Od czasu wydania SQL Server 2017 dla systemu Linux firma Microsoft zmieniła praktycznie całą grę. Umożliwił zupełnie nowy świat możliwości dla ich słynnej relacyjnej bazy danych, oferując to, co do tej pory było dostępne tylko w przestrzeni Windows.
Wiem, że purysta DBA powiedziałby mi od razu, że po wyjęciu z pudełka wersja SQL Server 2019 Linux ma kilka różnic pod względem funkcji w stosunku do swojego odpowiednika w systemie Windows, takich jak:
- Brak agenta serwera SQL
- Brak strumienia plików
- Brak rozszerzonych procedur zapisanych w systemie (np. xp_cmdshell)
Byłem jednak na tyle ciekawy, by pomyśleć „a co, jeśli można je porównać, przynajmniej do pewnego stopnia, z rzeczami, które obaj mogą zrobić?” Tak więc nacisnąłem spust na kilku maszynach wirtualnych, przygotowałem kilka prostych testów i zebrałem dane do zaprezentowania. Zobaczmy, jak się sprawy potoczą!
Rozważania wstępne
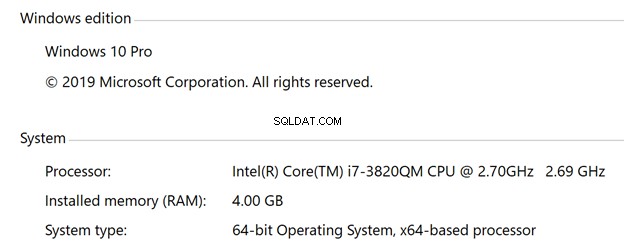
Oto specyfikacje każdej maszyny wirtualnej:
- Windows
- System operacyjny Windows 10
- 4 procesory wirtualne
- 4 GB pamięci RAM
- SSD 30 GB
- Linuks
- Serwer Ubuntu 20.04 LTS
- 4 procesory wirtualne
- 4 GB pamięci RAM
- SSD 30 GB


W przypadku wersji SQL Server wybrałem najnowszą wersję dla obu systemów operacyjnych:SQL Server 2019 Developer Edition CU10
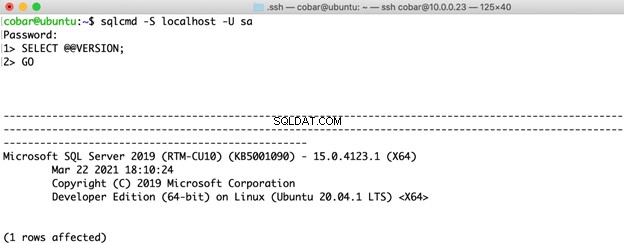
W każdym wdrożeniu jedyną włączoną opcją było natychmiastowe inicjowanie plików (domyślnie włączone w systemie Linux, włączone ręcznie w systemie Windows). Poza tym wartości domyślne pozostały przez resztę ustawień.
- W systemie Windows możesz włączyć natychmiastową inicjalizację pliku za pomocą kreatora instalacji.
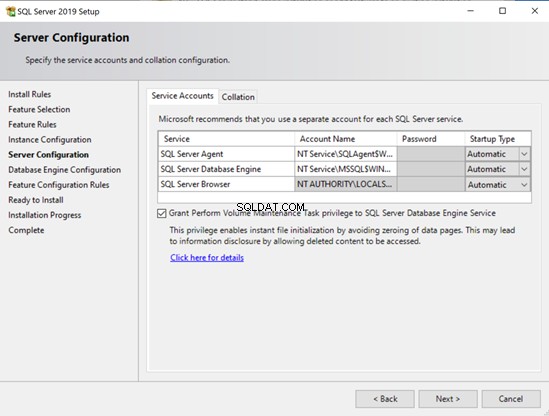
Ten post nie obejmuje specyfiki pracy Instant File Initialization w systemie Linux. Zostawię Ci jednak link do dedykowanego artykułu, który możesz przeczytać później (pamiętaj, że jest to trochę ciężkie od strony technicznej).
