Wprowadzenie
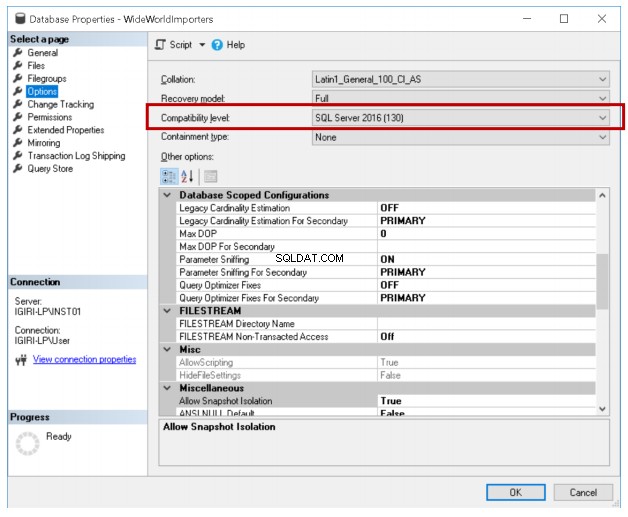
Magazyn zapytań to nowa funkcja wprowadzona w SQL Server 2016, która umożliwia administratorom baz danych historyczne przeglądanie zapytań i powiązanych z nimi planów za pomocą graficznego interfejsu użytkownika dostępnego w SQL Server Management Studio, a także analizowanie wydajności zapytań przy użyciu określonych widoków zarządzania dynamicznego. Query Store to opcja konfiguracji w zakresie bazy danych i jest dostępna do użycia, jeśli poziom zgodności danej bazy danych wynosi 130.
Query Store jest podobny do takich technologii na platformie bazodanowej Oracle, jak Automatic Workload Repository (AWR). AWR rejestruje statystyki wydajności na jeszcze większą skalę niż Query Store i pozwala administratorowi bazy danych na historyczną analizę wydajności. Takie pojęcia jak okres przechowywania i limity przechowywania gromadzonych danych są dostępne w architekturze AWR, podobnie jak w magazynie zapytań. Po włączeniu Query Store dostępne są następujące kluczowe opcje konfiguracji:
- Tryb pracy: Określa, czy magazyn zapytań zaakceptuje nowo przechwycone dane (tryb odczytu i zapisu), czy tylko zapisze stare dane dostępne dla raportów (tryb tylko do odczytu)
- Interwał opróżniania danych: Określa, jak często bufory pamięci magazynu zapytań są opróżniane na dysk. Przypomnij sobie, że dane magazynu zapytań są przechowywane w bazie danych, w której magazyn zapytań jest włączony. Domyślna wartość to 15 minut.
- Interwał zbierania statystyk: Określa, jak często gromadzone są statystyki czasu wykonywania zapytań w sklepie.
- Maksymalny rozmiar: Określa, jak bardzo może się powiększyć repozytorium dla statystyk magazynu zapytań. Domyślnie jest to 100 MB.
- Tryb przechwytywania zapytań w sklepie: Określa szczegółowość przechwytywania zapytań. Dostępne opcje to WSZYSTKO, AUTO i BRAK. Domyślna wartość to AUTO.
- Tryb czyszczenia na podstawie rozmiaru: Określa, czy magazyn zapytań opróżni stare dane po osiągnięciu maksymalnego rozmiaru.
- Próg nieaktualnego zapytania: Określa liczbę dni, przez które Query Store przechowuje dane. Domyślna wartość to trzydzieści dni.
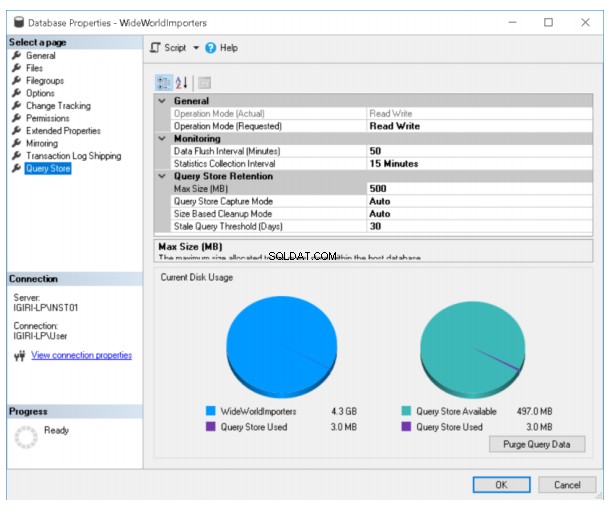
Rys. 2 Opcje zapisu zapytań
Magazyn zapytań to funkcja o zasięgu bazy danych, którą można włączyć za pomocą graficznego interfejsu użytkownika (SQL Server Management Studio) lub uruchamiając następujące polecenie:
ZMIANA BAZY DANYCH [WideWorldImporters] SET QUERY_STORE =ON;
Dane telemetryczne zapytań zebrane przez magazyn zapytań są przechowywane w tabelach systemowych w bazie danych, w której włączono magazyn zapytań.
