Czy używasz podzapytań SQL, czy unikasz ich używania?
Załóżmy, że główny specjalista ds. kredytów i windykacji prosi o wymienienie nazwisk osób, ich niezapłaconych miesięcznych sald oraz bieżącego salda bieżącego i chce, abyś zaimportował tę tablicę danych do programu Excel. Celem jest analiza danych i przedstawienie oferty ułatwiającej płatności, aby złagodzić skutki pandemii COVID19.
Czy decydujesz się na użycie zapytania i zagnieżdżonego podzapytania lub sprzężenia? Jaką decyzję podejmiesz?
Podzapytania SQL – czym one są?
Zanim zagłębimy się w składnię, wpływ na wydajność i zastrzeżenia, dlaczego najpierw nie zdefiniować podzapytania?
Mówiąc najprościej, podzapytanie to zapytanie w zapytaniu. Chociaż zapytanie, które zawiera podzapytanie, jest zapytaniem zewnętrznym, podzapytanie nazywamy zapytaniem wewnętrznym lub wewnętrznym wyborem. A nawiasy zawierają podzapytanie podobne do poniższej struktury:
SELECT col1,col2,(podzapytanie) jako col3FROM table1[JOIN table2 ON table1.col1 =table2.col2]WHERE col1 (podzapytanie) W tym poście przyjrzymy się następującym punktom:
- Składnia podzapytań SQL w zależności od różnych typów podzapytań i operatorów.
- Kiedy iw jakich wyrażeniach można użyć podzapytania.
- Implikacje dotyczące wydajności a połączenia .
- Typowe zastrzeżenia podczas korzystania z podzapytań SQL.
Zgodnie ze zwyczajem podajemy przykłady i ilustracje w celu lepszego zrozumienia. Pamiętaj jednak, że główny nacisk w tym poście dotyczy podzapytań w SQL Server.
Teraz zacznijmy.
Twórz podzapytania SQL, które są samodzielne lub skorelowane
Po pierwsze, podzapytania są kategoryzowane na podstawie ich zależności od zapytania zewnętrznego.
Pozwól, że opiszę, czym jest samodzielne podzapytanie.
Samodzielne podzapytania (lub czasami określane jako nieskorelowane lub proste podzapytania) są niezależne od tabel w zapytaniu zewnętrznym. Pozwolę sobie to zilustrować:
-- Pobierz zamówienia sprzedaży klientów z południowo-zachodnich Stanów Zjednoczonych — (TerritoryID =4)USE [AdventureWorks]GOSELECT CustomerID, SalesOrderIDFROM Sales.SalesOrderHeaderWHERE CustomerID IN (SELECT [CustomerID] FROM [AdventureWorks].[Sales] .[Klient] WHERE identyfikator terytorium =4) Jak pokazano w powyższym kodzie, podzapytanie (ujęte w nawiasach poniżej) nie ma odniesień do żadnej kolumny w zapytaniu zewnętrznym. Dodatkowo możesz podświetlić podzapytanie w SQL Server Management Studio i wykonać je bez żadnych błędów w czasie wykonywania.
Co z kolei prowadzi do łatwiejszego debugowania samodzielnych podzapytań.
Następną rzeczą do rozważenia są skorelowane podzapytania. W porównaniu z jego samodzielnym odpowiednikiem, ten ma co najmniej jedną kolumnę, do której odwołuje się zapytanie zewnętrzne. Dla wyjaśnienia podam przykład:
UŻYJ [AdventureWorks]GOSELECT DISTINCT a.Nazwisko, a.Imię, b.IDPodmiotuBiznesowegoFROM Osoba.Osoba AS pJOIN Zasoby Ludzkie.Pracownik AS e ON p.IDPodmiotuBiznesowego =e.IDPodmiotuBiznesowegoWHERE 1262000.00 IN (SELECT [Kwota sprzedaży] FROM Sprzedaż .SalesPersonQuotaHistory spq WHERE p.BusinessEntityID =spq.BusinessEntityID) Czy byłeś wystarczająco uważny, aby zauważyć odniesienie do BusinessEntityID? od osoby stół? Dobra robota!
