Wprowadzenie
Bez względu na to, jak bardzo staramy się projektować i rozwijać aplikacje, błędy zawsze się pojawią. Istnieją dwie ogólne kategorie – błędy składniowe lub logiczne mogą być błędami programistycznymi lub konsekwencjami nieprawidłowego projektu bazy danych. W przeciwnym razie możesz otrzymać błąd z powodu nieprawidłowego wprowadzenia danych przez użytkownika.
T-SQL (język programowania SQL Server) umożliwia obsługę obu typów błędów. Możesz debugować aplikację i zdecydować, co musisz zrobić, aby uniknąć błędów w przyszłości.
Większość aplikacji wymaga rejestrowania błędów, implementacji przyjaznego dla użytkownika raportowania błędów oraz, jeśli to możliwe, obsługi błędów i kontynuowania wykonywania aplikacji.
Użytkownicy obsługują błędy na poziomie instrukcji. Oznacza to, że gdy uruchomisz partię poleceń SQL, a problem wystąpi w ostatniej instrukcji, wszystko, co poprzedza ten problem, zostanie zatwierdzone w bazie danych jako transakcje niejawne. To może nie być to, czego pragniesz.
Relacyjne bazy danych są zoptymalizowane pod kątem wykonywania instrukcji wsadowych. Dlatego musisz wykonać partię instrukcji jako jedną jednostkę i odrzucić wszystkie instrukcje, jeśli jedna z nich nie powiedzie się. Możesz to osiągnąć za pomocą transakcji. W tym artykule skupimy się zarówno na obsłudze błędów, jak i transakcjach, ponieważ te tematy są ściśle ze sobą powiązane.
Obsługa błędów SQL
Aby zasymulować wyjątki, musimy je wytwarzać w powtarzalny sposób. Zacznijmy od najprostszego przykładu – dzielenia przez zero:
SELECT 1/0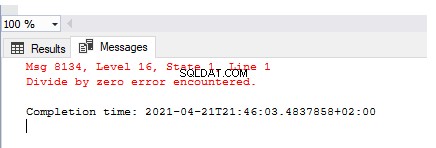
Dane wyjściowe opisują zgłoszony błąd — Wystąpił błąd dzielenia przez zero . Ale ten błąd nie został obsłużony, zarejestrowany ani dostosowany w celu wygenerowania przyjaznej dla użytkownika wiadomości.
Obsługa wyjątków rozpoczyna się od umieszczenia instrukcji, które chcesz wykonać w bloku BEGIN TRY…END TRY.
SQL Server obsługuje (łapie) błędy w bloku BEGIN CATCH…END CATCH, w którym można wprowadzić niestandardową logikę rejestrowania lub przetwarzania błędów.
Instrukcja BEGIN CATCH musi następować bezpośrednio po instrukcji END TRY. Wykonanie jest następnie przekazywane z bloku TRY do bloku CATCH przy pierwszym wystąpieniu błędu.
Tutaj możesz zdecydować, jak postępować z błędami, czy chcesz rejestrować dane o zgłoszonych wyjątkach, czy utworzyć przyjazną dla użytkownika wiadomość.
SQL Server ma wbudowane funkcje, które mogą pomóc w wyodrębnieniu szczegółów błędów:
- ERROR_NUMBER():Zwraca liczbę błędów SQL.
- ERROR_SEVERITY():Zwraca poziom istotności, który wskazuje typ napotkanego problemu i jego poziom. Poziomy od 11 do 16 mogą być obsługiwane przez użytkownika.
- ERROR_STATE():Zwraca numer stanu błędu i podaje więcej szczegółów na temat zgłoszonego wyjątku. Numer błędu służy do przeszukiwania bazy wiedzy Microsoft w celu znalezienia szczegółowych informacji o błędzie.
- ERROR_PROCEDURE():Zwraca nazwę procedury lub wyzwalacza, w którym zgłoszono błąd, lub NULL, jeśli błąd nie wystąpił w procedurze lub wyzwalaczu.
- ERROR_LINE():Zwraca numer wiersza, w którym wystąpił błąd. Może to być numer linii procedur lub wyzwalaczy albo numer linii w partii.
- ERROR_MESSAGE():Zwraca tekst komunikatu o błędzie.
Poniższy przykład pokazuje, jak obsługiwać błędy. Pierwszy przykład zawiera Podział przez zero błąd, podczas gdy drugie stwierdzenie jest poprawne.
