Omówiliśmy już pewną teorię dotyczącą konfigurowania zawsze włączonych grup dostępności dla serwerów SQL opartych na systemie Linux. Obecny artykuł skupi się na praktyce.
Przedstawimy krok po kroku proces konfigurowania zawsze włączonych grup dostępności programu SQL Server między dwiema synchronicznymi replikami. Ponadto podkreślimy użycie repliki tylko do konfiguracji do automatycznego przełączania awaryjnego.
Zanim zaczniemy, polecam zapoznać się z poprzednim artykułem i odświeżyć swoją wiedzę.
Poniższy diagram projektu przedstawia dwuwęzłową replikę synchroniczną i replikę tylko do konfiguracji, które pomagają nam zapewnić automatyczne przełączanie awaryjne i ochronę danych.
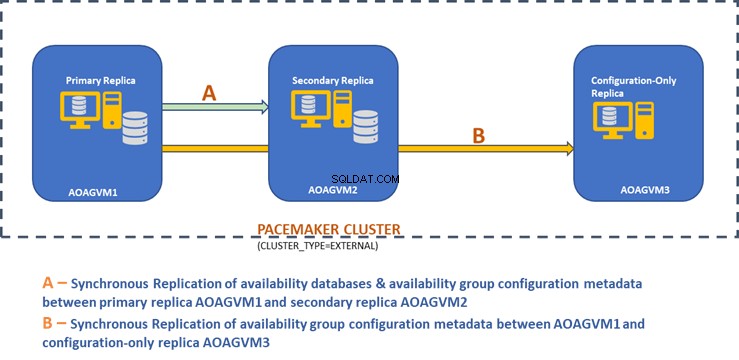
Zbadaliśmy ten projekt we wcześniej wspomnianym artykule, więc zapoznaj się z nim, aby uzyskać informacje, zanim przejdziemy do praktycznych zadań.
Zainstaluj SQL Server na systemach Ubuntu
Powyższy diagram projektowy wspomina o 3 systemach Ubuntu — aoagvm1 , aoagvm2 i aoagvm3 z zainstalowanymi instancjami SQL Server. Zapoznaj się z instrukcją instalacji SQL Server na Ubuntu – przykład dotyczy SQL Server 2019 na systemie Ubuntu 18.04. Możesz śmiało zainstalować SQL Server 2019 na wszystkich 3 węzłach (upewnij się, że zainstalowałeś tę samą wersję kompilacji).
Aby zaoszczędzić na kosztach licencji, można zainstalować wersję SQL Server Express dla repliki trzeciego węzła. Ta będzie działać jako replika tylko do konfiguracji bez hostowania żadnych baz danych dostępności.
Po zainstalowaniu SQL Server na wszystkich 3 węzłach, możemy skonfigurować Grupę Dostępności między nimi.
Konfiguruj grupy dostępności między trzema węzłami
Zanim przejdziesz dalej, zweryfikuj swoje środowisko:
- Upewnij się, że istnieje komunikacja między wszystkimi 3 węzłami.
- Sprawdź i zaktualizuj nazwę komputera dla każdego hosta, uruchamiając polecenie sudo vi /etc/hostname
- Zaktualizuj plik hosta o adres IP i nazwy węzłów dla każdego węzła. Możesz użyć polecenia sudo vi /etc/hosts aby to zrobić
- Upewnij się, że wszystkie instancje działają poza SQL Server 2017 CU1, jeśli nie używasz SQL Server 2019
Teraz zacznijmy konfigurować zawsze włączoną grupę dostępności programu SQL Server między 3 węzłami. Musimy włączyć funkcję Grupy dostępności we wszystkich 3 węzłach.
Uruchom poniższe polecenie (pamiętaj, że po tej akcji musisz ponownie uruchomić usługę SQL Server):
--Enable Availability Group feature
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
--Restart SQL Server service
sudo systemctl restart mssql-server
Wykonałem powyższe polecenie na węźle podstawowym. Należy to powtórzyć dla pozostałych dwóch węzłów.
Dane wyjściowe są poniżej – wprowadź nazwę użytkownika i hasło, gdy zostaniesz o to poproszony.
example@sqldat.com:~$ sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
SQL Server needs to be restarted to apply this setting. Please run
'systemctl restart mssql-server.service'.
example@sqldat.com:~$ systemctl restart mssql-server
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to restart 'mssql-server.service'.
