Relacyjne bazy danych reprezentują dane organizacji w tabelach, które używają kolumn z różnymi typami danych, co pozwala na przechowywanie prawidłowych wartości. Deweloperzy i administratorzy baz danych muszą znać i rozumieć odpowiedni typ danych dla każdej kolumny, aby uzyskać lepszą wydajność zapytań.
Ten artykuł zajmie się popularnymi typami danych VARCHAR() i NVARCHAR(), ich porównaniem i przeglądami wydajności w SQL Server.
VARCHAR [ ( n | maks ) ] w SQL
VARCHAR typ danych reprezentuje nie Unicode typ danych typu string o zmiennej długości. Możesz w nim przechowywać litery, cyfry i znaki specjalne.
- N reprezentuje rozmiar łańcucha w bajtach.
- Kolumna typu danych VARCHAR przechowuje maksymalnie 8000 znaków innych niż Unicode.
- Typ danych VARCHAR zajmuje 1 bajt na znak. Jeśli nie określisz jawnie wartości N, zajmuje to 1 bajt pamięci.
Uwaga:nie myl N z wartością reprezentującą liczbę znaków w ciągu.
Poniższe zapytanie definiuje typ danych VARCHAR ze 100 bajtami danych.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Zwraca długość jako 17, ponieważ 1 bajt na znak, łącznie ze znakiem spacji.
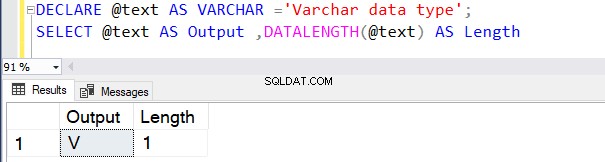
Poniższe zapytanie definiuje typ danych VARCHAR bez wartości N . Dlatego SQL Server traktuje domyślną wartość jako 1 bajt, jak pokazano poniżej.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
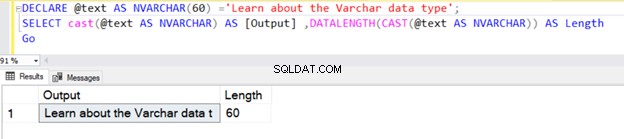
Możemy również użyć VARCHAR za pomocą funkcji CAST lub CONVERT. Na przykład w poniższych dwóch przykładach zadeklarowaliśmy zmienną o długości 100 bajtów, a później użyliśmy operatora CAST.
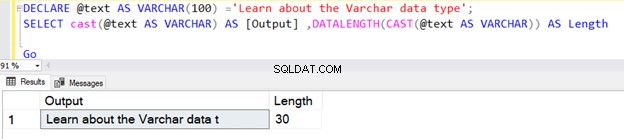
Pierwsze zapytanie zwraca długość 30, ponieważ nie określiliśmy N w typie danych operatora CAST VARCHAR. Domyślna długość to 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
Jeśli jednak długość ciągu jest mniejsza niż 30, przyjmuje rzeczywisty rozmiar ciągu.

NVARCHAR [ ( n | maks ) ] w SQL
NVARCHAR typ danych jest dla Unicode typ danych znakowych o zmiennej długości. Tutaj N odnosi się do zestawu znaków języka narodowego i służy do definiowania ciągu Unicode. Możesz przechowywać zarówno znaki inne niż Unicode, jak i Unicode (japońskie Kanji, koreańskie Hangul itp.).
- N reprezentuje rozmiar łańcucha w bajtach.
- Może przechowywać maksymalnie 4000 znaków Unicode i nie Unicode.
- Typ danych VARCHAR zajmuje 2 bajty na znak. Zajmuje 2 bajty pamięci, jeśli nie określisz żadnej wartości dla N.