BEGIN TRY
PRINT 1/0
SELECT 'Correct text'
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH

Jeśli druga instrukcja zostanie wykonana bez obsługi błędów (SELECT ‘Popraw tekst’), to się powiedzie.
Ponieważ implementujemy niestandardową obsługę błędów w bloku TRY-CATCH, wykonanie programu jest przekazywane do bloku CATCH po błędzie w pierwszej instrukcji, a druga instrukcja nigdy nie została wykonana.
W ten sposób możesz modyfikować tekst przekazany użytkownikowi i lepiej kontrolować, co się stanie, jeśli błąd wystąpi. Na przykład rejestrujemy błędy w tabeli dzienników w celu dalszej analizy.
Korzystanie z transakcji
Logika biznesowa może określić, że wstawienie pierwszej instrukcji nie powiedzie się, gdy druga instrukcja nie powiedzie się, lub że konieczne może być powtórzenie zmian pierwszej instrukcji w przypadku niepowodzenia drugiej instrukcji. Korzystanie z transakcji pozwala wykonać partię oświadczeń jako jedną jednostkę, która albo się nie powiedzie, albo się powiedzie.
Poniższy przykład ilustruje użycie transakcji.
Najpierw tworzymy tabelę do testowania przechowywanych danych. Następnie używamy dwóch transakcji wewnątrz bloku TRY-CATCH, aby zasymulować to, co dzieje się, jeśli część transakcji się nie powiedzie.
Użyjemy instrukcji CATCH z instrukcją XACT_STATE(). Funkcja XACT_STATE() służy do sprawdzenia, czy transakcja nadal istnieje. W przypadku automatycznego wycofania transakcji, TRANSAKCJA WYCOFANIA wygeneruje nowy wyjątek.
Zdobądź łup w poniższym kodzie:
-- CREATE TABLE TEST_TRAN(VALS INT)
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(1);
COMMIT TRANSACTION
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(2);
INSERT INTO TEST_TRAN(VALS) VALUES('A');
INSERT INTO TEST_TRAN(VALS) VALUES(3);
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() > 0 ROLLBACK TRANSACTION
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
SELECT * FROM TEST_TRAN
-- DROP TABLE TEST_TRAN
Obraz przedstawia wartości w tabeli TEST_TRAN i komunikaty o błędach:
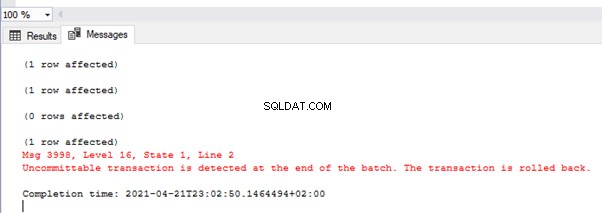
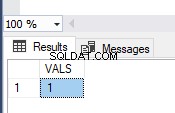
Jak widzisz, tylko pierwsza wartość została zatwierdzona. W drugiej transakcji wystąpił błąd konwersji typu w drugim wierszu. W ten sposób cała partia została wycofana.
W ten sposób możesz kontrolować, jakie dane trafiają do bazy danych i jak przetwarzane są partie.
Generowanie niestandardowego komunikatu o błędzie w SQL
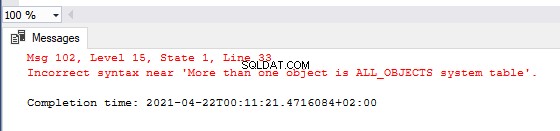
Czasami chcemy tworzyć niestandardowe komunikaty o błędach. Zazwyczaj są przeznaczone do scenariuszy, w których wiemy, że może wystąpić problem. Możemy tworzyć własne, niestandardowe komunikaty informujące, że stało się coś złego, bez pokazywania szczegółów technicznych. W tym celu używamy słowa kluczowego THROW.
BEGIN TRY
IF ( SELECT COUNT(sys.all_objects) > 1 )
THROW ‘More than one object is ALL_OBJECTS system table’
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
Lub chcielibyśmy mieć katalog niestandardowych komunikatów o błędach do kategoryzacji i spójności monitorowania i raportowania błędów. SQL Server pozwala nam wstępnie zdefiniować kod, ważność i stan komunikatu o błędzie.