Authenticating as: Ubuntu (aoagvm1)
Password:
Następnym krokiem jest włączenie opcji Zawsze włączone wydarzenia rozszerzone dla każdej instancji SQL Server. Chociaż jest to opcjonalny krok, musisz go włączyć, aby rozwiązać wszelkie problemy, które mogą pojawić się później. Połącz się z instancją SQL Server za pomocą SQLCMD i uruchom poniższe polecenie:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
Go
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
Go
Dane wyjściowe znajdują się poniżej:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
2>GO
1>
Po włączeniu tej opcji w głównym węźle repliki zrób to samo dla pozostałych węzłów aoagvm2 i aoagvm3.
Wystąpienia SQL Server działające w systemie Linux używają certyfikatów do uwierzytelniania komunikacji między dublowanymi punktami końcowymi. Tak więc następną opcją jest utworzenie certyfikatu w replice podstawowej aoagvm1 .
Najpierw tworzymy klucz główny i certyfikat. Następnie tworzymy kopię zapasową tego certyfikatu w pliku i zabezpieczamy plik kluczem prywatnym. Uruchom poniższy skrypt T-SQL na głównym węźle repliki:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Configure Certificates
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
Wynik:
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
3>GO
1>BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
2>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk',ENCRYPTION BY PASSWORD = 'example@sqldat.com');
3>GO
1>
Główny węzeł repliki ma teraz dwa nowe pliki. Jednym z nich jest plik certyfikatu dbm_certificate.cer oraz plik klucza prywatnego dbm_certificate.pvk w /var/opt/mssql/data/ lokalizacja.
Skopiuj powyższe dwa pliki do tej samej lokalizacji na pozostałych dwóch węzłach (AOAGVM2 i AOAGVM3), które będą uczestniczyć w konfiguracji grupy dostępności. Możesz użyć polecenia SCP lub dowolnego narzędzia innej firmy, aby skopiować te dwa pliki na serwer docelowy.
Gdy pliki zostaną skopiowane do pozostałych dwóch węzłów, przypiszemy uprawnienia do mssql użytkownika, aby uzyskać dostęp do tych plików na wszystkich 3 węzłach. W tym celu uruchom poniższe polecenie, a następnie wykonaj je dla trzeciego węzła aoagvm3 a także:
--Copy files to aoagvm2 node
cd /var/opt/mssql/data
scp dbm_certificate.* example@sqldat.com:var/opt/mssql/data/
--Grant permission to user mssql to access both newly created files
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
Stworzymy klucz główny i pliki certyfikatów za pomocą powyższych dwóch skopiowanych plików na pozostałych dwóch węzłach aoagvm2 i aoagvm3 . Uruchom poniższe polecenie na tych dwóch węzłach, aby utworzyć klucz główny :
--Create master key and certificate on remaining two nodes
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
Wykonałem powyższe polecenie na drugim węźle aoagvm2 aby utworzyć klucz główny i certyfikat . Spójrz na wynik wykonania. Upewnij się, że używasz tych samych haseł, co podczas tworzenia i tworzenia kopii zapasowej certyfikatu i klucza głównego.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'example@sqldat.com$terKEY';
2>CREATE CERTIFICATE dbm_certificate
3>FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
4>WITH PRIVATE KEY (FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = 'example@sqldat.com');
5>GO
1>
Uruchom powyższe polecenie na AOAGVM3 również węzeł.
Teraz konfigurujemy punkty końcowe dublowania baz danych – wcześniej stworzyliśmy dla nich certyfikaty. Dublowany punkt końcowy o nazwie hadr_endpoint powinien znajdować się na wszystkich 3 węzłach zgodnie z ich odpowiednim typem roli.