Gdy w podzapytaniu występuje odwołanie do kolumny z zapytania zewnętrznego, staje się ona podzapytaniem skorelowanym. Jeszcze jedna kwestia do rozważenia:jeśli podświetlisz podzapytanie i je wykonasz, wystąpi błąd.
I tak, masz absolutną rację:to sprawia, że skorelowane podzapytania są trudniejsze do debugowania.
Aby umożliwić debugowanie, wykonaj następujące kroki:
- odizoluj podzapytanie.
- zastąp odwołanie do zewnętrznego zapytania stałą wartością.
Wyizolowanie podzapytania do debugowania sprawi, że będzie wyglądać tak:
SELECT [SalesQuota] FROM Sales.SalesPersonQuotaHistory spq WHERE spq.BusinessEntityID = Teraz przyjrzyjmy się trochę głębiej wynikom podzapytań.
Utwórz podzapytania SQL z 3 możliwymi wartościami zwracanymi
Cóż, najpierw zastanówmy się, jakich zwracanych wartości możemy się spodziewać po podzapytaniach SQL.
W rzeczywistości są 3 możliwe wyniki:
- Pojedyncza wartość
- Wiele wartości
- Całe stoły
Pojedyncza wartość
Zacznijmy od wyjścia jednowartościowego. Ten typ podzapytania może pojawić się w dowolnym miejscu zapytania zewnętrznego, w którym oczekiwane jest wyrażenie, np. WHERE klauzula.
-- Wypisz pojedynczą wartość, która jest maksymalną lub ostatnią TransactionIDUSE [AdventureWorks]GOSELECT TransactionID, ProductID, TransactionDate, QuantityFROM Production.TransactionHistoryWHERE TransactionID =(SELECT MAX(t.TransactionID) FROM Production.TransactionHistory t) Gdy używasz MAX () funkcja, pobierasz pojedynczą wartość. Dokładnie to stało się z naszym podzapytaniem powyżej. Używając równego (= ) informuje SQL Server, że oczekujesz pojedynczej wartości. Kolejna rzecz:jeśli podzapytanie zwraca wiele wartości przy użyciu równości (= ), pojawi się błąd podobny do poniższego:
Msg 512, poziom 16, stan 1, wiersz 20.Podzapytanie zwróciło więcej niż 1 wartość. Nie jest to dozwolone, gdy podzapytanie następuje po =, !=, <, <=,>,>=lub gdy podzapytanie jest używane jako wyrażenie. Wiele wartości
Następnie przyjrzymy się wielowartościowym wynikom. Ten rodzaj podzapytania zwraca listę wartości w jednej kolumnie. Dodatkowo operatorzy tacy jak IN i NIE W będzie oczekiwać jednej lub więcej wartości.
-- Podaj wiele wartości, czyli listę klientów z nazwiskami, które --- zaczynają się od „I'USE [AdventureWorks]GOSELECT [IDZamówieniaSprzedaży], [DataZamówienia], [DataWysyłki], [IDKlienta]FROM Sprzedaż .SalesOrderHeaderWHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer cINNER JOIN Person.Person p ON c.PersonID =p.BusinessEntityIDWHERE p.lastname LIKE N'I%' AND p.PersonType='SC') Całe wartości tabeli
I wreszcie, dlaczego nie zagłębić się w dane wyjściowe całej tabeli.
-- Wygeneruj tabelę wartości na podstawie zamówień sprzedażyUSE [AdventureWorks]GOSELECT [RokWysyłki],COUNT(DISTINCT [IDKlienta]) AS CustomerCountFROM (SELECT YEAR([DataWysyłki]) AS [RokWysyłki], [IDKlienta] FROM Sales.SalesOrderHeader) AS ShipmentsGROUP BY [ShipYear]ORDER BY [ShipYear] Czy zauważyłeś OD klauzula?