Przykładowe zapytania i raporty domyślne
Do tej pory wszystko, co napisałem, jest dostępne z wielu innych źródeł; niektóre z nich można znaleźć w sekcji referencji.
W tej sekcji przyjrzymy się nieco głębiej, co faktycznie możemy zrobić z Query Store po włączeniu go za pomocą prostych przykładów. Rozważmy następujące dwa pytania:
Listing 1:Pobieranie rekordów przy użyciu określonego filtra
użyj WideWorldImportersgoselecta.ContactPersonID,a.OrderDate,a.DeliveryMethodID,a.Comments,b.OrderedOutersfromPurchasing.PurchaseOrders ainner Join Purchasing.PurchaseOrderLines bon a.PurchaseOrderwhere.ase.'SML03.Purchase pre>Listing 2:Pobieranie rekordów przy użyciu zakresu
użyj WideWorldImportersgoselecta.ContactPersonID,a.OrderDate,a.DeliveryMethodID,a.Comments,b.OrderedOutersfromPurchasing.PurchaseOrders ainner join Purchasing.PurchaseOrderLines bon a.PurchaseOrderLines. /pre>Zwróć uwagę na alternatywną wersję tych zapytań zapisaną wielkimi literami:
Listing 1:Pobieranie rekordów przy użyciu określonego filtra (wielkie litery)
UŻYJ WIDEWORLDIMPORTERSGOSELECTA.CONTACTPERSONID,A.ORDERDATE,A.DELIVERYMETHODID,A.COMMENTS,B.ORDEREDOUTERSFROZPURCHASING.PURCHASEORDERS AINNER DOŁĄCZ DO ZAKUPU.PURCHASEORDERLINES BON A.RE=.PURCHAID.PURCHAID00'; pre>Listing 2:Pobieranie rekordów przy użyciu zakresu (wielkie litery)
UŻYJ WIDEWORLDIMPORTERSGOSELECTA.CONTACTPERSONID,A.DATA ZAMÓWIENIA,A.METODY DOSTAWY,A.KOMENTARZE,B.ZAMÓWIONE ZEWNĘTRZNE OD ZAKUPU.ZAKUPUJĄCY 250 ZLECENIODAWCÓW AINNER DOŁĄCZ DO ZAKUPU.PURCHASEORDERLINES BON A.SEOR.S. /pre>Jak widać, wywołaliśmy te zapytania wielokrotnie, używając słowa kluczowego GO. W ten sposób mamy dość rozsądną ilość danych do pracy. Pierwszą rzeczą, o której powinniśmy wiedzieć, używając Query Store do analizy wydajności, jest to, że w SQL Server 2016 Query Store wbudowanych jest sześć domyślnych raportów, jak pokazano na rys. 3.
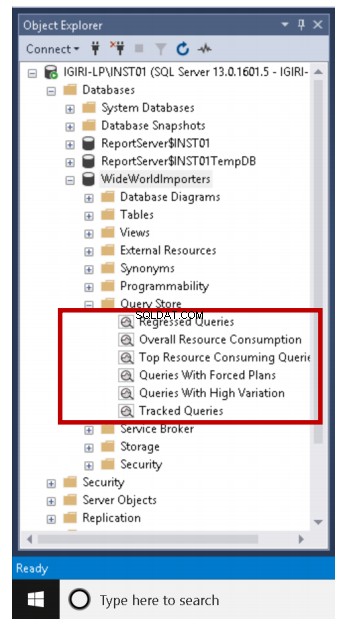
Rys. 3 Raporty dotyczące przechowywania zapytań
Nazwy raportów zostały szczegółowo opisane we wcześniejszych artykułach oraz w dokumentacji Microsoft. Dane dostarczane przez te raporty są pobierane z kluczowych dynamicznych widoków zarządzania wymienionych poniżej:
DMV ze statystykami planu
- sys.query_store_query_text – zawiera unikalne teksty zapytań wykonywane w bazie danych
- sys.query_store_plan – zawiera szacunkowy plan dla zapytania ze statystykami czasu kompilacji
- sys.query_context_settings – zawiera kilka unikalnych kombinacji planu wpływających na ustawienia, w których wykonywane są zapytania
- sys.query_store_query – wpisy zapytań, które są śledzone i wymuszane oddzielnie w Query Store
DMV ze statystykami czasu działania
- sys.query_store_runtime_stats_interval – Query Store dzieli czas na automatycznie generowane okna czasowe (interwały) i przechowuje zagregowane statystyki dla tego interwału dla każdego wykonanego planu
- sys.query_store_runtime_stats – zawiera zagregowane statystyki uruchomieniowe dla wykonanych planów
Znacznie więcej szczegółów na temat korzystania z tych DMV można znaleźć w przywołanej dokumentacji firmy Microsoft. W tym artykule będziemy po prostu używać głównie GUI.