Ponieważ bazy danych dostępności są hostowane tylko na 2 węzłach aoagvm1 i aoagvm2, uruchomimy poniższe oświadczenie tylko na tych węzłach. Trzeci węzeł będzie działał jak świadek – więc po prostu zmienimy ROLĘ do świadka w poniższym skrypcie, a następnie uruchom T-SQL do trzeciego węzła aoagvm3 . Skrypt to:
--Configure database mirroring endpoint Hadr_endpoint on nodes aoagvm1 and aoagvm2
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
Oto dane wyjściowe powyższego polecenia w głównym węźle repliki. Połączyłem się z sqlcmd i wykonał go. Upewnij się, że zrobiłeś to samo na drugim węźle replik aoagvm2 również.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>CREATE ENDPOINT [Hadr_endpoint]
2>AS TCP (LISTENER_PORT = 5022)
3>FOR DATABASE_MIRRORING (ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
4>Go
1>ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
2>Go
1>
Po wykonaniu powyższego skryptu T-SQL na pierwszych 2 węzłach, musimy go zmodyfikować dla trzeciego węzła – zmień ROLA na WITNESS.
Uruchom poniższy skrypt, aby utworzyć punkt końcowy dublowania bazy danych na węźle monitora AOAGVM3 . Jeśli chcesz hostować tam bazy danych dostępności, uruchom powyższe polecenie również w węźle 3 replik. Ale upewnij się, że zainstalowałeś odpowiednią edycję SQL Server, aby osiągnąć tę możliwość.
Jeśli zainstalowałeś wersję SQL Server Express na 3 węźle, aby zaimplementować tylko konfiguracja replika , możesz skonfigurować tylko ROLĘ jako świadek dla tego węzła:
--Connect to the local SQL Server instance using sqlcmd
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
----Configure database mirroring endpoint Hadr_endpoint on 3rd node aoagvm3
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (ROLE = WITNESS, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES);
--Start the newly created endpoint on aoagvm3
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
Teraz musimy utworzyć grupę dostępności o nazwie ag1 .
Połącz się z instancją SQL Server za pomocą sqlcmd i uruchom poniższe polecenie w głównym węźle repliki aoagvm1 :
--Connect to the local SQL Server instance using sqlcmd hosted on primary replica node aoagvm1
sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
--Create availability group ag1
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'aoagvm1’ WITH (ENDPOINT_URL = N'tcp://aoagvm1:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm2' WITH (ENDPOINT_URL = N'tcp://aoagvm2:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC),
N'aoagvm3' WITH (ENDPOINT_URL = N'tcp://aoagvm3:5022',
AVAILABILITY_MODE = CONFIGURATION_ONLY);
--Assign required permission
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
Powyższy skrypt konfiguruje repliki grupy dostępności z poniższymi parametrami konfiguracyjnymi (właśnie użyliśmy ich w skrypcie T-SQL):
- RODZAJ KLASTRA =ZEWNĘTRZNY ponieważ konfigurujemy grupę dostępności na instalacjach SQL Server opartych na Linuksie
- SEEDING_MODE =AUTOMATYCZNY powoduje, że program SQL Server automatycznie tworzy bazę danych w każdej replice pomocniczej. Bazy danych dostępności nie zostaną utworzone w replice tylko do konfiguracji
- FAILOVER_MODE =ZEWNĘTRZNY zarówno dla replik podstawowych, jak i pomocniczych. oznacza to, że replika współdziała z zewnętrznym menedżerem zasobów klastra, takim jak Pacemaker
- AVAILABILITY_MODE =SYNCHRONOUS_COMMIT dla replik głównych i pomocniczych do automatycznego przełączania awaryjnego
- AVAILABILITY_MODE =CONFIGURATION_ONLY dla trzeciej repliki, która działa jako replika tylko do konfiguracji
Musimy również utworzyć login Pacemaker we wszystkich instancjach SQL Server. Do tego użytkownika należy przypisać ALTER , KONTROLA i WYŚWIETL DEFINICJA uprawnienia w grupie dostępności we wszystkich replikach. Aby przyznać uprawnienia, natychmiast uruchom poniższy skrypt T-SQL na wszystkich 3 węzłach replik. Najpierw utworzymy login Pacemaker. Następnie przypiszemy powyższe uprawnienia do tego loginu.
--Create pacemaker login on each SQL Server instance. Run below commands on all 3 SQL Server instances
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
--Grant permission to pacemaker login on newly created availability group. Run it on all 3 SQL Server instances
GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::ag1 TO pacemaker
GRANT VIEW SERVER STATE TO pacemaker
Po przypisaniu odpowiednich uprawnień do logowania Pacemaker we wszystkich 3 replikach, wykonujemy poniższe skrypty T-SQL, aby dołączyć do replik pomocniczych aoagvm2 i aoagvm3 do nowo utworzonej grupy dostępności ag1 . Uruchom poniższe polecenia w replikach pomocniczych aoagvm2 i aoagvm3 .
