SQL Server Transactional Replication jest jedną z najczęstszych technik replikacji używanych do kopiowania lub dystrybucji danych w wielu miejscach docelowych.
W poprzednich artykułach omówiliśmy replikację SQL Server, jej wewnętrzne działanie i sposób konfiguracji replikacji za pomocą Kreatora replikacji lub podejścia T-SQL. Teraz skupiamy się na problemach z replikacją SQL i poprawnym ich rozwiązywaniu.
Problemy z replikacją SQL
Większość klientów korzystających z replikacji transakcyjnej SQL Server koncentruje się głównie na uzyskaniu danych w czasie zbliżonym do rzeczywistego dostępnych w instancjach bazy danych Subskrybenta. Dlatego administrator zarządzający replikacją powinien być świadomy różnych możliwych problemów związanych z replikacją SQL. Ponadto administrator musi być w stanie rozwiązać te problemy w krótkim czasie.
Możemy podzielić wszystkie problemy z replikacją SQL na poniższe kategorie (na podstawie mojego doświadczenia):
Problemy z konfiguracją
- Maksymalny rozmiar replikacji tekstu
- Usługa agenta SQL Server nie jest ustawiona na uruchamianie trybu automatycznego
- Instancje niemonitorowanej replikacji przechodzą w stan niezainicjowanych subskrypcji
- Znane problemy w SQL Server
Problemy z uprawnieniami
- Problemy z uprawnieniami do zadań SQL Server Agent
- Poświadczenia zadania Snapshot Agent nie mogą uzyskać dostępu do ścieżki folderu Snapshot
- Poświadczenia pracy agenta czytnika dzienników nie mogą połączyć się z bazą danych wydawców/dystrybucji
- Poświadczenia pracy agenta dystrybucji nie mogą połączyć się z bazą danych dystrybucji/subskrybentów
Problemy z połączeniem
- Serwer wydawcy nie został znaleziony lub był niedostępny
- Serwer dystrybucji nie został znaleziony lub był niedostępny
- Serwer subskrybenta nie został znaleziony lub był niedostępny
Problemy z integralnością danych
- Błędy naruszenia klucza głównego lub klucza unikalnego
- Błędy Nie znaleziono wiersza
- Błędy związane z kluczem obcym lub innymi błędami naruszenia ograniczeń
Problemy z wydajnością
- Długotrwałe aktywne transakcje w bazie danych wydawcy
- Zbiorcze operacje INSERT/UPDATE/DELETE na artykułach
- Ogromne zmiany danych w ramach jednej transakcji
- Blokowania w bazie danych dystrybucji
Problemy związane z korupcją
- Uszkodzenia bazy danych wydawców
- Uszkodzone pliki dziennika transakcji wydawcy
- Uszkodzenia bazy danych dystrybucji
- Uszkodzenia bazy danych subskrybentów
Przygotowanie środowiska DEMO
Zanim zagłębimy się w szczegóły dotyczące kwestii replikacji SQL, musimy przygotować nasze środowisko do demonstracji. Jak omówiłem w moich poprzednich artykułach, wszelkie zmiany danych zachodzące w bazie danych subskrybentów w replikacji transakcyjnej nie będą widoczne bezpośrednio w bazie danych wydawcy. W związku z tym zamierzamy wprowadzić pewne modyfikacje bezpośrednio w bazie danych subskrybentów w celach edukacyjnych.
Zachowaj szczególną ostrożność i nie modyfikuj niczego w produkcyjnych bazach danych. Wpłynie to na integralność danych baz danych subskrybenta. Wezmę skrypty kopii zapasowej dla każdej wykonanej zmiany i użyję tych skryptów, aby naprawić problemy z replikacją SQL.
Zmiana 1 – wstawianie rekordów do tabeli Person.ContactType
Przed wstawieniem rekordów do Person.ContacType tabeli, przyjrzyjmy się strukturze tabeli, kilku domyślnym ograniczeniom i rozszerzonym właściwościom zredagowanym w poniższym skrypcie:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
Wybrałem tę tabelę, ponieważ ma mniej kolumn. Jest wygodniejszy do celów testowych. Sprawdźmy teraz, co mamy na temat jego struktury:
- Identyfikator typu kontaktu jest zdefiniowana jako KOLUMNA TOŻSAMOŚCI – automatycznie wygeneruje wartości klucza podstawowego, a NIE DO REPLIKACJI.
- NIE DO REPLIKACJI to specjalna właściwość, której można używać w odniesieniu do różnych typów obiektów, takich jak tabele, ograniczenia, takie jak ograniczenia klucza obcego, ograniczenia sprawdzania, wyzwalacze i kolumny tożsamości w przypadku wydawcy lub subskrybenta, podczas korzystania wyłącznie z dowolnej metodologii replikacji. Pozwala DBA zaplanować lub wdrożyć replikację, aby zapewnić, że niektóre funkcje będą zachowywać się inaczej w Wydawcy/Abonencie podczas korzystania z replikacji.
- W naszym przypadku instruujemy SQL Server, aby używał wartości IDENTITY generowanych tylko w bazie danych Publisher. Właściwość IDENTITY nie powinna być używana w Person.ContactType w bazie danych Subskrybentów. Podobnie, możemy zmodyfikować ograniczenia lub wyzwalacze, aby zachowywały się inaczej, gdy replikacja jest skonfigurowana za pomocą tej opcji.
- 2 inne kolumny NOT NULL są dostępne w tabeli.
- Tabela ma klucz podstawowy zdefiniowany w ContactTypeId . Dla przypomnienia, klucz podstawowy jest obowiązkowym wymogiem replikacji. Bez tego na stole nie bylibyśmy w stanie odtworzyć artykułu ze stołu.