Jak widać na rys. 4, przeglądamy raport Ogólne zużycie zasobów, podczas gdy w następnej sekcji zawęzimy do zapytań, które wymieniliśmy wcześniej, oraz danych, które możemy pobrać z tych prostych zapytań.
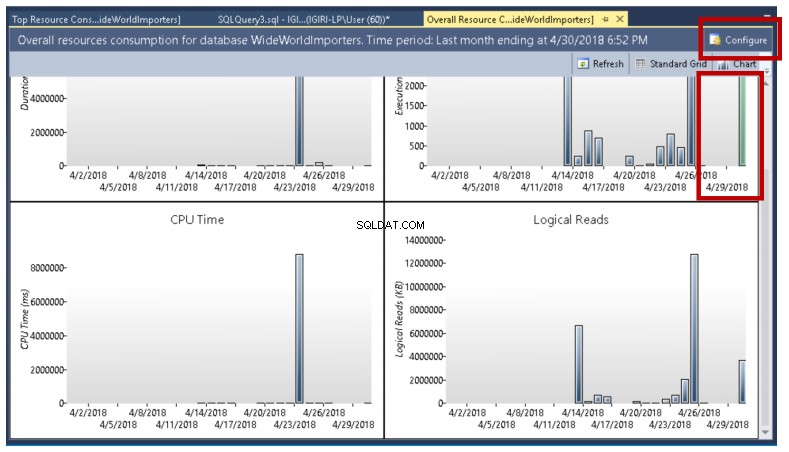
Rys. 4 Raport o całkowitym zużyciu zasobów
Analiza zapytań za pomocą GUI
Przy korzystaniu z raportów magazynu zapytań warto rozważyć kilka kluczowych rzeczy:
- Środowisko można skonfigurować, klikając przycisk wyróżniony na rys. 4. Rys. 5 pokazuje nam szczegóły, które możemy zmienić w celu dopasowania do naszego przypadku użycia:kryteria zwracanych danych, zakres dat i zestaw danych do zwrócenia. Na przykład, jeśli chcę wyraźnie zobaczyć identyfikator zapytania powiązany z przeglądanymi zapytaniami, chciałbym zmniejszyć mój zestaw danych na przykład z domyślnego Top 25 do Top 10.
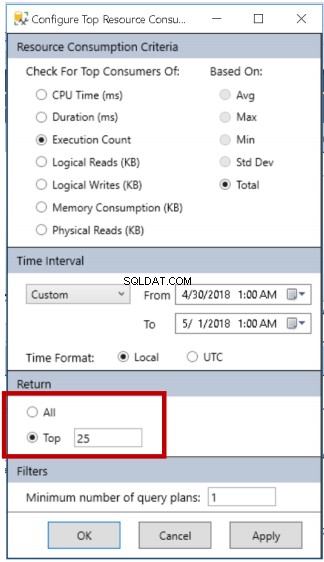
Rys. 5 Opcje konfiguracji raportu
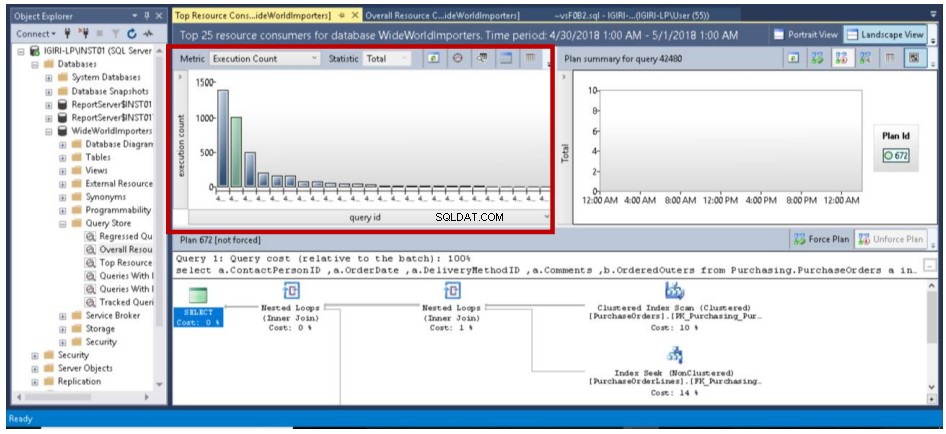
Rys. 6 25 najczęstszych zapytań wykonanych 1 maja 2018 r.