--Execute below commands on aoagvm2 and aoagvm3 to join availability group ag1
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
Poniżej znajdują się dane wyjściowe powyższych wykonań w węźle aoagvm2 . Pamiętaj, aby uruchomić go na aoagvm3 również węzeł.
example@sqldat.com:~$ sqlcmd -S localhost -U SA -P 'C0de!n$!ght$'
1>ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
2>Go
1>ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE;
2>Go
1>
W ten sposób skonfigurowaliśmy grupę dostępności. Teraz musimy dodać użytkownika lub testową bazę danych do tej grupy dostępności. Jeśli utworzyłeś już bazę danych użytkowników w replice węzła podstawowego, po prostu uruchom pełną kopię zapasową, a następnie pozwól, aby automatyczne inicjowanie przywróciło ją w węźle dodatkowym.
Dlatego uruchom poniższe polecenie:
--Run a full backup of test database or user database hosted on primary replica aoagvm1
BACKUP DATABASE [Test] TO DISK = N'/var/opt/mssql/data/Test_15June.bak';
Dodajmy tę bazę danych Test do grupy dostępności ag1 . Uruchom poniższą instrukcję T-SQL na węźle podstawowym aoagvm1 . Możesz użyć sqlcmd narzędzie do uruchamiania instrukcji T-SQL.
--Add user database or test database to the availability group ag1
ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [Test];
Bazę danych użytkownika lub testową bazę danych dodaną do grupy dostępności można zweryfikować, przeglądając pomocnicze wystąpienie programu SQL Server, niezależnie od tego, czy zostało utworzone w replikach pomocniczych, czy nie. Możesz użyć SQL Server Management Studio lub uruchomić prostą instrukcję T-SQL, aby pobrać szczegółowe informacje o tej bazie danych.
--Verify test database is created on a secondary replica or not. Run it on secondary replica aoagvm2.
SELECT * FROM sys.databases WHERE name = 'Test';
GO
Otrzymasz Test baza danych utworzona w replice pomocniczej.
W powyższym kroku grupa dostępności AlwaysOn została skonfigurowana między wszystkimi trzema węzłami. Jednak te węzły nie są jeszcze klastrowane. Naszym następnym krokiem jest zainstalowanie Rozrusznika serca klaster na nich. Następnie dodamy grupę dostępności ag1 jako zasób dla tego klastra.
Konfiguracja klastra PACEMAKER między trzema węzłami
Dlatego użyjemy zewnętrznego menedżera zasobów klastra PACEMAKER między wszystkimi 3 węzłami w celu obsługi klastra. Zacznijmy od włączenia portów zapory między wszystkimi 3 węzłami.
Otwórz porty zapory za pomocą poniższego polecenia:
--Run the below commands on all 3 nodes to open Firewall Ports
sudo ufw allow 2224/tcp
sudo ufw allow 3121/tcp
sudo ufw allow 21064/tcp
sudo ufw allow 5405/udp
sudo ufw allow 1433/tcp
sudo ufw allow 5022/tcp
sudo ufw reload
--If you don't want to open specific firewall ports then alternatively you can disable the firewall on all 3 nodes by running the below command (THIS IS ALTERNATE & OPTIONAL APPROACH)
sudo ufw disable
Zobacz wyniki — ten pochodzi z repliki podstawowej AOAGVM1 . Musisz wykonać powyższe polecenia na wszystkich trzech węzłach, jeden po drugim. Dane wyjściowe powinny być podobne.
example@sqldat.com:~$ sudo ufw allow 2224/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 3121/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 21064/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5405/udp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 1433/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw allow 5022/tcp
Rules updated
Rules updated (v6)
example@sqldat.com:~$ sudo ufw reload
Firewall not enabled (skipping reload)
Zainstaluj Rozrusznik i corosync pakiety na wszystkich 3 węzłach. Uruchom poniższe polecenie na każdym węźle – skonfiguruje Pacemaker , corosync oraz agent ds. szermierki .