Zamiast używać tabeli, użył podzapytania. Nazywa się to tabelą pochodną lub podzapytaniem tabeli.
A teraz pozwól, że przedstawię kilka podstawowych zasad dotyczących tego rodzaju zapytań:
- Wszystkie kolumny w podzapytaniu powinny mieć unikalne nazwy. Podobnie jak tabela fizyczna, tabela pochodna powinna mieć unikalne nazwy kolumn.
- ZAMÓW PRZEZ nie jest dozwolone, chyba że GÓRA jest również określony. Dzieje się tak, ponieważ tabela pochodna reprezentuje tabelę relacyjną, w której wiersze nie mają zdefiniowanej kolejności.
W takim przypadku tabela pochodna ma zalety tabeli fizycznej. Dlatego w naszym przykładzie możemy użyć COUNT () w jednej z kolumn tabeli pochodnej.
To wszystko, co dotyczy wyników podzapytania. Ale zanim przejdziemy dalej, być może zauważyłeś, że logikę przykładu dla wielu wartości i innych można również wykonać za pomocą JOIN .
-- Wypisuje wiele wartości, które są listą klientów z nazwiskami zaczynającymi się od „I'USE [AdventureWorks]GOSELECT o.[IDZamówieniaSprzedaży], o.[DataZamówienia], o.[Data Wysyłki], o. [CustomerID]FROM Sales.SalesOrderHeader oINNER JOIN Sales.Customer c on o.CustomerID =c.CustomerIDINNER JOIN Person.Person p ON c.PersonID =p.BusinessEntityIDWHERE p.LastName LIKE N'I%' AND p.PersonType ='SC ' W rzeczywistości wynik będzie taki sam. Ale który z nich działa lepiej?
Zanim do tego przejdziemy, powiem, że poświęciłem sekcję temu gorącemu tematowi. Zbadamy to z pełnymi planami wykonania i obejrzymy ilustracje.
Więc wytrzymaj ze mną przez chwilę. Omówmy inny sposób umieszczania podzapytań.
Inne instrukcje, w których można używać podzapytań SQL
Do tej pory używaliśmy podzapytań SQL w SELECT sprawozdania. Chodzi o to, że możesz czerpać korzyści z podzapytań na INSERT , AKTUALIZUJ i USUŃ instrukcji lub w dowolnej instrukcji T-SQL, która tworzy wyrażenie.
Rzućmy więc okiem na serię kilku przykładów.
Korzystanie z podzapytań SQL w instrukcjach UPDATE
Umieszczanie podzapytań w UPDATE . jest wystarczająco proste sprawozdania. Dlaczego nie sprawdzić tego przykładu?
-- W inwentarzu produktów przenieś wszystkie produkty dostawcy 1602 do ------ lokalizacji 6USE [AdventureWorks]GOUPDATE [Produkcja].[ProductInventory]SET LocationID =6WHERE ProductID IN (SELECT ProductID FROM Purchasing .ProductVendor WHERE BusinessEntityID =1602)IDŹ Czy zauważyłeś, co tam zrobiliśmy?
Chodzi o to, że możesz umieścić podzapytania w GDZIE klauzula AKTUALIZACJI oświadczenie.
Ponieważ nie mamy tego w przykładzie, możesz również użyć podzapytania dla SET klauzula jak SET kolumna =(podzapytanie) . Ale uważaj:powinien wypisać pojedynczą wartość, ponieważ w przeciwnym razie wystąpi błąd.
Co robimy dalej?