Co obejmuje test?
- W każdej instancji SQL Server 2019 wdrożyłem testową bazę danych i utworzyłem jedną tabelę z tylko jednym polem (NVARCHAR(MAX)).
- Używając losowo wygenerowanego ciągu 1 000 000 znaków, wykonałem następujące kroki:
- *Wstaw liczbę X wierszy do tabeli testowej.
- Zmierz, ile czasu zajęło wypełnienie instrukcji INSERT.
- Zmierz rozmiar plików MDF i LDF.
- Usuń wszystkie wiersze z tabeli testowej.
- **Zmierz, ile czasu zajęło wypełnienie instrukcji DELETE.
- Zmierz rozmiar pliku LDF.
- Upuść testową bazę danych.
- Utwórz ponownie testową bazę danych.
- Powtórz ten sam cykl.
*X wykonano dla 1000, 5000, 10 000, 25 000 i 50 000 wierszy.
**Wiem, że instrukcja TRUNCATE wykonuje tę pracę znacznie wydajniej, ale moim celem jest udowodnienie, jak dobrze każdy dziennik transakcji jest zarządzany w przypadku operacji usuwania w każdym systemie operacyjnym.
Możesz przejść do strony internetowej, której użyłem do wygenerowania losowego ciągu, jeśli chcesz zagłębić się w szczegóły.
Oto sekcje kodu TSQL, których użyłem do testów w każdym systemie operacyjnym:
Kody Linux TSQL
Tworzenie bazy danych i tabel
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= '/var/opt/mssql/data/test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= '/var/opt/mssql/data/test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.ubuntu(
long_string NVARCHAR(MAX) NOT NULL
)
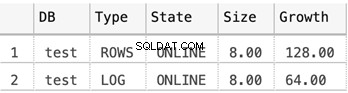
Rozmiar plików MDF i LDF dla testowej bazy danych
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
Poniższy zrzut ekranu pokazuje rozmiary plików danych, gdy w bazie danych nic nie jest przechowywane:
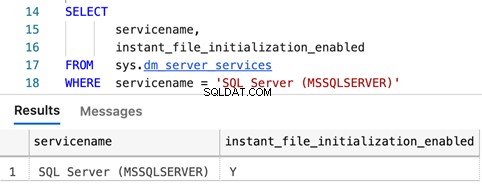
Pytania w celu ustalenia, czy włączona jest funkcja błyskawicznego inicjowania plików
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'

Kody Windows TSQL
Tworzenie bazy danych i tabel
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= 'S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= ''S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.windows(
long_string NVARCHAR(MAX) NOT NULL
)
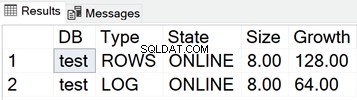
Rozmiar plików MDF i LDF dla testowej bazy danych
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
Poniższy zrzut ekranu pokazuje rozmiary plików danych, gdy w bazie danych nic nie jest przechowywane:
Zapytanie w celu ustalenia, czy włączona jest funkcja błyskawicznego inicjowania plików
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'
Skrypt do wykonania instrukcji INSERT:
@limit -> tutaj określiłem liczbę wierszy do wstawienia do tabeli testowej
W przypadku Linuksa, ponieważ skrypt wykonałem przy użyciu SQLCMD, umieściłem funkcję DATEDIFF na samym końcu. Informuje mnie, ile sekund zajmuje całe wykonanie (w przypadku wariantu Windows mogłem po prostu rzucić okiem na licznik czasu w SQL Server Management Studio).
Cały ciąg 1 000 000 znaków zamiast „XXXX”. Piszę to tylko po to, by ładnie to zaprezentować w tym poście.