Teraz wstawmy przykładowy rekord do osoby .Typ kontaktu tabela w AdventureWorks_REPL baza danych:
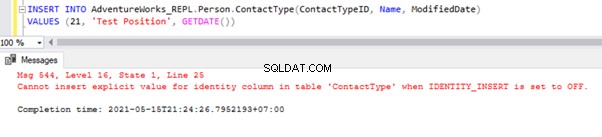
Bezpośrednie INSERT w tabeli zakończy się niepowodzeniem w bazie danych subskrybenta, ponieważ właściwość tożsamości jest wyłączona tylko dla replikacji przez opcję NIE DO REPLIKACJI. Ilekroć ręcznie wykonujemy operację INSERT, nadal musimy użyć opcji SET IDENTITY_INSERT w następujący sposób:
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Po dodaniu opcji SET IDENTITY_INSERT możemy pomyślnie WSTAWIĆ rekord do Person.ContactType tabela.
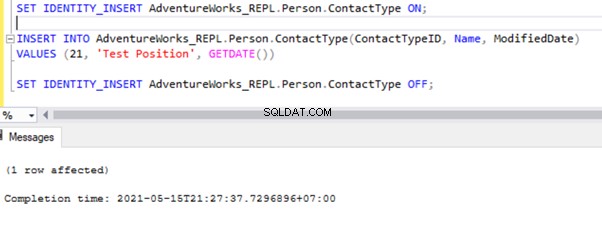
Wykonanie SELECT w tabeli pokazuje nowo wstawiony rekord:
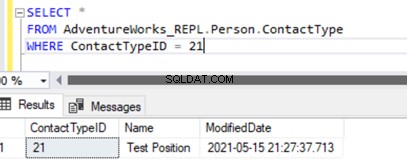
Dodaliśmy nowy rekord tylko do bazy subskrybentów, który nie jest dostępny w bazie danych wydawców w Person.ContactType tabela.
Wykonywanie SELECT w tej samej tabeli bazy danych wydawcy nie pokazuje żadnych rekordów. W związku z tym wszelkie zmiany wprowadzone w bazie danych subskrybentów nie są replikowane do bazy danych wydawcy.
Zmiana 2 – usuwanie 2 rekordów z tabeli Person.ContactType
Trzymamy się naszego znanego Person.ContactType stół. Przed usunięciem rekordów z bazy danych subskrybentów musimy sprawdzić, czy te rekordy istnieją zarówno u wydawcy, jak i subskrybenta. Zobacz poniżej:
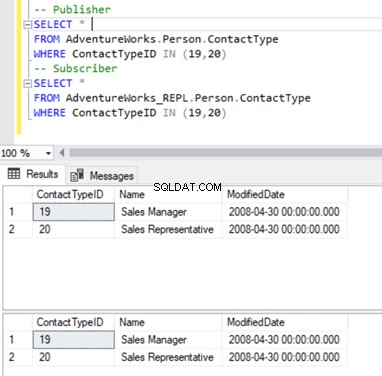
Teraz możemy usunąć te 2 ContactTypeId używając następującego oświadczenia:
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
Powyższy skrypt pozwala nam usunąć 2 rekordy z Person.ContactType tabela w bazie danych subskrybentów:
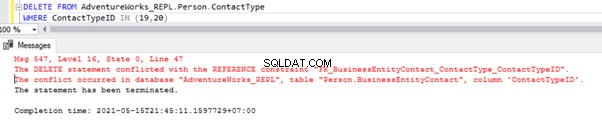
Mamy odwołanie do klucza obcego, które zapobiega usunięciu tych 2 rekordów z Person.ContactType stół. Możemy obsłużyć ten scenariusz, tymczasowo wyłączając ograniczenie klucza obcego w tabeli podrzędnej. Skrypt znajduje się poniżej:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Po wyłączeniu kluczy obcych możemy pomyślnie usuwać rekordy z Person.ContactType tabela:
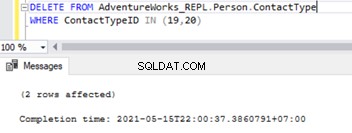
Zmodyfikowało to również ograniczenie referencyjne klucza obcego w dwóch tabelach. Możemy spróbować zasymulować problemy z replikacją SQL w oparciu o ten scenariusz.
W naszym obecnym scenariuszu wiemy, że Person.ContactType tabela nie miała zsynchronizowanych danych między wydawcą a subskrybentem.
Uwierz mi, w kilku środowiskach produkcyjnych programiści lub administratorzy baz danych dokonują pewnych poprawek danych w bazie danych subskrybenta. podobnie jak wszystkie zmiany, które wprowadziliśmy wcześniej, powodowały problemy z integralnością danych w bazach danych wydawcy i subskrybenta w tej samej tabeli. Jako DBA potrzebuję prostszego mechanizmu weryfikacji tego rodzaju rozbieżności. W przeciwnym razie życie DBA byłoby żałosne.
Oto rozwiązanie firmy Microsoft, które pozwala nam weryfikować rozbieżności danych w tabelach wydawcy i subskrybenta. Tak, dobrze zgadłeś. To narzędzie TableDiff, które omówiliśmy w poprzednich artykułach.
Narzędzie TableDiff
Narzędzie TableDiff jest używane głównie w środowiskach replikacji. Możemy go również użyć w innych przypadkach, w których musimy porównać 2 tabele SQL Server pod kątem braku zbieżności. Możemy je porównać i zidentyfikować różnice między tymi 2 tabelami. Następnie narzędzie pomaga zsynchronizować Miejsce docelowe stół do Źródła stół generując niezbędne skrypty INSERT/UPDATE/DELETE.