Korzystanie z podzapytań SQL w instrukcjach INSERT
Jak już wiesz, możesz wstawiać rekordy do tabeli za pomocą SELECT oświadczenie. Jestem pewien, że wiesz, jaka będzie struktura podzapytania, ale zademonstrujmy to na przykładzie:
-- Nałóż podwyżkę wynagrodzenia dla wszystkich pracowników w dziale ID 6 -- (Badania i rozwój) o 10 (myślę, że w dolarach) -- od 1 czerwca 2020 r.USE [AdventureWorks]GOINSERT INTO [HumanResources].[ EmployeePayHistory]([BusinessEntityID],[RateChangeDate],[Rate],[PayFrequency],[ModifiedDate])SELECTa.BusinessEntityID,'06/01/2020' as RateChangeDate,(SELECT MAX(b.Rate) FROM [HumanResources]. [EmployeePayHistory] b WHERE a.BusinessEntityID =b.BusinessEntityID) + 10 as NewRate,2 as PayFrequency,getdate() as ModifiedDateFROM [HumanResources].[EmployeeDepartmentHistory] aWHERE a.IDDepartamentu =6i DataRozpoczęcia =(SELECT) FROM HumanResources.EmployeeDepartmentHistory c GDZIE c.BusinessEntityID =a.BusinessEntityID) Więc na co tu patrzymy?
- Pierwsze podzapytanie pobiera ostatnią stawkę wynagrodzenia pracownika przed dodaniem dodatkowych 10.
- Drugie podzapytanie pobiera ostatni rekord wynagrodzenia pracownika.
- Na koniec wynik SELECT jest umieszczony w EmployeePayHistory stół.
W innych instrukcjach T-SQL
Oprócz SELECT , WSTAW , AKTUALIZUJ i USUŃ , możesz również użyć podzapytań SQL w następujący sposób:
Deklaracje zmiennych lub instrukcje SET w procedurach i funkcjach składowanych
Pozwólcie, że wyjaśnię za pomocą tego przykładu:
DECLARE @maxTransId int =(SELECT MAX(TransactionID) FROM Production.TransactionHistory) Alternatywnie możesz to zrobić w następujący sposób:
DECLARE @maxTransId intSET @maxTransId =(SELECT MAX(TransactionID) FROM Production.TransactionHistory) W wyrażeniach warunkowych
Może rzucisz okiem na ten przykład:
IF EXISTS(SELECT [Name] FROM sys.tables, gdzie [Name] ='MyVendors')BEGIN DROP TABLE MoiVendorsEND Poza tym możemy to zrobić tak:
IF (SELECT liczba(*) FROM MyVendors)> 0BEGIN -- wstaw kod tutaj END Tworzenie podzapytań SQL z operatorami porównawczymi lub logicznymi
Do tej pory widzieliśmy równych (= ) i operator IN. Ale jest o wiele więcej do odkrycia.
Korzystanie z operatorów porównania
Gdy operator porównania, taki jak =, <,>, <>,>=lub <=, jest używany z podzapytaniem, podzapytanie powinno zwrócić pojedynczą wartość. Co więcej, błąd pojawia się, gdy podzapytanie zwraca wiele wartości.
Poniższy przykład wygeneruje błąd w czasie wykonywania.
UŻYJ [AdventureWorks]GOSELECT b.Nazwisko, b.Imię, b.Drugie imię, a.Tytuł pracy, a.IDPodmiotuBiznesowegoFROM Zasoby ludzkie.Pracownik aINNER JOIN Osoba.Osoba b na a.IDPodmiotuBiznesowego =b.IDPodmiotuBiznesowegoINNER JOIN. EmployeeDepartmentHistory c on a.BusinessEntityID =c.BusinessEntityIDWHERE c.DepartmentID =6 i StartDate =(SELECT d.StartDate FROM HumanResources.EmployeeDepartmentHistory d WHERE d.BusinessEntityID =a.BusinessEntityID) Czy wiesz, co jest nie tak w powyższym kodzie?
Przede wszystkim kod używa operatora równości (=) z podzapytaniem. Dodatkowo podzapytanie zwraca listę dat rozpoczęcia.
Aby rozwiązać problem, spraw, aby podzapytanie używało funkcji takiej jak MAX () w kolumnie daty rozpoczęcia, aby zwrócić pojedynczą wartość.
Korzystanie z operatorów logicznych
Korzystanie z opcji ISTNIEJE lub NIE ISTNIEJE
ISTNIEJE zwraca PRAWDA jeśli podzapytanie zwraca jakiekolwiek wiersze. W przeciwnym razie zwraca FALSE . Tymczasem używanie NIE ISTNIEJE zwróci PRAWDA jeśli nie ma wierszy i FAŁSZ , w przeciwnym razie.
