tabela przechowywana jako indeks klastrowy.
- Widok indeksowany.
- Indeks nieklastrowany.
- Indeksy i tabele podzielone na partycje.
Uwaga: Możemy wykonać kompresję danych zarówno w momencie tworzenia jak CREATE TABLE, CREATE INDEX lub po utworzeniu za pomocą komendy ALTER z opcją REBUILD jak ALTER TABLE…. ODBUDUJ Z.
Demo
WideWorldImporterzy baza danych jest używana przez całe demo. Ponadto dostępny w czasie rzeczywistym DW baza danych jest brana pod uwagę podczas operacji kompresji.
Przeanalizujmy szczegółowo te kroki:
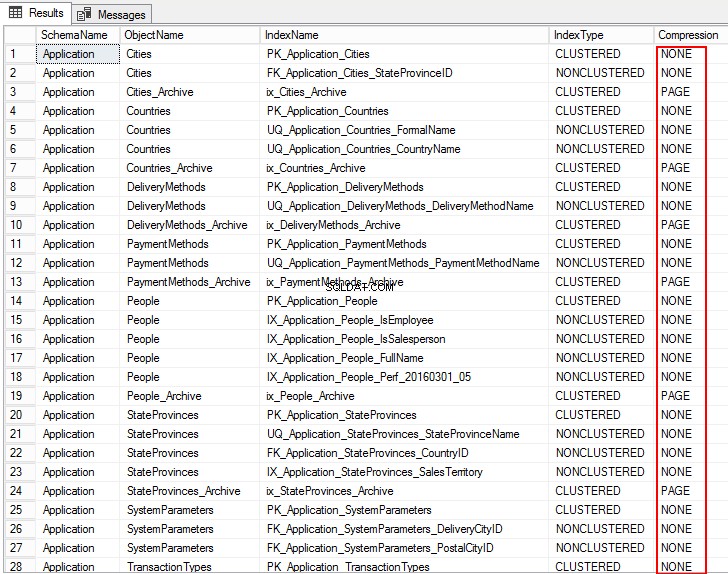
1. Aby wyświetlić ustawienia kompresji obiektów w bazie danych, uruchom następujący T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
Poniższe dane wyjściowe pokazują typ kompresji jako PAGE, ROW, a dla kilku tabel jest to BRAK. Oznacza to, że nie jest skonfigurowany do kompresji.
2. Aby oszacować kompresję, uruchom następującą systemową procedurę składowaną sp_estimate_data_compression_savings . W takim przypadku procedura składowana jest wykonywana w tabelach PurchaseOrderLines.
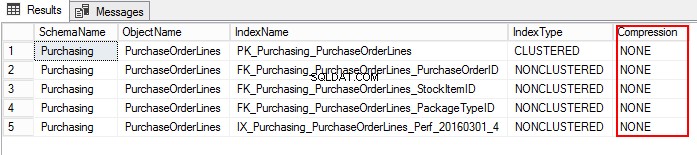
3. Sprawdźmy ustawienie kompresji PurchaseOrderLines, uruchamiając następujący T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

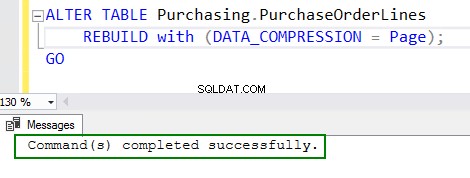
4. Włącz kompresję, uruchamiając polecenie ALTER table:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
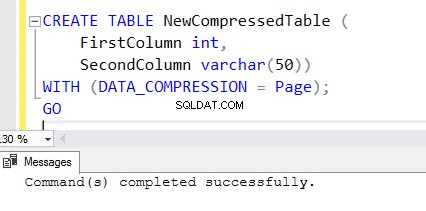
5. Aby utworzyć nową tabelę z włączoną funkcją kompresji, dodaj klauzulę WITH na końcu instrukcji CREATE TABLE. Możesz zobaczyć poniższe polecenie CREATE TABLE używane do tworzenia nowej tabeli skompresowanej .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Fakty dotyczące kompresji danych
Przyjrzyjmy się niektórym aktualnym informacjom o kompresji
- Nie można zastosować kompresji do tabel systemowych
- Tabeli nie można włączyć do kompresji, gdy rozmiar wiersza przekracza 8060 bajtów.