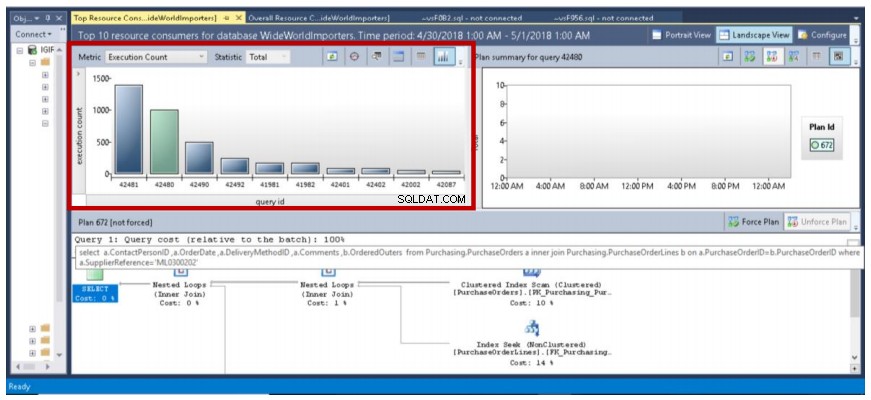
Rys. 7 10 najczęstszych zapytań wykonanych 1 maja 2018 r.
- Wykresy słupkowe wyświetlają dane głównie z czasem na osi X, ale możesz przejrzeć konkretny punkt danych, aby wyświetlić dane na podstawie identyfikatorów zapytań. Każdy identyfikator zapytania określa konkretne zapytanie. Należy zauważyć, że zapytanie jest jednoznacznie identyfikowane przez zahaszowanie tekstu. Tak więc zapytanie pisane małymi literami różni się od tego samego zapytania pisanego wielkimi literami. To powinna być powszechna wiedza:zapytania ad-hoc są problemem dla pamięci podręcznej planu, a także są złe dla magazynu zapytań zarówno pod względem wykorzystania przestrzeni, jak i właściwej analizy.
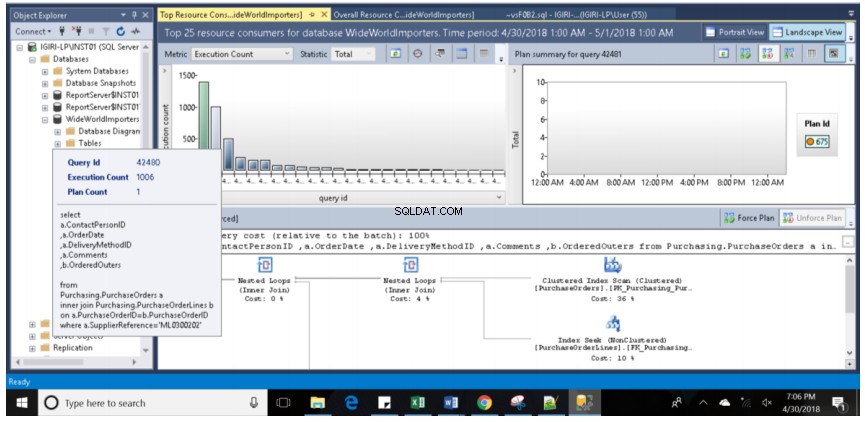
Rys. 8 Zapytanie z Listingu 1 (małe litery, zapytanie 42480)
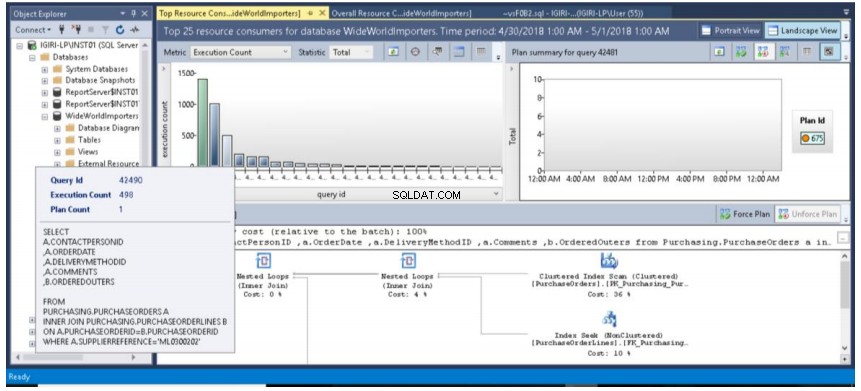
Rys. 9 Zapytanie na liście 3 (wielkie litery, zapytanie 42490)
- Trzecia ważna obserwacja to fakt, że kiedy punkt danych jest podświetlony na zielono, szczegółowy plan wykonania pokazany w dolnym okienku odnosi się do tego punktu danych. Na rys. 7 ten punkt danych odnosi się do zapytania o identyfikatorze 42481, które wykonaliśmy wcześniej (pełne zapytanie pokazane na listingu 2). Najechanie kursorem myszy na ten punkt danych wyświetla zapytanie, jego identyfikator oraz liczbę planów powiązanych z tym zapytaniem (patrz rys. 8).