--Install Pacemaker packages on all 3 nodes aoagvm1, aoagvm2 and aoagvm3 by running the below command
sudo apt-get install pacemaker pcs fence-agents resource-agents
Wynik jest ogromny – prawie 20 stron. Skopiowałem pierwsze i ostatnie kilka linijek, aby to zilustrować (możesz zobaczyć wszystkie zainstalowane pakiety):
example@sqldat.com:~$ sudo apt-get install pacemaker pcs fence-agents resource-agents
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
cluster-glue corosync fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4 libcpg4
libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker-cli-utils pacemaker-common pacemaker-resource-agents python-pexpect python-ptyprocess python-pycurl python3-bs4 python3-html5lib
python3-lxml python3-pycurl python3-webencodings rake ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean ruby-ethon ruby-ffi ruby-highline
ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4 ruby-power-assert ruby-rack
ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt ruby-tzinfo ruby2.5
rubygems-integration sg3-utils snmp unzip xsltproc zip
Suggested packages:
ipmitool python-requests python-suds apache2 | lighttpd | httpd lm-sensors snmp-mibs-downloader python-pexpect-doc libcurl4-gnutls-dev python-pycurl-dbg
python-pycurl-doc python3-genshi python3-lxml-dbg python-lxml-doc python3-pycurl-dbg ri ruby-dev bundler
The following NEW packages will be installed:
cluster-glue corosync fence-agents fonts-dejavu-core fonts-lato fonts-liberation ibverbs-providers javascript-common libcfg6 libcib4 libcmap4 libcorosync-common4
libcpg4 libcrmcluster4 libcrmcommon3 libcrmservice3 libdbus-glib-1-2 libesmtp6 libibverbs1 libjs-jquery liblrm2 liblrmd1 libnet-telnet-perl libnet1 libnl-3-200
libnl-route-3-200 libnspr4 libnss3 libopenhpi3 libopenipmi0 libpe-rules2 libpe-status10 libpengine10 libpils2 libplumb2 libplumbgpl2 libqb0 libquorum5 librdmacm1
libruby2.5 libsensors4 libsgutils2-2 libsnmp-base libsnmp30 libstatgrab10 libstonith1 libstonithd2 libtimedate-perl libtotem-pg5 libtransitioner2 libvotequorum8
libxml2-utils openhpid pacemaker pacemaker-cli-utils pacemaker-common pacemaker-resource-agents pcs python-pexpect python-ptyprocess python-pycurl python3-bs4
python3-html5lib python3-lxml python3-pycurl python3-webencodings rake resource-agents ruby ruby-activesupport ruby-atomic ruby-backports ruby-did-you-mean
ruby-ethon ruby-ffi ruby-highline ruby-i18n ruby-json ruby-mime-types ruby-mime-types-data ruby-minitest ruby-multi-json ruby-net-telnet ruby-oj ruby-open4
ruby-power-assert ruby-rack ruby-rack-protection ruby-rack-test ruby-rpam-ruby19 ruby-sinatra ruby-sinatra-contrib ruby-test-unit ruby-thread-safe ruby-tilt
ruby-tzinfo ruby2.5 rubygems-integration sg3-utils snmp unzip xsltproc zip
0 upgraded, 103 newly installed, 0 to remove and 2 not upgraded.
Need to get 19.6 MB of archives.
After this operation, 86.0 MB of additional disk space will be used.
Do you want to continue? [Y/n] Y
Get:1 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 fonts-lato all 2.0-2 [2698 kB]
Get:2 https://azure.archive.ubuntu.com/ubuntu bionic/main amd64 libdbus-glib-1-2 amd64 0.110-2 [58.3 kB]
…………
--------
Po Rozruszniku serca instalacja klastra została zakończona, hacluster użytkownik zostanie uzupełniony automatycznie po uruchomieniu poniższego polecenia:
example@sqldat.com:~$ cat /etc/passwd|grep hacluster
hacluster:x:111:115::/var/lib/pacemaker:/usr/sbin/nologin
Teraz możemy ustawić hasło dla domyślnego użytkownika utworzonego podczas instalacji Pacemaker i Corosync pakiety. Upewnij się, że używasz tego samego hasła na wszystkich 3 węzłach. Użyj poniższego polecenia:
--Set default user password on all 3 nodes
sudo passwd hacluster
Wprowadź hasło, gdy zostaniesz o to poproszony:
example@sqldat.com:~$ sudo passwd hacluster
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Następnym krokiem jest włączenie i uruchomienie pcsd usługi i Rozrusznik na wszystkich 3 węzłach. Pozwala wszystkim 3 węzłom na dołączenie do klastra po ponownym uruchomieniu. Uruchom poniższe polecenie we wszystkich 3 węzłach, aby wykonać ten krok:
--Enable and start pcsd service and pacemaker
sudo systemctl enable pcsd
sudo systemctl start pcsd
sudo systemctl enable pacemaker
Zobacz wykonanie w replice podstawowej aoagvm1 . Upewnij się, że uruchomiłeś go również na pozostałych dwóch węzłach.