TableDiff to samodzielny program tablediff.exe instalowany domyślnie w C:\Program Files\Microsoft SQL Server\130\COM po zainstalowaniu składników replikacji. Należy pamiętać, że domyślna ścieżka może się różnić w zależności od parametrów instalacji programu SQL Server. Liczba 130 w ścieżce wskazuje wersję SQL Server (SQL Server 2016). W związku z tym będzie się różnić dla każdej innej wersji instalacji SQL Server.
Możesz uzyskać dostęp do narzędzia TableDiff za pomocą wiersza polecenia lub tylko z plików wsadowych. Narzędzie nie ma wymyślnego kreatora ani graficznego interfejsu użytkownika. Szczegółowa składnia narzędzia TableDiff znajduje się w artykule MSDN. Nasz obecny artykuł skupia się tylko na niektórych niezbędnych opcjach.
Aby porównać 2 tabele za pomocą narzędzia TableDiff, musimy podać obowiązkowe dane dla tabel źródłowych i docelowych, takie jak nazwa serwera źródłowego, nazwa źródłowej bazy danych, nazwa schematu źródłowego, nazwa tabeli źródłowej, nazwa serwera docelowego, nazwa docelowej bazy danych, miejsce docelowe Nazwa schematu i nazwa tabeli docelowej.
Spróbujmy przetestować TableDiff za pomocą Person.ContactType tabela różniąca się między wydawcą a subskrybentem.
Otwórz wiersz polecenia i przejdź do ścieżki narzędzia TableDiff (jeśli ta ścieżka nie została dodana do zmiennych środowiskowych).
Aby wyświetlić listę wszystkich dostępnych parametrów, wpisz polecenie „tablediff-?” aby wyświetlić listę wszystkich dostępnych opcji i parametrów. Wyniki są poniżej:
Sprawdźmy Osobę.ContactType tabeli w naszych bazach danych wydawców i subskrybentów, uruchamiając poniższe polecenie:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypePamiętaj, że nie podałem użytkownika źródłowego , hasło źródłowe , użytkownik docelowy i hasło docelowe ponieważ mój login Windows ma dostęp do tabel. Jeśli chcesz używać poświadczeń SQL zamiast uwierzytelniania Windows, powyższe parametry są obowiązkowe, aby uzyskać dostęp do tabel w celu porównania . W przeciwnym razie otrzymasz błędy.
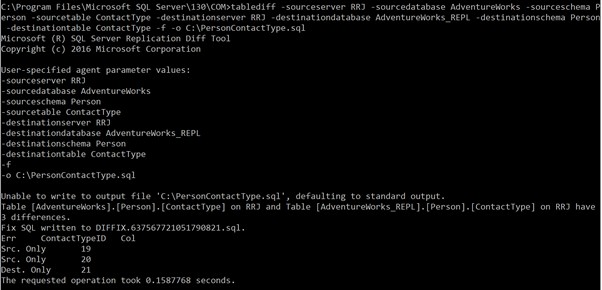
Wyniki poprawnego wykonania polecenia:
Pokazuje, że mamy 3 rozbieżności. Jeden to nowy rekord w docelowej bazie danych, a dwa rekordy nie są dostępne w docelowej bazie danych.
Rzućmy teraz okiem na Różne opcje dostępne dla narzędzia TableDiff.
- -et – zapisuje podsumowanie wyników w tabeli docelowej
- -dt – usuwa tabelę docelową wyników, jeśli już istnieje
- -f – generuje skrypt T-SQL DML z instrukcjami INSERT/UPDATE/DELETE, aby doprowadzić tabelę Destination do zbieżności z tabelą Source.
- -o – nazwa pliku wyjściowego, jeśli opcja -f służy do generowania pliku konwergencji.
Utworzymy plik konwergencji z -f i -o opcje do naszego wcześniejszego polecenia:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlPlik konwergencji został pomyślnie utworzony:
Jak widać, tworzenie nowego pliku w folderze głównym dysku C:jest niedozwolone ze względów bezpieczeństwa. W związku z tym wyświetla komunikat o błędzie i tworzy plik wyjściowy plik DIFFIX.*.sql w folderze narzędzia TableDiff. Kiedy otwieramy ten plik, możemy zobaczyć poniższe szczegóły:

Skrypty INSERT zostały utworzone dla 2 usuniętych rekordów, a skrypty DELETE zostały utworzone dla rekordów nowo wstawionych do bazy danych Subskrybentów. Narzędzie dba również o używanie opcji IDENTITY_INSERT wymaganych dla Miejsca docelowego stół. Dlatego to narzędzie będzie bardzo przydatne, gdy administrator baz danych będzie musiał zsynchronizować dwie tabele.
W naszym przypadku nie wykonam skryptów, ponieważ potrzebujemy tych wariancji do symulacji naszych problemów z replikacją SQL.
Zalety narzędzia TableDiff
- TableDiff to bezpłatne narzędzie, które jest częścią instalacji komponentów SQL Server Replication, które ma być używane do porównywania tabel lub konwergencji.
- Skrypty tworzenia konwergencji można tworzyć bez ręcznej interwencji.
Ograniczenia narzędzia TableDiff
- Narzędzie TableDiff można uruchomić tylko z wiersza poleceń lub pliku wsadowego.
- W wierszu poleceń możesz wykonać tylko jedno porównanie tabel na raz, chyba że masz kilka monitów poleceń otwartych równolegle, aby porównać kilka tabel.
- Tabela źródłowa, którą należy porównać przy użyciu narzędzia TableDiff, wymaga zdefiniowanego klucza podstawowego lub kolumny tożsamości albo kolumny ROWGUID dostępnej do przeprowadzenia porównania wiersz po wierszu. Jeśli -ścisłe używana jest opcja, tabela docelowa wymaga również klucza podstawowego, kolumny tożsamości lub dostępnej kolumny ROWGUID.
- Jeśli tabela źródłowa lub docelowa zawiera sql_variant kolumna typu danych, nie możesz użyć narzędzia TableDiff do jej porównania.