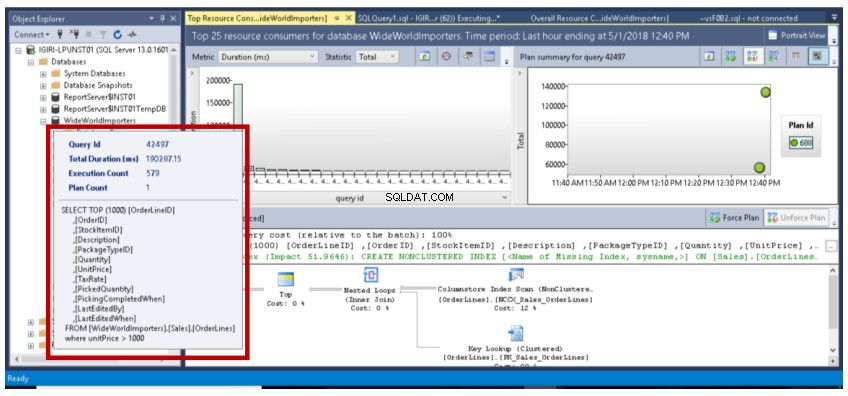
Rys. 10 Szczegóły zapytania 42481
Nasze zapytanie zostało wykonane 1391 razy, ponieważ zostało dokładnie przechwycone przez Query Store i wyświetlone na osi y (liczba wykonania) wykresu słupkowego na rys. 10. Raport był pobierany podczas wykonywania partii. W związku z tym nie mamy pełnej liczby (1500) informującej nas, że za każdym razem, gdy wykonywane jest zapytanie, następuje przechwytywanie danych w czasie rzeczywistym. Po prawej stronie widzimy również Plan używany do tych wielokrotnych egzekucji (Plan 675). Możemy to zweryfikować za pomocą zapytania z listy 5.
Lista 5
USE WideWorldImportersGOSELECT Txt.query_text_id, Txt.query_sql_text, Pl.plan_id, Qry.*FROM sys.query_store_plan AS PlJOIN sys.query_store_query AS Qry ON Pl.query_id =Qry.query_id_textJOIN_sys. .query_text_idwhere Qry.query_id=42481;
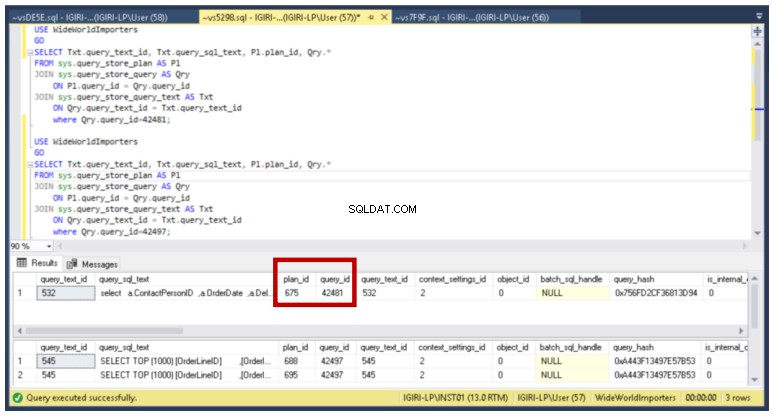
Rys. 11 Identyfikator zapytania i identyfikator planu z DMV
Trochę dostrajania
Rzućmy okiem na inne zapytanie.
Kiedy uruchamiamy zapytanie z Listingu 6 i sprawdzamy szczegóły z Query Store, szczegóły planu wykonania pokazują, że potrzebujemy indeksu, aby uzyskać poprawę o 51%.