Procedura składowana o nazwie „sys.sp_addmessage” służy do dodawania niestandardowych komunikatów o błędach. Możemy go użyć do wywołania komunikatu o błędzie w wielu miejscach.
Możemy wywołać RAISERROR i wysłać numer wiadomości jako parametr zamiast wpisywać te same szczegóły błędu w wielu miejscach w kodzie.
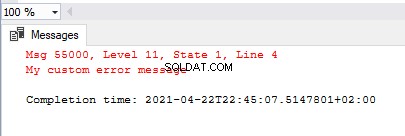
Wykonując wybrany kod poniżej, dodajemy niestandardowy błąd do SQL Server, podnosimy go, a następnie używamy sys.sp_dropmessage aby usunąć określony komunikat o błędzie zdefiniowany przez użytkownika:
exec sys.sp_addmessage @msgnum=55000, @severity = 11,
@msgtext = 'My custom error message'
GO
RAISERROR(55000,11,1)
GO
exec sys.sp_dropmessage @msgnum=55000
GO
Ponadto możemy wyświetlić wszystkie wiadomości w SQL Server, wykonując poniższy formularz zapytania. Nasz niestandardowy komunikat o błędzie jest widoczny jako pierwszy element w zestawie wyników:
SELECT * FROM master.dbo.sysmessages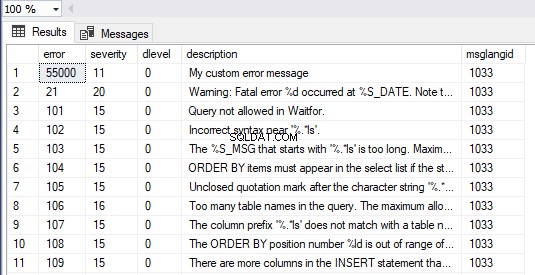
Utwórz system do rejestrowania błędów
Zawsze warto rejestrować błędy w celu późniejszego debugowania i przetwarzania. Możesz również umieścić wyzwalacze na tych zarejestrowanych tabelach, a nawet skonfigurować konto e-mail i uzyskać nieco kreatywności w zakresie powiadamiania ludzi o wystąpieniu błędu.
Aby rejestrować błędy, tworzymy tabelę o nazwie DBError_Log , który może służyć do przechowywania szczegółowych danych dziennika:
CREATE TABLE DBError_Log
(
DBError_Log_ID INT IDENTITY(1, 1) PRIMARY KEY,
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME
);
Aby zasymulować mechanizm logowania, tworzymy GenError procedura składowana, która generuje Podział przez zero błąd i rejestruje błąd w DBError_Log tabela:
CREATE PROCEDURE dbo.GenError
AS
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
INSERT INTO dbo.DBError_Log
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE()
);
END CATCH
GO
EXEC dbo.GenError
SELECT * FROM dbo.DBError_Log
DBError_Log tabela zawiera wszystkie informacje potrzebne do debugowania błędu. Zawiera również dodatkowe informacje o procedurze, która spowodowała błąd. Chociaż może się to wydawać trywialnym przykładem, możesz rozszerzyć tę tabelę o dodatkowe pola lub użyć jej do wypełnienia jej niestandardowymi wyjątkami.
Wniosek
Jeśli chcemy utrzymywać i debugować aplikacje, chcemy przynajmniej zgłaszać, że coś poszło nie tak, a także rejestrować to pod maską. Gdy mamy aplikację na poziomie produkcyjnym, z której korzystają miliony użytkowników, spójna i możliwa do zgłaszania obsługa błędów jest kluczem do debugowania problemów w środowisku wykonawczym.
Chociaż możemy zarejestrować oryginalny błąd w dzienniku błędów bazy danych, użytkownicy powinni zobaczyć bardziej przyjazny komunikat. Dlatego dobrym pomysłem byłoby zaimplementowanie niestandardowych komunikatów o błędach, które są wysyłane do wywołujących aplikacji.
Niezależnie od tego, jaki projekt zaimplementujesz, musisz rejestrować i obsługiwać wyjątki użytkownika i systemu. To zadanie nie jest trudne z SQL Server, ale trzeba je zaplanować od początku.
Dodanie operacji obsługi błędów w bazach danych, które już działają w środowisku produkcyjnym, może wiązać się z poważną refaktoryzacją kodu i trudnymi do znalezienia problemami z wydajnością.