- Problemy z wydajnością można zauważyć podczas wykonywania narzędzia TableDiff na tabelach zawierających ogromne rekordy, ponieważ wykona ono porównanie wiersz po wierszu w tych tabelach.
- Skrypty konwergencji utworzone przez narzędzie TableDiff nie zawierają kolumn typu danych typu BLOB, takich jak varchar(max) , nvarchar(maks.) , zmienna (maks.) , tekst , ntekst lub obraz kolumny i xml lub sygnatura czasowa kolumny. Dlatego potrzebujesz alternatywnych metod obsługi tabel z tymi kolumnami typu danych.
Jednak nawet przy tych ograniczeniach narzędzie TableDiff może być używane w dowolnej tabeli programu SQL Server w celu szybkiej weryfikacji danych lub sprawdzenia zbieżności. Możesz jednak kupić również dobre narzędzie innej firmy.
Teraz przyjrzyjmy się szczegółowo różnym problemom z replikacją SQL.
Problemy z konfiguracją
Z mojego doświadczenia, skategoryzowałem często pomijane opcje konfiguracji replikacji, które mogą prowadzić do krytycznych problemów z replikacją SQL jako Konfiguracja kwestie. Niektóre z nich są poniżej.
Maksymalny rozmiar replikacji tekstu
Maksymalny rozmiar odpowiedzi tekstu odnosi się do Maksymalnego rozmiaru replikacji tekstu w bajtach . Dotyczy wszystkich typów danych takich jak char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, i obraz .
SQL Server ma domyślną opcję ograniczenia maksymalnej długości kolumny typu danych ciągu (w bajtach) do replikacji jako 65536 bajtów.
Za każdym razem, gdy dla bazy danych jest skonfigurowana replikacja, musimy dokładnie ocenić maksymalny rozmiar replikacji tekstu. W tym celu musimy sprawdzić wszystkie powyższe kolumny typów danych i określić maksymalną możliwą liczbę bajtów, które zostaną przesłane przez replikację.
Zmiana wartości na -1 oznacza, że nie ma ograniczeń. Zalecamy jednak oszacowanie maksymalnej długości ciągu i skonfigurowanie tej wartości.
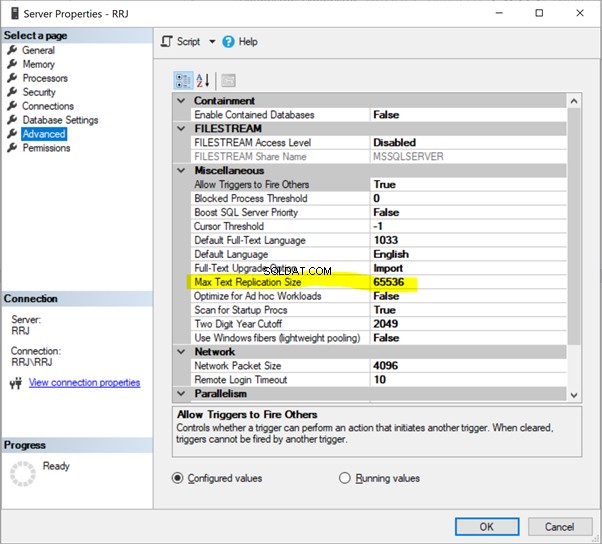
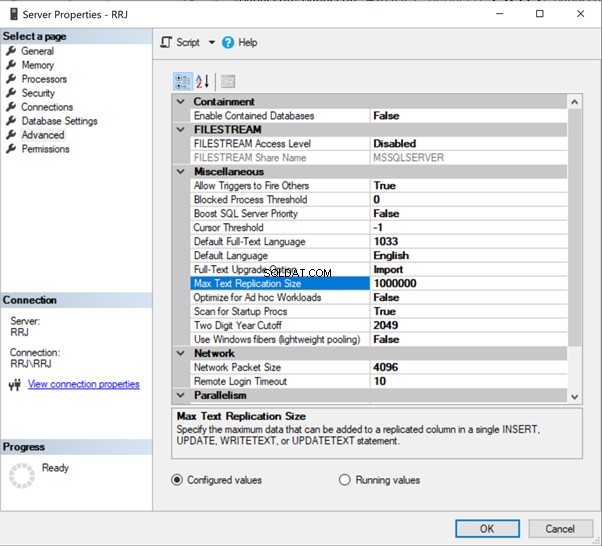
Możemy skonfigurować Max Text Repl Size za pomocą SSMS lub T-SQL.
W programie SSMS kliknij prawym przyciskiem myszy nazwę serwera> Właściwości > Zaawansowane :
Po prostu kliknij 65536 aby go zmodyfikować. Do testów zmieniłem 65536 na 1000000 i kliknąłem OK :
Aby skonfigurować opcję Max Text Repl Size za pomocą T-SQL, otwórz nowe okno zapytania i wykonaj poniższy skrypt na głównej bazie danych:
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
To zapytanie pozwoli replikacji nie ograniczać rozmiaru powyższych kolumn typu danych.
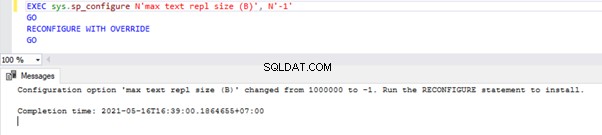
Aby to zweryfikować, możemy wykonać SELECT na sys.configuration DMV i sprawdź value_in_use kolumna jak poniżej:

Usługa agenta SQL Server nie jest ustawiona na uruchamianie trybu automatycznego
Replikacja opiera się na agentach replikacji, które są wykonywane jako zadania agenta SQL Server. Dlatego każdy problem z niektórymi usługami SQL Server Agent Service będzie miał bezpośredni wpływ na funkcjonalność replikacji.