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
DECLARE @i INT;
DECLARE @limit INT;
SET @StartTime = GETDATE();
SET @i = 0;
SET @limit = 1000;
WHILE(@i < @limit)
BEGIN
INSERT INTO test.dbo.ubuntu VALUES('XXXX');
SET @i = @i + 1
END
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Skrypt do wykonania instrukcji DELETE
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
SET @StartTime = GETDATE();
DELETE FROM test.dbo.ubuntu;
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Uzyskane wyniki
Wszystkie rozmiary są wyrażone w MB. Wszystkie pomiary czasu są wyrażone w sekundach.
| WSTAW godzinę | 1000 rekordów | 5000 rekordów | 10 000 rekordów | 25 000 rekordów | 50 000 rekordów |
| Linux | 4 | 23 | 43 | 104 | 212 |
| Windows | 4 | 28 | 172 | 531 | 186 |
| Rozmiar (MDF) | 1000 rekordów | 5000 rekordów | 10 000 rekordów | 25 000 rekordów | 50 000 rekordów |
| Linux | 264 | 1032 | 2056 | 5128 | 10184 |
| Windows | 264 | 1032 | 2056 | 5128 | 10248 |
| Rozmiar (LDF) | 1000 rekordów | 5000 rekordów | 10 000 rekordów | 25 000 rekordów | 50 000 rekordów |
| Linux | 104 | 264 | 360 | 552 | 148 |
| Windows | 136 | 328 | 392 | 456 | 584 |
| USUŃ czas | 1000 rekordów | 5000 rekordów | 10 000 rekordów | 25 000 rekordów | 50 000 rekordów |
| Linux | 1 | 1 | 74 | 215 | 469 |
| Windows | 1 | 63 | 126 | 357 | 396 |
| USUŃ rozmiar (LDF) | 1000 rekordów | 5000 rekordów | 10 000 rekordów | 25 000 rekordów | 50 000 rekordów |
| Linux | 136 | 264 | 392 | 584 | 680 |
| Windows | 200 | 328 | 392 | 456 | 712 |
Kluczowe spostrzeżenia
- Rozmiar płyty MDF był dość spójny w całym teście, nieznacznie się różnił na samym końcu (ale nic zbyt szalonego).
- Czasy INSERT były w większości przypadków lepsze w Linuksie, z wyjątkiem samego końca, kiedy Windows „wygrał rundę”.
- Rozmiar pliku dziennika transakcji był lepiej obsługiwany w systemie Linux po każdej rundzie WSTAWEK.
- Czasy DELETE były w większości przypadków lepsze w Linuksie, z wyjątkiem samego końca, gdzie Windows „wygrał rundę” (jest to ciekawe, że Windows wygrał również ostatnią rundę INSERT).
- Rozmiar plików dziennika transakcji po każdej rundzie DELETE był prawie równy pod względem wzlotów i upadków między nimi.
- Chciałbym przetestować ze 100 000 wierszy, ale trochę zabrakło mi miejsca na dysku, więc ograniczyłem je do 50 000.
Wniosek
Opierając się na wynikach uzyskanych z tego testu, powiedziałbym, że nie ma mocnych powodów, aby twierdzić, że wariant Linuksa działa wykładniczo lepiej niż jego odpowiednik w systemie Windows. Oczywiście nie jest to w żadnym wypadku formalny test, na którym można się oprzeć, aby podjąć taką decyzję. Jednak samo ćwiczenie było dla mnie wystarczająco interesujące.
Przypuszczam, że SQL Server 2019 dla Windows czasami jest trochę w tyle (niewiele) z powodu renderowania GUI w tle, co nie dzieje się po stronie Ubuntu Server.
Jeśli w dużym stopniu polegasz na funkcjach i możliwościach dostępnych wyłącznie w systemie Windows (przynajmniej w momencie pisania tego tekstu), z pewnością sięgnij po to. W przeciwnym razie raczej nie dokonasz złego wyboru, wybierając jeden z nich.