- Skompresowane dane są buforowane w puli buforów; oznacza to szybsze czasy reakcji
- Włączenie kompresji może spowodować zmianę planów zapytań, ponieważ dane są przechowywane przy użyciu różnej liczby stron i liczby wierszy na stronę.
- Indeksy nieklastrowe nie dziedziczą właściwości kompresji
- Gdy indeks klastrowy jest tworzony na stercie, indeks klastrowy dziedziczy stan kompresji sterty, chyba że określono alternatywny stan kompresji.
- Kompresja na poziomie ROW i PAGE może być włączana i wyłączana, offline lub online.
- Jeśli ustawienie sterty zostanie zmienione, wszystkie indeksy nieklastrowane mają zostać odbudowane.
- Wymagania dotyczące miejsca na dysku do włączania lub wyłączania kompresji wiersza lub strony są takie same, jak w przypadku tworzenia lub odbudowy indeksu.
- Gdy partycje są dzielone przy użyciu instrukcji ALTER PARTITION, obie partycje dziedziczą atrybut kompresji danych oryginalnej partycji.
- Gdy dwie partycje są łączone, partycja wynikowa dziedziczy atrybut kompresji danych partycji docelowej.
- Aby przełączyć partycję, właściwość kompresji danych partycji musi odpowiadać właściwości kompresji tabeli.
- Tabele i indeksy magazynu kolumn są zawsze przechowywane z kompresją magazynu kolumn.
- Kompresja danych jest niezgodna z rzadkimi kolumnami, więc tabela nie może zostać skompresowana.
Scenariusz w czasie rzeczywistym
Zapoznajmy się z techniką kompresji danych i zrozummy kluczowe parametry kompresji danych.
Aby sprawdzić miejsce używane przez każdą tabelę, uruchom następujący T-SQL. Wynik zapytania dostarcza nam szczegółowych informacji o użyciu każdej tabeli. Byłby to decydujący czynnik dla wdrożenia kompresji danych.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
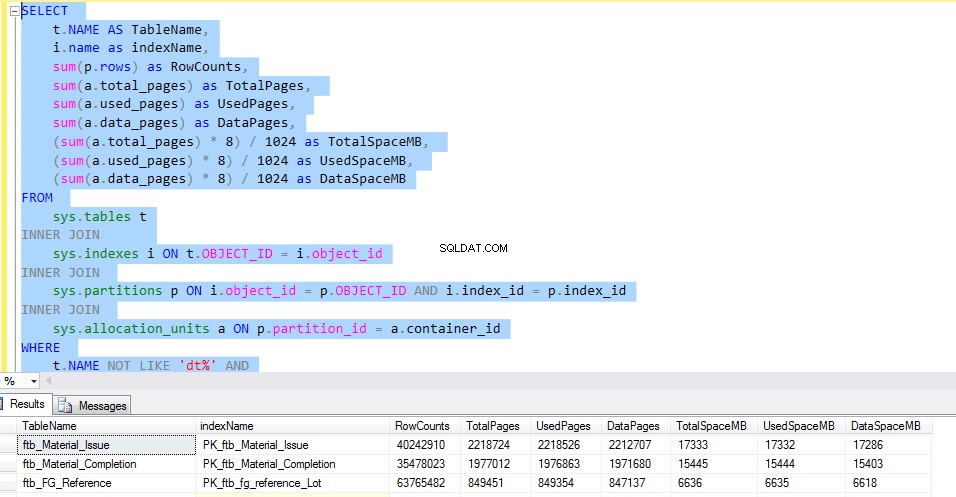
Rozważmy ftb_material_Issue tabela faktów. Tabela faktów zawiera numeryczne typy danych BIGINT.