Musimy się upewnić, że tryb uruchamiania SQL Server i SQL Server Agent Services są ustawione na Automatyczny. Jeśli ustawione na Manual, powinniśmy skonfigurować niektóre alerty. Powiadomią administratorów baz danych lub administratorów serwera, aby uruchomili usługę agenta SQL Server, gdy serwer uruchomi się ponownie, zaplanowane lub nieplanowane.
Jeśli nie zostanie to zrobione, replikacja może nie działać przez długi czas, co wpływa również na inne zadania agenta SQL Server.
Niemonitorowane instancje replikacji przechodzą w stan niezainicjowanych subskrypcji
Podobnie jak w przypadku monitorowania SQL Server Agent Service, konfigurowanie Database Mail Service w dowolnej instancji SQL Server odgrywa istotną rolę w ostrzeganiu DBA lub osoby skonfigurowanej w odpowiednim czasie. W przypadku jakichkolwiek błędów lub problemów zadań zadania agenta programu SQL Server, takie jak agent czytnika dzienników lub agent dystrybucji, można skonfigurować tak, aby wysyłały alerty do DBA lub odpowiedniego członka zespołu za pośrednictwem poczty e-mail. Niepowodzenie wykonania zadania agenta replikacji może prowadzić do następujących scenariuszy:
Niewykonanie zadania agenta odczytującego dzienniki . Plik dziennika transakcji bazy danych wydawcy zostanie ponownie użyty dopiero po poleceniu oznaczonym do replikacji jest odczytywany przez agenta czytnika dzienników i pomyślnie wysyłany do bazy danych dystrybucji. W przeciwnym razie log_reuse_wait_desc kolumna sys.databases pokaże wartość jako Replikacja, wskazując, że dziennik bazy danych nie może być ponownie użyty, dopóki pomyślnie nie przeniesie zmian do bazy danych dystrybucji. W związku z tym niewykonanie agenta Log Reader będzie zwiększać rozmiar pliku dziennika transakcyjnego bazy danych Publisher i napotkamy problemy z wydajnością podczas Pełnej kopii zapasowej lub problemy z miejscem na dysku w instancji bazy danych Publisher.
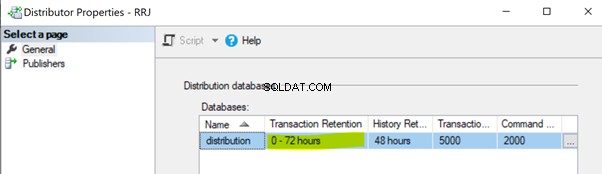
Niewykonanie pracy agenta dystrybucji. Zadanie agenta dystrybucji odczytuje dane z bazy danych dystrybucji i wysyła je do bazy danych subskrybenta. Następnie zaznacza te rekordy do usunięcia w bazie danych dystrybucji. Jeśli zadanie agenta dystrybucji nie jest wykonywane, zwiększy rozmiar bazy danych dystrybucji, powodując problemy z wydajnością ogólnej wydajności replikacji. Domyślnie baza danych dystrybucji jest skonfigurowana do przechowywania rekordów do maksymalnie 0-72 godzin, jak pokazano we właściwości Przechowywanie transakcji poniżej. Jeśli replikacja nie powiedzie się przez ponad 72 godziny, odpowiednia subskrypcja zostanie oznaczona jako niezainicjowana, co zmusi nas do ponownego skonfigurowania subskrypcji lub wygenerowania nowej migawki w celu ponownego uruchomienia replikacji.
Niewykonanie czyszczenia dystrybucji:zadanie dystrybucji . Zadanie czyszczenia dystrybucji jest odpowiedzialne za usuwanie wszystkich zreplikowanych rekordów z bazy danych dystrybucji, aby utrzymać kontrolę nad rozmiarem bazy danych dystrybucji. Niewykonanie tego zadania prowadzi do zwiększenia rozmiaru bazy danych dystrybucji, powodując problemy z wydajnością replikacji.
Aby upewnić się, że nie napotkamy żadnego z tych niemonitorowanych problemów, poczta bazy danych powinna być skonfigurowana tak, aby zgłaszać wszystkie niepowodzenia zadania lub ponawiać próby odpowiednim członkom zespołu w celu podjęcia natychmiastowych działań.
Znane problemy w SQL Server
Niektóre wersje programu SQL Server miały znane problemy z replikacją w wersji RTM lub wcześniejszych wersjach. Te problemy zostały rozwiązane w kolejnych dodatkach Service Pack lub CU. Dlatego zaleca się, aby po przetestowaniu ich w środowisku QA zastosować najnowsze dodatki Service Pack lub pakiety CU, które będą już dostępne dla wszystkich SQL Server. Chociaż jest to ogólne zalecenie dla serwerów z systemem SQL Server, ma ono również zastosowanie do replikacji.
Problemy z uprawnieniami
W środowisku ze skonfigurowaną replikacją transakcyjną SQL Server możemy często zaobserwować problemy z uprawnieniami. Możemy napotkać je w czasie konfiguracji Replikacji lub wszelkich działań konserwacyjnych na wystąpieniach bazy danych Wydawcy, Dystrybutora lub Subskrybenta. Powoduje to utratę poświadczeń lub uprawnień. Przyjrzyjmy się teraz kilku częstym problemom z uprawnieniami związanymi z replikacją.
Problemy z uprawnieniami do zadań SQL Server Agent
Wszyscy agenci replikacji używają zadań agenta programu SQL Server. Każde zadanie agenta SQL Server powiązane z migawką, agentem odczytu dziennika lub dystrybucją jest wykonywane z niektórymi danymi logowania Windows lub SQL, jak pokazano poniżej:
Aby uruchomić zadanie agenta SQL Server, musisz posiadać albo SQLAgentOperatorRole aby uruchomić wszystkie zadania lub albo SQLAgentUserRole lub SQLAgentReaderRole rozpocząć pracę, którą posiadasz. Jeśli jakiekolwiek zadania nie mogły się poprawnie rozpocząć, sprawdź, czy właściciel zadania ma niezbędne uprawnienia do wykonania tego zadania.