Listing 6:Zapytanie nieoptymalne
SELECT TOP (1000) [IDLiniiZamówienia] ,[IDZamówienia] ,[IDPozycjiStockowej] ,[Opis] ,[IDPakietu] ,[Ilość] ,[CenaJednostkowa] ,[Stawka Podatkowa] ,[PickedQuantity] ,[PickingCompletedWhen] ,[LastEditedBy ] ,[LastEditedWhen] Z [WideWorldImporters].[Sprzedaż].[OrderLines] gdzie cena jednostkowa> 1000 GO 2000
Rys. 12 Nieoptymalne szczegóły zapytania
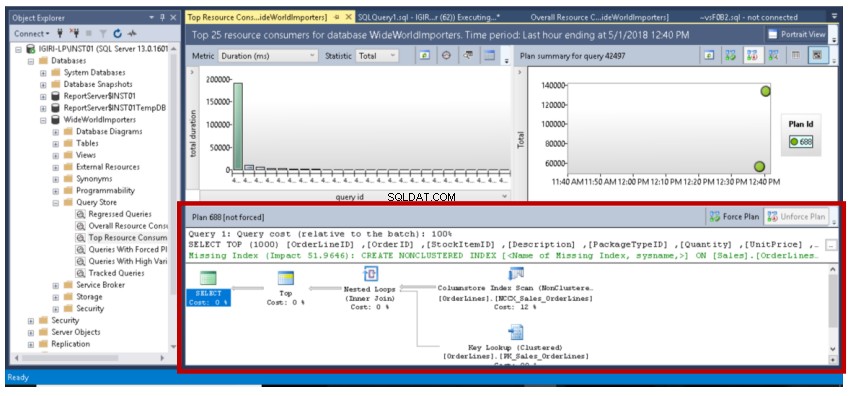
Rys. 13 Nieoptymalny plan wykonania zapytania
Po utworzeniu zalecanego indeksu przy użyciu instrukcji z Listingu 7 powodujemy, że Optymalizator zapytań generuje nowy plan wykonania. W takim przypadku oczekuje się, że nowy plan wykonania poprawi wydajność. Istnieją jednak przypadki, w których pewne zmiany mogą powodować pogorszenie wydajności, takie jak znaczne zmiany objętości danych, które skutecznie unieważniają statystyki lub zmniejszają liczbę indeksów i tak dalej. Mówi się, że wydajność takich zapytań uległa regresji i można je sprawdzić za pomocą raportu Zapytania, które uległy wycofaniu w magazynie zapytań.
Listing 7:Tworzenie indeksu
UŻYJ [WideWorldImporters]GOCREATE NIESKLASTRAROWANY INDEKS [Custom_IX_UnitPrice]ON [Sprzedaż].[OrderLines] ([CenaJednostkowa])INCLUDE([OrderLineID],[OrderID],[StockItemID],[Description],[PackageTypeID],[Ilość ],[Stawka podatkowa],[Wybrana ilość],[Pobranie zakończone, gdy],[Ostatnio edytowane przez],[Ostatnio edytowane, kiedy])GO
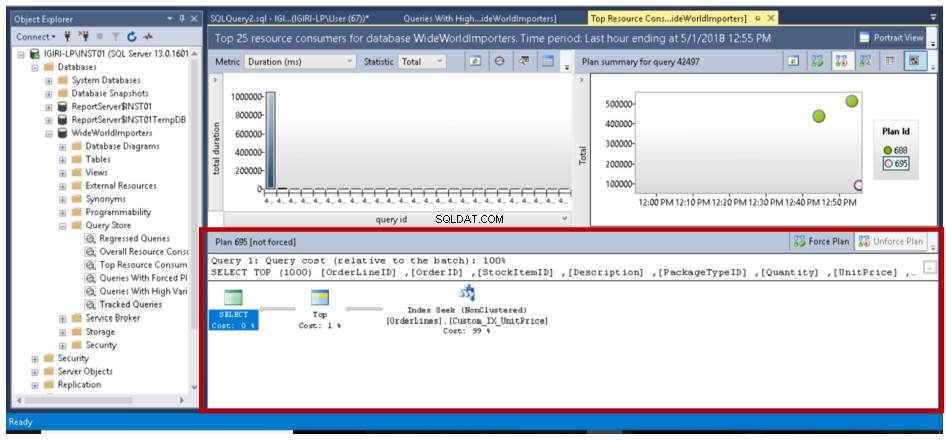
Rys. 14 Zoptymalizowane zapytanie (zmiana w planie wykonania)
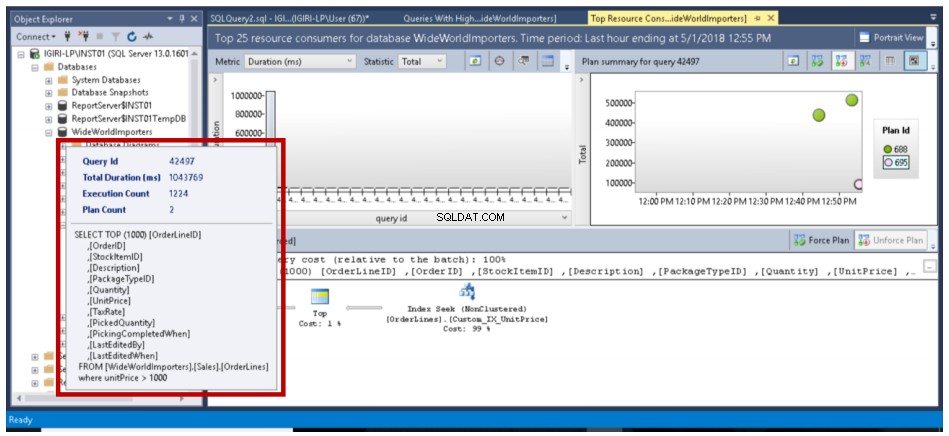
Rys. 15 Zoptymalizowane zapytanie (dwa plany)
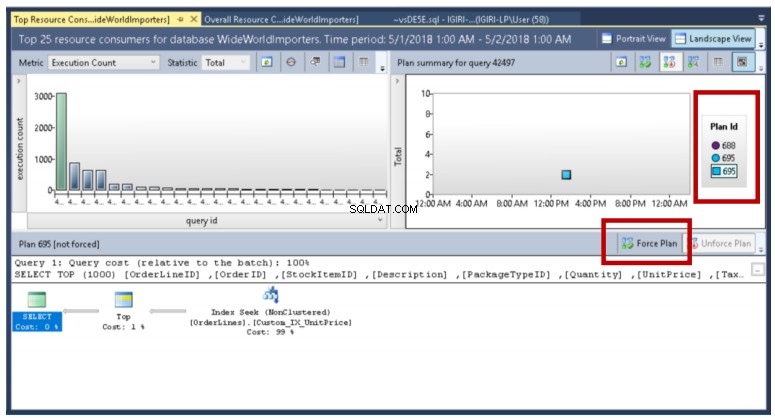
Rys. 16 Zoptymalizowane zapytanie (plan wymuszony)
Gdy istnieje wiele planów dla zapytania, jak pokazano na rys. 14 i rys. 16, możemy powiedzieć optymalizatorowi, aby zawsze używał wybranego przez nas planu, klikając przycisk Wymuś plan. To było trochę żmudne zadanie w poprzednich wersjach SQL Server.