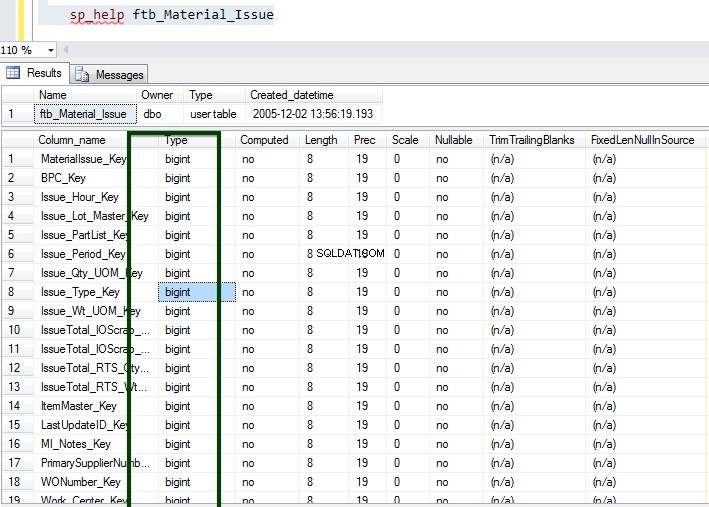
Teraz uruchom procedurę składowaną sp_spaceused, aby poznać szczegóły tabeli. Możesz dowiedzieć się więcej o poleceniu sp_spaceused tutaj.
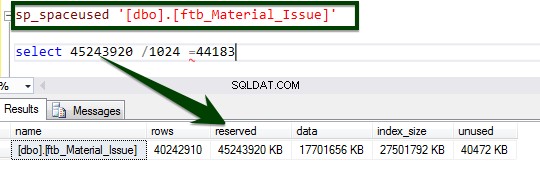
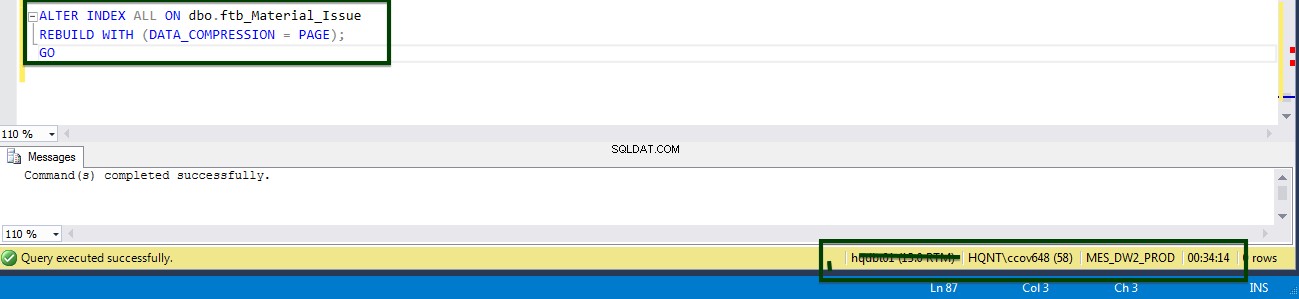
Włącz kompresję na poziomie tabeli, uruchamiając następujący język T-SQL. Na serwerze wykonano następujący T-SQL, a kompresja strony na poziomie tabeli zajęła 34 minuty i 14 sekund.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
Możesz zobaczyć fluktuacje procesora i we/wy podczas wykonywania polecenia tabeli ALTER.
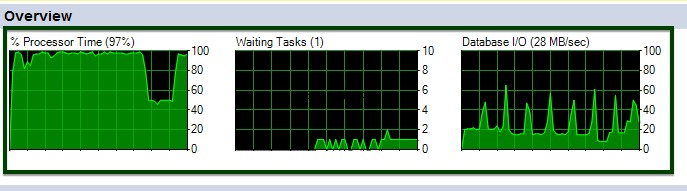
Teraz zróbmy porównanie przed i po kompresji danych. Rozmiar stołu około ~45 GB został zmniejszony do ~15 GB.