Poświadczenia zadania agenta migawek nie mogą uzyskać dostępu do ścieżki folderu migawek
W naszych poprzednich artykułach zauważyliśmy, że wykonanie agenta migawki utworzy migawkę artykułów w ścieżce folderu lokalnego lub udostępnionego, która ma być propagowana do bazy danych subskrybenta za pośrednictwem agenta dystrybucji. Lokalizację ścieżki migawki można znaleźć w Właściwościach publikacji > Migawka :
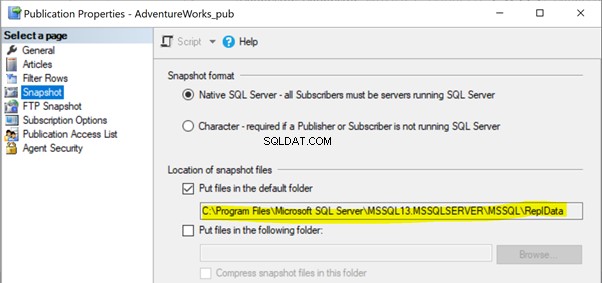
Jeśli agent migawki nie ma dostępu do tej lokalizacji plików migawki, może pojawić się błąd:
Dostęp do ścieżki „C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\YYYYMMDDHHMISS\” jest zabroniony.
Aby rozwiązać ten problem, lepiej przyznać pełny dostęp do ścieżki folderu C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ dla konta, na którym działa agent migawki. W naszej konfiguracji używamy konta SQL Server Agent, a usługa SQL Server Agent Service działa pod kontem RRJ\RRJ.
Poświadczenia pracy agenta czytnika dzienników nie mogą połączyć się z bazą danych wydawcy/dystrybucji
Log Reader Agent łączy się z bazą danych Publishera, aby wykonać sp_replcmds procedura skanowania w poszukiwaniu transakcji, które są oznaczone do replikacji z dzienników transakcyjnych bazy danych wydawcy.
Jeśli właściciel bazy danych wydawcy nie jest prawidłowo ustawiony, możemy otrzymać następujące błędy:
Proces nie mógł wykonać „sp_replcmds” na „RRJ.
Lub
Nie można wykonać jako podmiot zabezpieczeń bazy danych, ponieważ podmiot „dbo” nie istnieje, tego typu podmiotu nie można podszywać lub nie masz uprawnień.
Aby rozwiązać ten problem, upewnij się, że właściwość właściciela bazy danych bazy danych wydawcy jest ustawiona na sa lub inne ważne konto (patrz poniżej).
Kliknij prawym przyciskiem myszy Wydawcę baza danych (AdventureWorks )> Właściwości > Pliki . Upewnij się, że Właściciel pole jest ustawione na sa lub dowolny poprawny login i nie puste .
Jeśli wystąpią jakiekolwiek problemy z uprawnieniami, gdy łączymy się z bazą danych wydawców lub dystrybucji, sprawdź poświadczenia używane dla agenta odczytu dzienników i przyznaj im uprawnienia dostępu do tych baz danych.
Poświadczenia pracy agenta dystrybucji nie mogą połączyć się z bazą danych dystrybucji/subskrybentów
Agent dystrybucji może mieć problemy z uprawnieniami, jeśli konto nie może uzyskać dostępu do bazy danych dystrybucji lub połączyć się z bazą danych subskrybenta. W takim przypadku możemy otrzymać następujące błędy:
Nie można rozpocząć wykonywania kroku 2 (przyczyna:błąd podczas uwierzytelniania serwera proxy RRJ\RRJ, błąd systemu:nazwa użytkownika lub hasło jest nieprawidłowe).
Proces nie mógł połączyć się z „RRJ” subskrybenta.
Logowanie użytkownika „RRJ\RRJ” nie powiodło się.
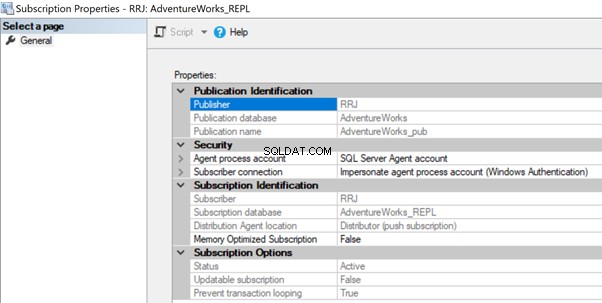
Aby rozwiązać ten problem, sprawdź konto używane we właściwościach subskrypcji i upewnij się, że ma ono niezbędne uprawnienia do łączenia się z bazą danych Dystrybucja lub Subskrybent.
Problemy z łącznością
Zwykle konfigurujemy replikację transakcyjną na serwerach w tej samej sieci lub w geograficznie rozproszonych lokalizacjach. Jeśli baza danych dystrybucji znajduje się na serwerze dedykowanym poza wydawcą lub subskrybentem, staje się podatna na utratę pakietów sieciowych – problemy z łącznością.
W przypadku takich problemów agenci replikacji (czytnik dzienników lub agent dystrybucji) mogą zgłosić następujące błędy:
Serwer wydawcy nie został znaleziony lub był niedostępny
Serwer dystrybucji nie został znaleziony lub był niedostępny
Serwer subskrybenta nie został znaleziony lub był niedostępny
Aby rozwiązać te problemy, możemy spróbować połączyć się z bazą danych wydawcy, dystrybutora lub subskrybenta w SSMS, aby sprawdzić, czy jesteśmy w stanie połączyć się z tymi instancjami SQL Server bez żadnych problemów.