Rozważ poniższy przykład:
IF EXISTS(WYBIERZ nazwę FROM sys.tables, gdzie nazwa ='Token')BEGIN DROP TABLE TokenEND Najpierw pozwól, że wyjaśnię. Powyższy kod usunie token tabeli, jeśli zostanie znaleziony w sys.tables , co oznacza, że istnieje w bazie danych. Kolejna kwestia:odniesienie do nazwy kolumny jest nieistotne.
Dlaczego tak jest?
Okazuje się, że silnik bazy danych potrzebuje tylko co najmniej 1 wiersza za pomocą EXISTS . W naszym przykładzie, jeśli podzapytanie zwróci wiersz, tabela zostanie usunięta. Z drugiej strony, jeśli podzapytanie nie zwróciło ani jednego wiersza, kolejne instrukcje nie zostaną wykonane.
Tak więc troska o ISTNIEJE to tylko wiersze bez kolumn.
Dodatkowo ISTNIEJE używa logiki dwuwartościowej:PRAWDA lub FAŁSZ . Nie ma przypadków, w których zwróci NULL . To samo dzieje się, gdy negujesz EXISTS używając NIE .
Używanie IN lub NOT IN
Podzapytanie wprowadzone za pomocą IN lub NIE W zwróci listę zerową lub większą liczbą wartości. I w przeciwieństwie do ISTNIEJE , wymagana jest prawidłowa kolumna z odpowiednim typem danych.
Pozwólcie, że wyjaśnię to na innym przykładzie:
-- Ze spisu produktów wyodrębnij produkty, które są dostępne -- (Ilość>0) -- z wyjątkiem produktów od dostawcy 1676 i wprowadź obniżkę ceny dla --- całego miesiąca czerwca 2020 r. . -- Wstaw wyniki do historii cen produktów.UŻYJ [AdventureWorks]GOINSERT INTO [Produkcja].[HistoriaCenListyProduktów] ([IDProduktu] ,[DataRozpoczęcia] ,[DataZakończenia] ,[CenaListy] ,[DataZmodyfikowania])SELECT a.IDProduktu, '06/01/2020' jako StartDate,'06/30/2020' as EndDate,a.ListPrice - 2 as ReducedListPrice,getdate() as ModifiedDateFROM [Produkcja].[ProductListPriceHistory] aWHERE a.StartDate =(SELECT MAX(StartDate) ) FROM Produkcja.ListaProduktówHistoriaCeny WHERE IDProduktu =a.IDProduktu)AND a.IDProduktu IN (SELECT IDProduktu FROM Produkcja.ZapasyProduktów WHERE Ilość> 0)AND a.IdentyfikatorProduktu NOT IN (SELECT IDProduktu FROM [Zakupy].[DostawcaProduktu] GDZIE BusinessEntityID =1676 Jak widać z powyższego kodu, oba IN i NIE W wprowadzane są operatory. W obu przypadkach wiersze zostaną zwrócone. Każdy wiersz w zewnętrznym zapytaniu zostanie dopasowany do wyniku każdego podzapytania w celu uzyskania produktu, który jest dostępny i produktu, który nie pochodzi od dostawcy 1676.
Zagnieżdżanie podzapytań SQL
Możesz zagnieżdżać podzapytania nawet do 32 poziomów. Niemniej jednak ta możliwość zależy od dostępnej pamięci serwera i złożoności innych wyrażeń w zapytaniu.
Jakie jest Twoje zdanie na ten temat?
Z mojego doświadczenia nie przypominam sobie zagnieżdżania do 4. Rzadko używam 2 lub 3 poziomów. Ale to tylko ja i moje wymagania.