Jak widać na rys. 17, Query Store pozwala nam porównać różne plany związane z zapytaniem przy użyciu wielu metryk.
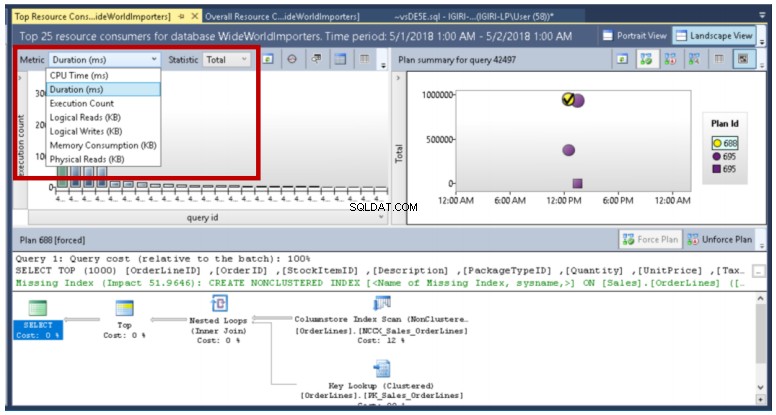
Rys. 17 Porównanie planów wykonania
Ponownie możemy użyć zapytania z listingu 8, aby zweryfikować plany powiązane z tym identyfikatorem zapytania za pomocą DMV. (Patrz rys. 11)
Listing 8:Plany powiązane z zapytaniem 42497
USE WideWorldImportersGOSELECT Txt.query_text_id, Txt.query_sql_text, Pl.plan_id, Qry.*FROM sys.query_store_plan AS PlJOIN sys.query_store_query AS Qry ON Pl.query_id =Qry.query_id_textJOIN_sys. .query_text_idwhere Qry.query_id=42497;
Odkrywanie odmian
Innym przydatnym raportem, z którego korzysta Query Store, są zapytania z dużą zmiennością. Ten raport pokazuje nam, jak daleko od siebie znajdują się pożądane dane dla konkretnego zapytania w danym okresie. Jest to bardzo przydatne do analizy historycznej wydajności. Korzystając ze stwierdzeń z Listingu 9, generujemy dane, które mogą dać obraz tego, jak wyglądałyby wariacje. Kroki procedury po prostu tworzą małą tabelę, a następnie wstawiają rekordy przy użyciu różnych rozmiarów partii.
Listing 9:Plany powiązane z zapytaniem 42497
użyj WideWorldImportersgo-- Utwórz tabelę Tablecreate tableone(ID int identity(1000,1),FirstName varchar(30),LastName varchar(30),CountryCode char(2),HireDate datetime2 default getdate());-- Wstaw rekordy w partiach o różnych rozmiarachwstaw do wartości tableone ('Kenneth','Igiri','NG',getdate());GO 10000wstaw do wartości tableone ('Kwame','Boateng','GH', getdate());GO 10wstaw do wartości tableone ('Philip','Onu','NG',getdate());GO 100000wstaw do wartości tableone ('Kwesi','Armah','GH', getdate());GO 100 Query Store pokazuje nam szczegóły, takie jak minimalne i maksymalne wartości tych metryk dla określonych interwałów wykonywania zapytania, które nas interesuje. W tym przykładzie stwierdzamy, że jest to po prostu wynik liczby partii na wykonanie (zauważ, że parametry są faktycznie używane do wykonania instrukcji INSERT). W produkcji za takie zmiany mogą odpowiadać inne czynniki.