Jeśli problemy z łącznością zdarzają się często, możemy spróbować pingować serwer w sposób ciągły, aby zidentyfikować utratę pakietów. Ponadto musimy współpracować z niezbędnymi członkami zespołu, aby rozwiązać te problemy i uruchomić serwer, aby replikacja mogła wznowić przesyłanie danych.
Problemy z integralnością danych
Ponieważ replikacja transakcyjna jest mechanizmem jednokierunkowym, wszelkie zmiany danych zachodzące u subskrybenta (ręcznie lub z aplikacji) nie zostaną odzwierciedlone w wydawcy. Może to prowadzić do różnic w danych między wydawcą a subskrybentem.
Przyjrzyjmy się problemom związanym z integralnością danych i zobaczmy, jak je rozwiązać. Zwróć uwagę, że wstawiliśmy rekord do Person.ContactType tabeli i usunięto 2 rekordy z Person.ContactType w bazie danych Subskrybentów. Użyjemy tych 3 rekordów, aby znaleźć błędy.
Błędy naruszenia klucza podstawowego lub unikalnego
Zamierzam przetestować rekord INSERT na Person.ContactType stół. Wstawmy ten rekord do bazy danych wydawców i zobaczmy, co się stanie:
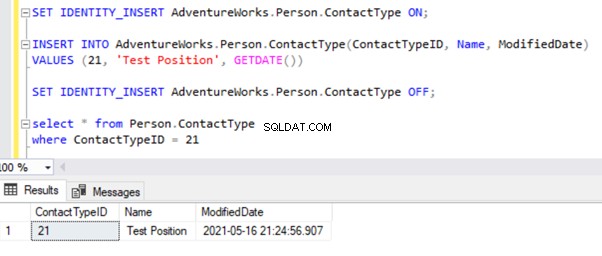
Uruchom Monitor replikacji, aby zobaczyć, jak to działa. Otrzymujemy błąd:
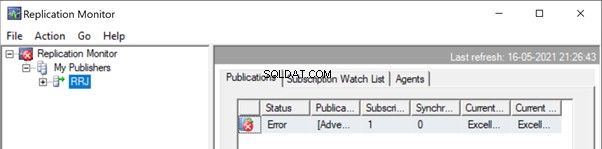
Rozwijanie Wydawcy i Publikacja , otrzymujemy następujące szczegóły:
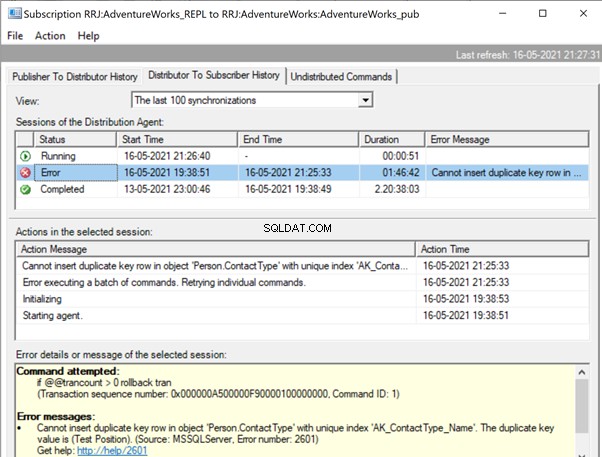
Jeśli skonfigurowaliśmy alerty replikacji i przydzieliliśmy odpowiednie osoby do otrzymywania alertów pocztowych, otrzymamy odpowiednie powiadomienia e-mail z komunikatem o błędzie:Nie można wstawić zduplikowanego wiersza klucza w obiekcie „Person.ContactType” z unikalnym indeksem „AK_ContactType_Name ' . Zduplikowana wartość klucza to (Pozycja testowa). (Źródło:MSSQLServer, numer błędu:2601)
Aby rozwiązać problem dotyczący naruszeń unikalnych kluczy lub problemów z kluczem podstawowym, mamy kilka opcji:
- Przeanalizuj, dlaczego wystąpił ten błąd, w jaki sposób rekord był dostępny w bazie danych subskrybentów i kto go wstawił z jakich powodów. Określ, czy było to konieczne, czy nie.
- Dodaj błędy pominięcia parametr do profilu agenta dystrybucji, aby pominąć Numer błędu 2601 lub Numer błędu 2627 w przypadku naruszenia klucza podstawowego.
W naszym przypadku celowo wstawiliśmy dane, aby otrzymać ten błąd. Aby rozwiązać ten problem, usuń ręcznie wstawiony rekord, aby kontynuować replikację zmian otrzymanych od wydawcy.
DELETE from Person.ContactType
where ContactTypeID = 21
Aby przestudiować inne opcje i porównać różnice między tymi dwoma podejściami, pomijam pierwszą opcję (która jest skuteczna i zalecana) i przechodzę do drugiej, dodając -skiperrors parametr do zadania agenta dystrybucji.
Możemy to zaimplementować, edytując Pracę agenta dystrybucyjnego > Kroki > kliknij 2 etap zadania o nazwie Uruchom agenta > kliknij Edytuj aby wyświetlić dostępne polecenie:
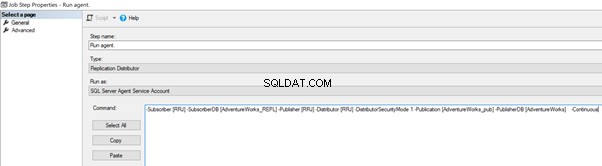
Teraz dodaj -SkipErrors 2601 słowo kluczowe na końcu (2601 to numer błędu – możemy pominąć dowolny numer błędu otrzymany w ramach Replikacji) i kliknąć OK .