Co powiesz na dobry przykład, aby to rozgryźć:
-- Wypisz nazwiska pracowników, którzy są również klientami.USE [AdventureWorks]GOSELECTNazwisko,Imię,ŚrednieNazwiskoFROM Osoba.OsobaWHEREIdentyfikatorpodmiotubiznesowego IN (SELECT IDpodmiotubiznesowego FROM Sprzedaż.Klient WHERE IDpodmiotubiznesowego IN (SELECTIdentyfikatorpodmiotubiznesowego FROM Zasobyludzkie.Pracownik) )) Jak widać w tym przykładzie, zagnieżdżanie osiągnęło 2 poziomy.
Czy podzapytania SQL są złe dla wydajności?
W skrócie:tak i nie. Innymi słowy, to zależy.
I nie zapominaj, że dzieje się to w kontekście SQL Server.
Na początek wiele instrukcji T-SQL, które używają podzapytań, można alternatywnie przepisać za pomocą JOIN s. A wydajność dla obu jest zwykle taka sama. Mimo to istnieją szczególne przypadki, w których łączenie jest szybsze. Są też przypadki, w których podzapytanie działa szybciej.
Przykład 1
Przeanalizujmy przykład podzapytania. Przed ich wykonaniem naciśnij Control-M lub włącz Uwzględnij rzeczywisty plan wykonania z paska narzędzi SQL Server Management Studio.
USE [AdventureWorks]GOSELECT NazwaFROM Produkcja.ProduktWHERE CenaListy =SELECT CenaListyFROM Produkcja.Produkt WHERE Nazwa ='Zakończenia trasy turystycznej') Alternatywnie powyższe zapytanie można przepisać za pomocą złączenia, które daje ten sam wynik.