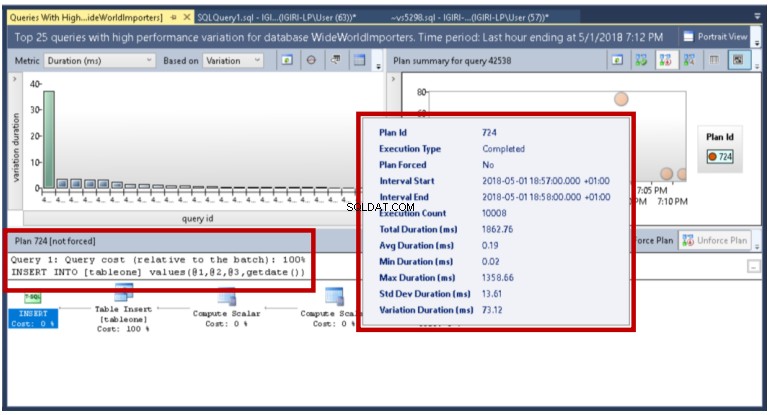
Rys. 18 Różnice w czasie trwania
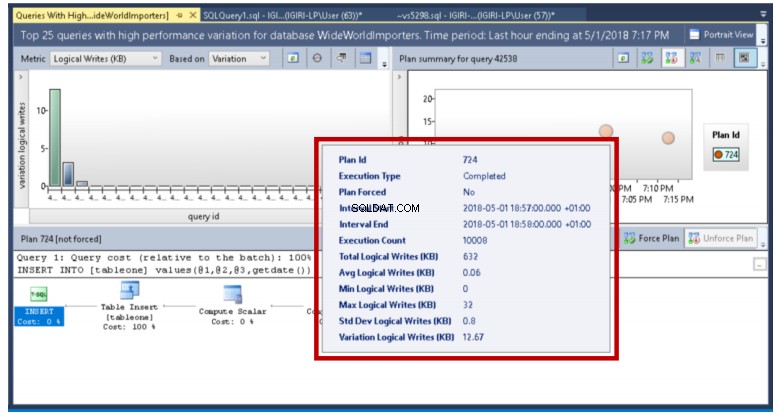
Rys. 19 Różnice w zapisach logicznych
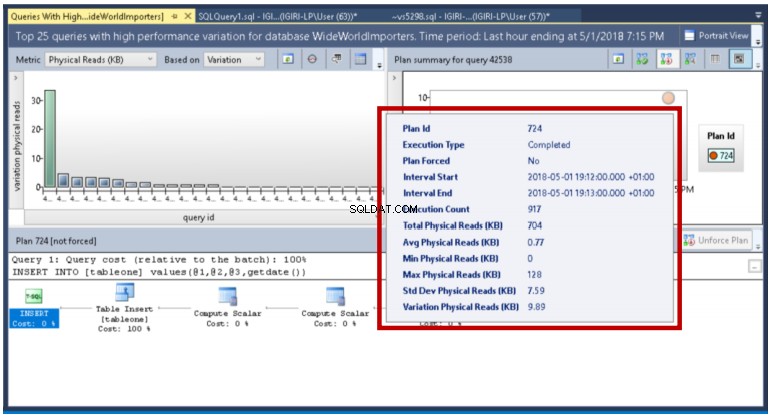
Rys. 20 Różnice w odczytach fizycznych
Wniosek
W tym artykule omówiliśmy środowisko GUI SQL Server 2016 Query Store i kilka rzeczy, które możemy wywnioskować na temat wydajności naszej instancji (w odniesieniu do SQL) przy użyciu Query Store. Istnieje kilka artykułów w Internecie, które pokazują jeszcze bardziej zaawansowane przypadki użycia i znacznie głębsze wyjaśnienie elementów wewnętrznych. Ten artykuł powinien być przydatny dla administratorów baz danych średniego poziomu, którzy chcą uzyskać przewagę w używaniu Query Store do oceny/dostrajania wydajności.
Referencje
- Najlepsze praktyki ze sklepem zapytań
- Cristiman, L. (2016) Magazyn zapytań – ustawienia i limity
- Monitorowanie wydajności za pomocą magazynu zapytań
- Zapytanie o widoki katalogu sklepu
- Zapytanie o procedury przechowywane w magazynie
- Zapis zapytań – jak to działa i jak z niego korzystać
- Scenariusze wykorzystania magazynu zapytań
- Van de Lar, E. (2016) Magazyn zapytań SQL Server 2016:wymuszanie planów wykonania przy użyciu magazynu zapytań
Przydatne narzędzie:
dbForge Query Builder dla SQL Server – pozwala użytkownikom szybko i łatwo tworzyć złożone zapytania SQL za pomocą intuicyjnego interfejsu wizualnego bez ręcznego pisania kodu.