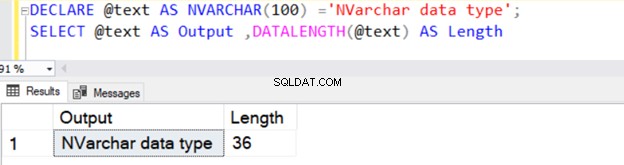
Poniższe zapytanie definiuje typ danych VARCHAR ze 100 bajtami danych.
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Zwraca długość łańcucha 36, ponieważ NVARCHAR zajmuje 2 bajty na pamięć znaków.
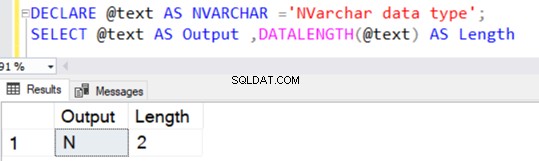
Podobnie do typu danych VARCHAR, NVARCHAR ma również domyślną wartość 1 znaku (2 bajty) bez określania jawnej wartości dla N.
Jeśli zastosujemy konwersję NVARCHAR za pomocą funkcji RZUĆ lub KONWERTUJ bez wyraźnej wartości N, wartość domyślna to 30 znaków, tj. 60 bajtów.
Przechowywanie wartości Unicode i innych niż Unicode w typie danych VARCHAR
Załóżmy, że mamy tabelę, w której rejestrowane są opinie klientów z portalu e-zakupów. W tym celu mamy tabelę SQL z następującym zapytaniem.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
W tej tabeli wstawiamy kilka przykładowych rekordów w języku angielskim, japońskim i hindi. Typ danych dla [Komentarz] to VARCHAR i [Nowy komentarz] to NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
Zapytanie zostało wykonane pomyślnie i podczas wybierania z niego wartości wyświetla następujące wiersze. W przypadku wiersza 2 i 3 nie rozpoznaje danych, jeśli nie są one w języku angielskim.
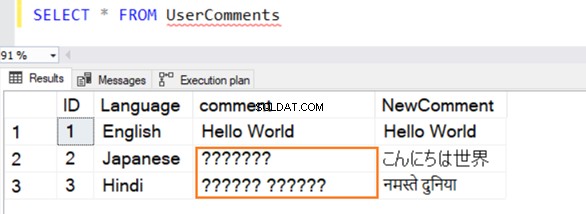
Typy danych VARCHAR i NVARCHAR:porównanie wydajności
Nie powinniśmy mieszać użycia typów danych VARCHAR i NVARCHAR w predykatach JOIN lub WHERE. Unieważnia istniejące indeksy, ponieważ SQL Server wymaga tych samych typów danych po obu stronach JOIN. SQL Server próbuje wykonać niejawną konwersję za pomocą funkcji CONVERT_IMPLICIT() w przypadku niezgodności.
SQL Server używa pierwszeństwa typu danych do określenia docelowego typu danych. NVARCHAR ma wyższy priorytet niż typ danych VARCHAR. Dlatego podczas konwersji typu danych SQL Server konwertuje istniejące wartości VARCHAR na NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Teraz wykonajmy dwie instrukcje SELECT, które pobierają rekordy zgodnie z ich typami danych.
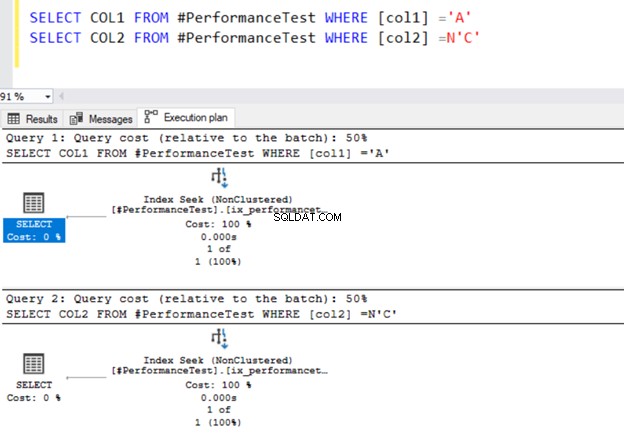
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Oba zapytania używają operatora wyszukiwania indeksu i indeksy, które zdefiniowaliśmy wcześniej.