--Enable pcsd service
example@sqldat.com:~$ sudo systemctl enable pcsd
Synchronizing state of pcsd.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pcsd
--Start pcsd service
example@sqldat.com:~$ sudo systemctl start pcsd
--Enable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
Skonfigurowaliśmy Rozrusznik pakiety. Teraz tworzymy klaster.
Najpierw upewnij się, że nie masz żadnych wcześniej skonfigurowanych klastrów w tych systemach. Możesz zniszczyć wszelkie istniejące konfiguracje klastra ze wszystkich węzłów, uruchamiając poniższe polecenia. Pamiętaj, że usunięcie dowolnej konfiguracji klastra zatrzyma wszystkie usługi klastra i wyłączy Rozrusznik usługa – należy ją ponownie włączyć.
--Destroy previously configured clusters to clean the systems
sudo pcs cluster destroy
--Reenable Pacemaker
sudo systemctl enable pacemaker
Poniżej znajdują się dane wyjściowe z głównego węzła repliki aoagvm1 .
--Destroy previously configured clusters to clean the systems
example@sqldat.com:~$ sudo pcs cluster destroy
Shutting down pacemaker/corosync services...
Killing any remaining services...
Removing all cluster configuration files...
--Reenable Pacemaker
example@sqldat.com:~$ sudo systemctl enable pacemaker
Synchronizing state of pacemaker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable pacemaker
Następnie tworzymy 3-węzłowy klaster między wszystkimi 3 węzłami z repliki podstawowej aoagvm1 . Ważne :wykonaj poniższe polecenia tylko z węzła podstawowego !
--Create cluster. Modify below command with your node names, hacluster password and clustername
sudo pcs cluster auth <node1> <node2> <node3> -u hacluster -p <password for hacluster>
sudo pcs cluster setup --name <clusterName> <node1> <node2...> <node3>
sudo pcs cluster start --all
sudo pcs cluster enable --all
Zobacz dane wyjściowe w głównym węźle repliki:
example@sqldat.com:~$ sudo pcs cluster auth aoagvm1 aoagvm2 aoagvm3 -u hacluster -p hacluster
aoagvm1: Authorized
aoagvm2: Authorized
aoagvm3: Authorized
example@sqldat.com:~$ sudo pcs cluster setup --name aoagvmcluster aoagvm1 aoagvm2 aoagvm3
Destroying cluster on nodes: aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Stopping Cluster (pacemaker)...
aoagvm2: Stopping Cluster (pacemaker)...
aoagvm3: Stopping Cluster (pacemaker)...
aoagvm1: Successfully destroyed cluster
aoagvm2: Successfully destroyed cluster
aoagvm3: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'aoagvm1', 'aoagvm2', 'aoagvm3'
aoagvm1: successful distribution of the file 'pacemaker_remote authkey'
aoagvm2: successful distribution of the file 'pacemaker_remote authkey'
aoagvm3: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
aoagvm1: Succeeded
aoagvm2: Succeeded
aoagvm3: Succeeded
Synchronizing pcsd certificates on nodes aoagvm1, aoagvm2, aoagvm3...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
Restarting pcsd on the nodes to reload the certificates...
aoagvm1: Success
aoagvm2: Success
aoagvm3: Success
example@sqldat.com:~$ sudo pcs cluster start --all
aoagvm1: Starting Cluster...
aoagvm2: Starting Cluster...
aoagvm3: Starting Cluster...
example@sqldat.com:~$ sudo pcs cluster enable --all
aoagvm1: Cluster Enabled
aoagvm2: Cluster Enabled
aoagvm3: Cluster Enabled
Ogrodzenie jest jedną z podstawowych konfiguracji podczas używania klastra PACEMAKER w środowisku produkcyjnym. Należy skonfigurować ogrodzenie klastra, aby nie doszło do uszkodzenia danych w przypadku awarii .