USE [AdventureWorks]GOSELECT Prd1.NameFROM Production.Product AS Prd1INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice =Prd2.ListPrice)WHERE Prd2.Name ='Zakończenia turystyczne' Ostatecznie wynik dla obu zapytań to 200 wierszy.
Oprócz tego możesz sprawdzić plan wykonania obu oświadczeń.
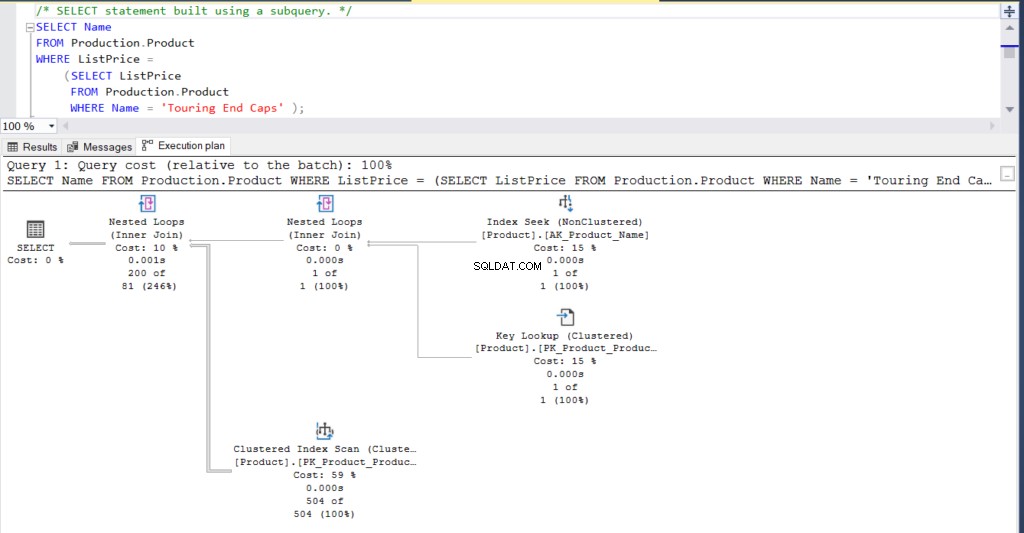
Ilustracja 1:Plan wykonania przy użyciu podzapytania
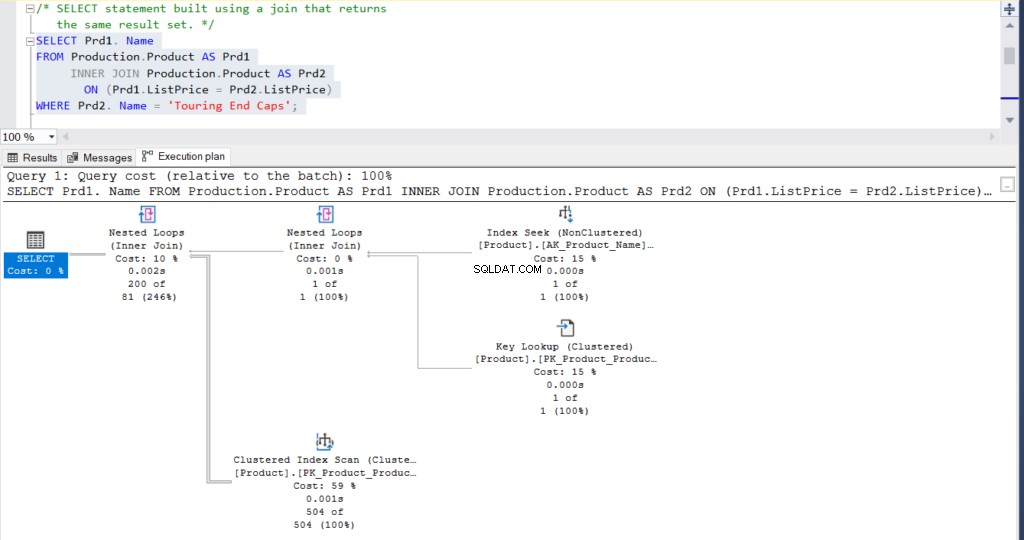
Ilustracja 2:Plan wykonania za pomocą połączenia
Co myślisz? Czy są praktycznie takie same? Z wyjątkiem faktycznego czasu, jaki upłynął dla każdego węzła, wszystko inne jest w zasadzie takie samo.
Ale oto inny sposób porównania tego, oprócz różnic wizualnych. Proponuję skorzystać z Porównaj plan pokazu .
Aby to zrobić, wykonaj następujące kroki:
- Kliknij prawym przyciskiem myszy plan wykonania instrukcji za pomocą podzapytania.
- Wybierz Zapisz plan wykonania jako .
- Nazwij plik subquery-execution-plan.sqlplan .
- Przejdź do planu wykonania wyciągu za pomocą złączenia i kliknij go prawym przyciskiem myszy.
- Wybierz Porównaj plan pokazowy .
- Wybierz nazwę pliku zapisaną w #3.
Teraz sprawdź to, aby uzyskać więcej informacji o Porównaj plan pokazowy .
Powinieneś być w stanie zobaczyć coś podobnego do tego:
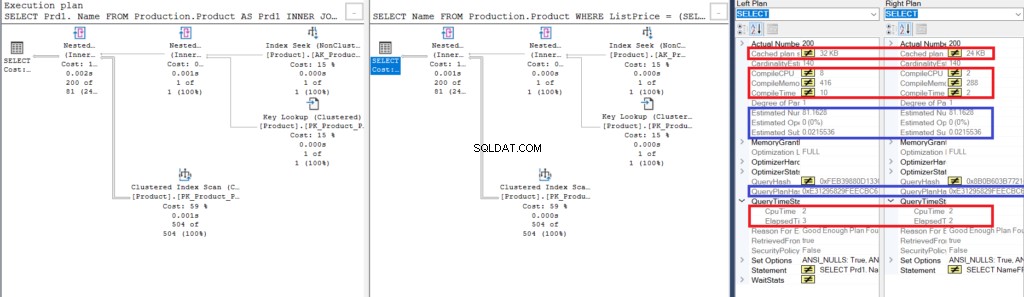
Ilustracja 3:Porównanie Showplan dla użycia sprzężenia z użyciem podzapytania
Zwróć uwagę na podobieństwa:
- Szacowane wiersze i koszty są takie same.