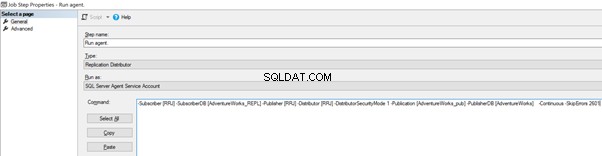
To make sure that the Distribution job is aware of this configuration change, we need to restart the Distribution agent job. For that, stop it and start again from Step 1 as shown below:
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
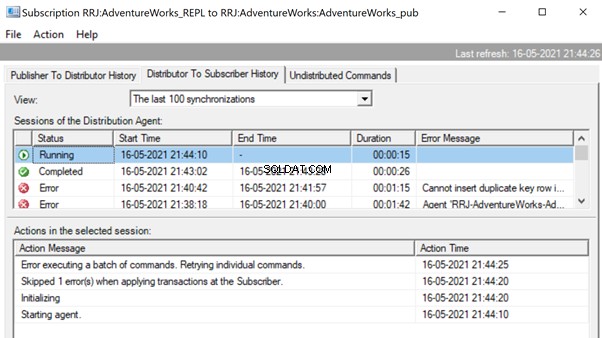
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
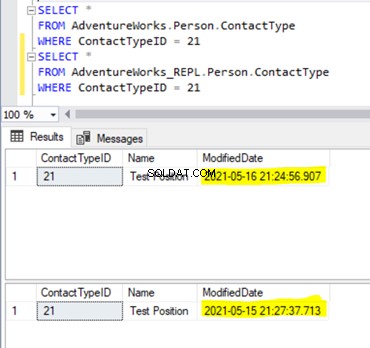
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors polecenie.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
Row Not Found Errors
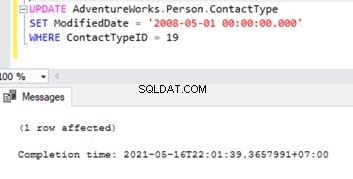
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
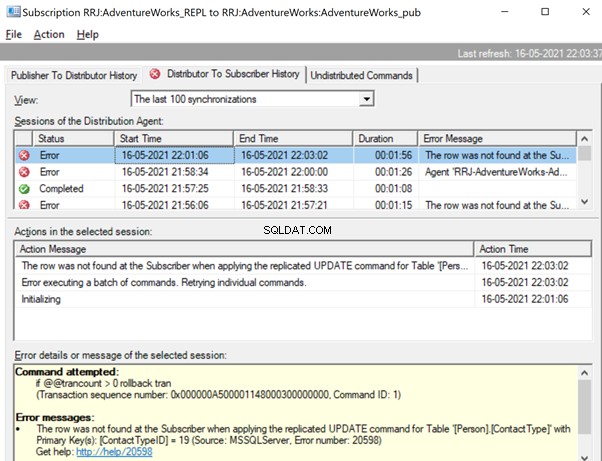
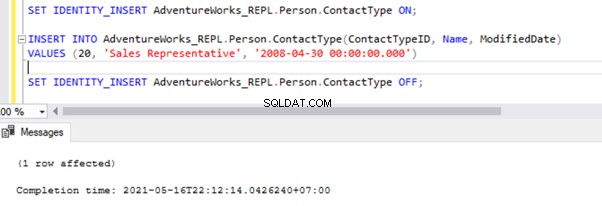
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors opcja. Instead, we’ll apply the INSERT approach.
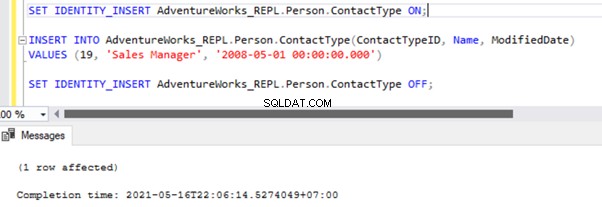
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
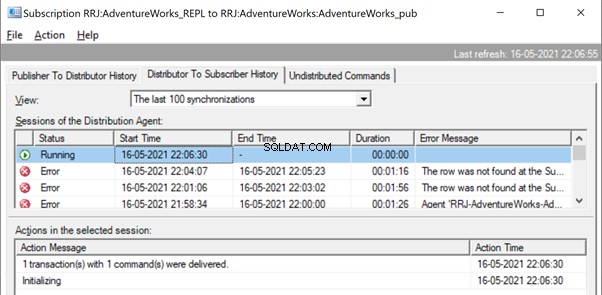
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
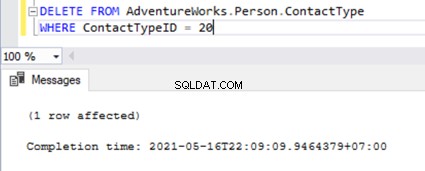
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
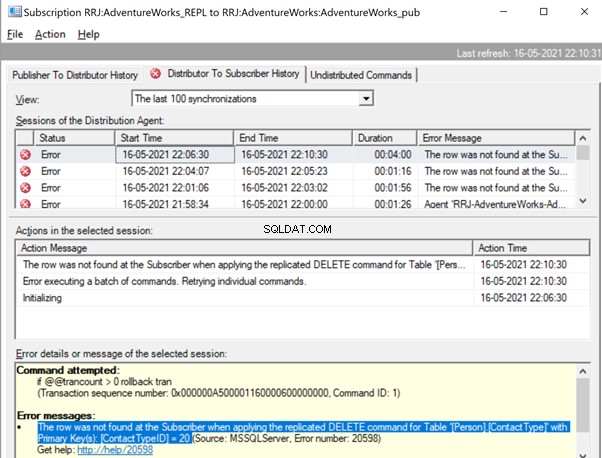
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Wniosek
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.