Istnieją dwa rodzaje realizacji ogrodzeń:
- Na poziomie zasobów – zapewnia, że węzeł nie może korzystać z jednego lub więcej zasobów.
- Na poziomie węzła – zapewnia, że węzeł w ogóle nie uruchamia żadnych zasobów.
Zwykle używamy STONITH jako konfiguracja ogrodzenia – ogrodzenie na poziomie węzła dla PACEMAKER .
Kiedy PACEMAKER nie może określić stanu węzła lub zasobu w węźle, odgrodzenie ponownie przywraca znany stan klastra. Aby to osiągnąć, PACEMAKER wymaga od nas włączenia STONITH , co oznacza Zastrzel drugi węzeł w głowie .
W tym artykule nie będziemy koncentrować się na konfiguracji ogrodzenia, ponieważ konfiguracja ogrodzenia na poziomie węzła zależy w dużym stopniu od indywidualnego środowiska. W naszym scenariuszu wyłączymy go, uruchamiając poniższe polecenie:
--Disable fencing (STONITH)
sudo pcs property set stonith-enabled=false
Jeśli jednak planujesz używać Rozrusznika w środowisku produkcyjnym należy zaplanować wdrożenie STONITH w zależności od środowiska i pozostawić je włączone.
Następnie ustawimy kilka podstawowych właściwości klastra:Cluster-recheck-interval, start-failure-is-fatal, i limit czasu awarii .
Zgodnie z MSDN, jeśli przekroczono limit czasu awarii jest ustawiony na 60 sekund, a interwał ponownego sprawdzania klastra jest ustawiony na 120 sekund, ponowne uruchomienie następuje w odstępie większym niż 60 sekund, ale krótszym niż 120 sekund. Firma Microsoft zaleca ustawienie wartości dla interwału ponownego sprawdzania klastra większa niż wartość czasu awarii . Inne ustawienie start-failure-is-fatal musi być ustawiony jako prawda . W przeciwnym razie klaster nie zainicjuje przełączania awaryjnego repliki głównej do odpowiedniej repliki wtórnej w przypadku wystąpienia trwałych przestojów.
Uruchom poniższe polecenia, aby skonfigurować wszystkie 3 ważne właściwości klastra:
--Set cluster property cluster-recheck-interval to 2 minutes
sudo pcs property set cluster-recheck-interval=2min
--Set start-failure-is-fatal to True
sudo pcs property set start-failure-is-fatal=true
--Set failure-timeout to 60 seconds. Ag1 is the name of the availability group. Change this name with your availability group name.
pcs resource update ag1 meta failure-timeout=60s
Zintegruj grupę dostępności z grupą klastrów Pacemaker
W tym miejscu naszym celem jest opisanie procesu integracji nowo utworzonej grupy dostępności ag1 do nowo utworzonego Rozrusznika grupa klastrów.
Najpierw zainstalujemy agenta zasobów SQL Server w celu integracji z Pacemakerem na wszystkich 3 węzłach:
--Install SQL Server Resource Agent on all 3 nodes
sudo apt-get install mssql-server-ha
Powyższe polecenie wykonałem na wszystkich 3 węzłach. Zobacz dane wyjściowe poniżej (pobrane z aoagvm1 ):
--Install SQL Server resource agent for integration with Pacemaker
example@sqldat.com:~$ sudo apt-get install mssql-server-ha
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
mssql-server-ha
0 upgraded, 1 newly installed, 0 to remove, and 2 not upgraded.
Need to get 1486 kB of archives.
After this operation, 9151 kB of additional disk space will be used.
Get:1 https://packages.microsoft.com/ubuntu/16.04/mssql-server-preview xenial/main amd64 mssql-server-ha amd64 15.0.1600.8-1 [1486 kB]
Fetched 1486 kB in 0s (4187 kB/s)
Selecting previously unselected package mssql-server-ha.
(Reading database ... 90430 files and directories currently installed.)