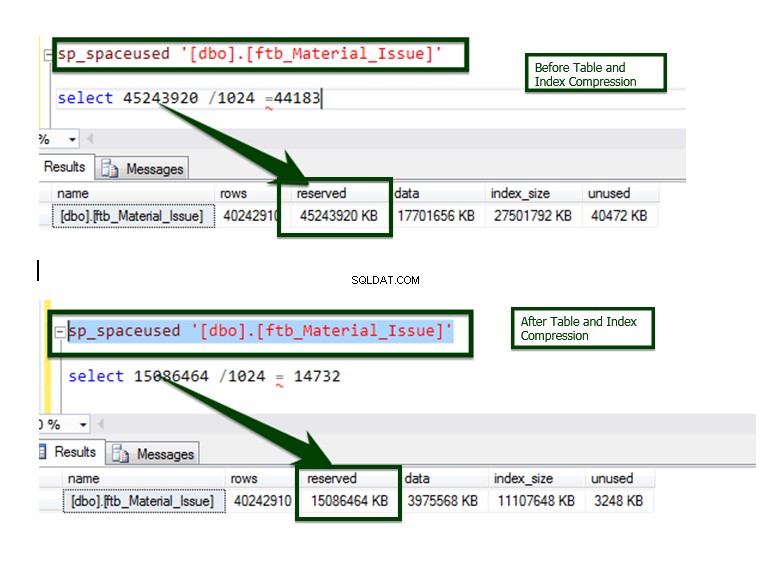
Proces jest zaimplementowany na większości obiektów za pomocą zautomatyzowanego skryptu i oto końcowy wynik porównania.
Porównanie danych przed i po operacji kompresji indeksu.

Podsumowanie
Kompresja danych to bardzo skuteczna technika zmniejszania rozmiaru danych; zmniejszona ilość danych wymaga mniejszej liczby procesów we/wy. Dodanie kompresji do bazy danych zwiększa obciążenie procesora. Musisz upewnić się, że masz dostępną zdolność przetwarzania, aby skutecznie dostosować się do tych zmian. Lepiej więc najpierw przeprowadzić trochę badań i zobaczyć, jakich korzyści można się spodziewać przed zastosowaniem modyfikacji umożliwiających kompresję danych. Jest to bardzo korzystne w konfiguracji bazy danych w chmurze, gdzie wiąże się z kosztami.
Ustawiaj kompresje (nie wykonuj ich wszystkich naraz) i kompresuj w okresach niskiej aktywności. Kompresja danych i kompresja kopii zapasowych dobrze współistnieją i mogą skutkować dodatkowymi oszczędnościami miejsca na dysku, więc śmiało.
Kompresja nie tylko zmniejsza fizyczne rozmiary plików, ale także zmniejsza we/wy dysku, co może znacznie zwiększyć wydajność wielu aplikacji bazodanowych, a także kopii zapasowych bazy danych.
Podjęcie decyzji o wdrożeniu kompresji jest łatwiejsze, jeśli znamy podstawową infrastrukturę i wymagania biznesowe. Zdecydowanie możemy skorzystać z dostępnej procedury systemowej, aby zrozumieć i oszacować oszczędności związane z kompresją. Ta procedura składowana nie zawiera żadnych takich szczegółów, które informują, w jaki sposób kompresja pozytywnie lub negatywnie wpłynie na system. Oczywiste jest, że istnieją kompromisy z jakąkolwiek kompresją. Jeśli masz te same wzorce ogromnych danych, kompresja jest kluczem do oszczędzania miejsca. Wraz ze wzrostem mocy procesora i każdym systemem związanym ze strukturami wielordzeniowymi kompresja może pasować do wielu systemów. Polecam przetestowanie waszych systemów. Przetestuj, aby upewnić się, że nie ma to negatywnego wpływu na wydajność. Jeśli indeks zawiera wiele aktualizacji i usunięć, koszt procesora kompresji i dekompresji danych może przewyższyć oszczędności we/wy i pamięci RAM wynikające z kompresji danych. Nie każda baza danych lub tabela będzie automatycznie dobrym kandydatem do zastosowania kompresji, więc najlepiej jest najpierw przeprowadzić trochę badań, aby zobaczyć, jakich korzyści można się spodziewać przed zastosowaniem modyfikacji umożliwiających kompresję danych w bazach danych. Musisz przetestować kompresję, aby sprawdzić, czy działa dobrze w twoim środowisku, ponieważ może nie działać dobrze w bazach danych o dużej gęstości.
Referencje
Wersje i obsługiwane funkcje SQL Server 2016
Kompresja danych
Implementacja kompresji wierszy
Implementacja kompresji strony