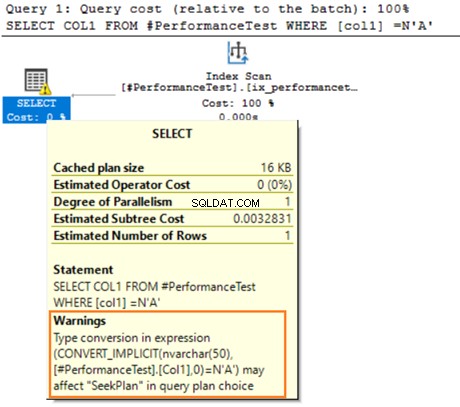
Teraz przełączamy wartości typu danych do porównania na predykat WHERE. Kolumna 1 ma typ danych VARCHAR, ale określamy N’A’, aby umieścić go jako typ danych NVARCHAR.
Podobnie, col2 jest typem danych NVARCHAR i określamy wartość „C”, która odnosi się do typu danych VARCHAR.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'W rzeczywistym planie wykonania zapytania otrzymujesz skan indeksu, a instrukcja SELECT ma symbol ostrzegawczy.
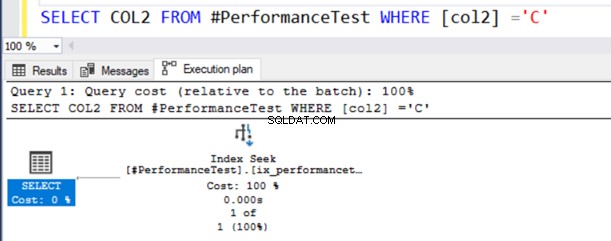
To zapytanie działa dobrze, ponieważ typ danych NVARCHAR() może mieć zarówno wartości Unicode, jak i inne niż Unicode.
Teraz drugie zapytanie wykorzystuje skanowanie indeksu i wyświetla symbol ostrzegawczy dla operatora SELECT.
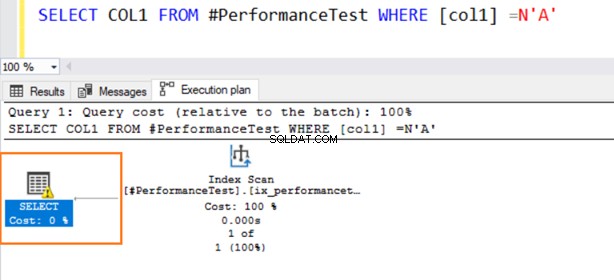
Umieść wskaźnik myszy nad instrukcją SELECT, która wyświetla ostrzeżenie o niejawnej konwersji. SQL Server nie mógł prawidłowo użyć istniejącego indeksu. Wynika to z różnych algorytmów sortowania danych zarówno dla typów danych VARCHAR, jak i NVARCHAR.
Jeśli tabela ma miliony wierszy, SQL Server musi wykonać dodatkową pracę i przekonwertować dane przy użyciu konwersji danych niejawnie. Może to negatywnie wpłynąć na wydajność zapytania. Dlatego podczas optymalizacji zapytań należy unikać mieszania i dopasowywania tych typów danych.
Wniosek
Należy przejrzeć wymagania dotyczące danych podczas projektowania tabel bazy danych i odpowiednich typów danych kolumn. Zwykle serwery typu danych VARCHAR większość wymagań dotyczących danych. Jeśli jednak musisz przechowywać w kolumnie zarówno typy danych Unicode, jak i inne niż Unicode, możesz rozważyć użycie NVARCHAR. Jednak przed podjęciem ostatecznej decyzji należy sprawdzić jego wpływ na wydajność, rozmiar pamięci.