Preparing to unpack .../mssql-server-ha_15.0.1600.8-1_amd64.deb ...
Unpacking mssql-server-ha (15.0.1600.8-1) ...
Setting up mssql-server-ha (15.0.1600.8-1) ...
Powtórz powyższe kroki na pozostałych 2 węzłach.
Stworzyliśmy już Rozrusznik zaloguj się we wszystkich instancjach SQL Server hostowanych na 3 węzłach po skonfigurowaniu grupy dostępności ag1 . Teraz przypisujemy rolę sysadmin do wszystkich 3 instancji SQL Server. Możesz połączyć się za pomocą sqlcmd do uruchomienia tego polecenia T-SQL. If you have not created the Pacemaker login, you can run the below command to do it.
--Create a pacemaker login if you missed creating it in the above section.
USE master
Go
CREATE LOGIN pacemaker WITH PASSWORD = 'example@sqldat.com@12'
Go
--Assign sysadmin role to pacemaker login on all 3 nodes. Run this T-SQL on all 3 SQL Server instances.
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemaker]
We must save the above SQL Server Pacemaker login and its credentials on all 3 nodes. Run the below command there:
--Save pacemaker login credentials on all 3 nodes by executing below commands on each node
echo 'pacemaker' >> ~/pacemaker-passwd
echo 'example@sqldat.com@12' >> ~/pacemaker-passwd
sudo mv ~/pacemaker-passwd /var/opt/mssql/secrets/passwd
sudo chown root:root /var/opt/mssql/secrets/passwd
sudo chmod 400 /var/opt/mssql/secrets/passwd
We will create the Availability Group Resource as master/subordinate .
We are using the pcs resource create command to create the Availability Group resource and set its properties. The following command will create the ocf:mssql:ag resource for the Availability Group ag1 .
The Pacemaker resource agent automatically sets the value of REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT on the Availability Group based on the Availability Group’s configuration during the creation of the Availability Group resource.
Execute the below command:
--Create availability group resource ocf:mssql:ag
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=ag1 meta failure-timeout=30s --master meta notify=true
Next, we create a virtual IP resource in Pacemaker . Ensure you have the unused private IP address from your network . Replace the IP value with your virtual IP address. This IP will point to the primary replica and you can use it to make databases connections with active nodes.
The command is below:
--Configure virtual IP resource
sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=10.50.0.7
We are adding the colocation constraint and ordering constraint to the Pacemaker cluster configuration . These constraints help the virtual IP resource to make decisions on resources, e.g., where they should run.
Constraints have some scores, and Pacemaker uses these scores to make decisions. Scores are calculated per resource. The cluster resource manager chooses the node with the highest score for a particular resource.
The colocation constraint has an implicit ordering constraint . We need to add an ordering constraint to prevent the IP address from temporarily pointing to the node with the pre-failover secondary . Ordering constraint ensures the cluster comes online in a particular sequential manner.
Run the below commands to add colocation constraint and ordering constraint to the cluster.
--Add colocation constraint
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=Master
--Add ordering constraint
sudo pcs constraint order promote ag_cluster-master then start virtualip
Hence, Two-Node Synchronous Replicas (aoagvm1 &aoagvm2) and a Configuration-Only Replica (aoagvm3) on PACEMAKER Cluster between 3-Node Ubuntu Systems has been completed.
We can test the configuration to validate the automatic failover. Run the below command to check the status of the Pacemaker cluster. The command also initiates the Availability Group failover.
Remember, once you couple your Availability Group with the PACEMAKER cluster, you cannot use T-SQL statements to initiate the Availability Group failovers. You can also shut down the primary replica to initiate the automatic failover.
The command is the following:
--Validate the PACEMAKER cluster configuration
sudo pcs status
--Initiate availability group failover to verify AOAG configuration
sudo pcs resource move ag_cluster-master aoagvm2 –master
Wniosek
This article was meant to help you understand the configuration of the Two-Node Synchronous Replicas and a Configuration-Only Replica on PACEMAKER Cluster. We hope that you got useful information that will help you in your workflow.
Always plan all steps carefully and do proper testing in a lower life cycle before deploying to your production environment.
We’ll be glad to hear your thoughts about this topic. Feel free to leave your feedback in a comment section.