- QueryPlanHash jest również taki sam, co oznacza, że mają podobne plany wykonania.
Niemniej jednak zwróć uwagę na różnice:
- Rozmiar planu pamięci podręcznej jest większy przy połączeniu niż przy użyciu podzapytania
- Proces kompilacji i czas (w ms), w tym pamięć w KB, użyte do parsowania, wiązania i optymalizacji planu wykonania są wyższe przy użyciu sprzężenia niż przy użyciu podzapytania
- Czas procesora i upływający czas (w ms) wykonania planu jest nieco wyższy przy użyciu połączenia w porównaniu z podzapytaniem
W tym przykładzie podzapytanie jest szybsze niż łączenie, mimo że wynikowe wiersze są takie same.
Przykład 2
W poprzednim przykładzie użyliśmy tylko jednej tabeli. W poniższym przykładzie użyjemy 3 różnych tabel.
Zróbmy to:
-- Przykład podzapytaniaUSE [AdventureWorks]GOSELECT [IDZamówieniaSprzedaży], [DataZamówienia], [DataWysyłki], [IDKlienta]FROM Sprzedaż.NagłówekZamówieniaSprzedażyWHERE [IDKlienta] IN (SELECT c.[IDKlienta] FROM Sprzedaż.Klient c INNER JOIN Person.Person p ON c.PersonID =p.BusinessEntityID GDZIE p.PersonType='SC') -- Dołącz przykładUŻYJ [AdventureWorks]GOSELECT o.[IDZamówieniaSprzedaży],o.[DataZamówienia],o.[DataWysyłki],o.[IDKlienta]FROM Sprzedaż.NagłówekZamówieniaSprzedaży oINNER JOIN Sprzedaż.Klient c o. CustomerID =c.CustomerIDINNER DOŁĄCZ Osoba.Osoba p ON c.PersonID =p.BusinessEntityIDGDZIE p.PersonType ='SC' Oba zapytania wyświetlają te same 3806 wierszy.
Następnie spójrzmy na ich plany wykonania:
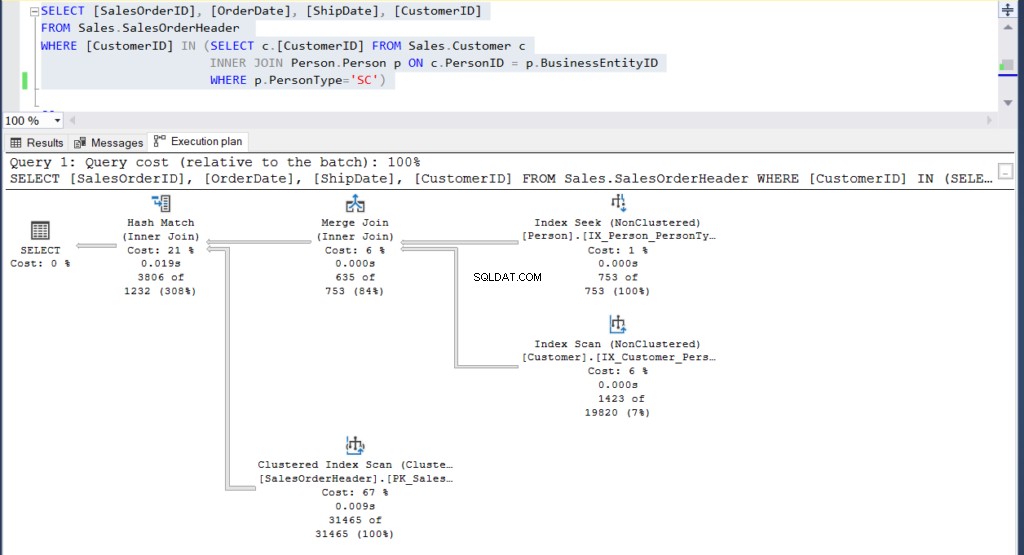
Rysunek 4:Plan wykonania dla naszego drugiego przykładu z użyciem podzapytania
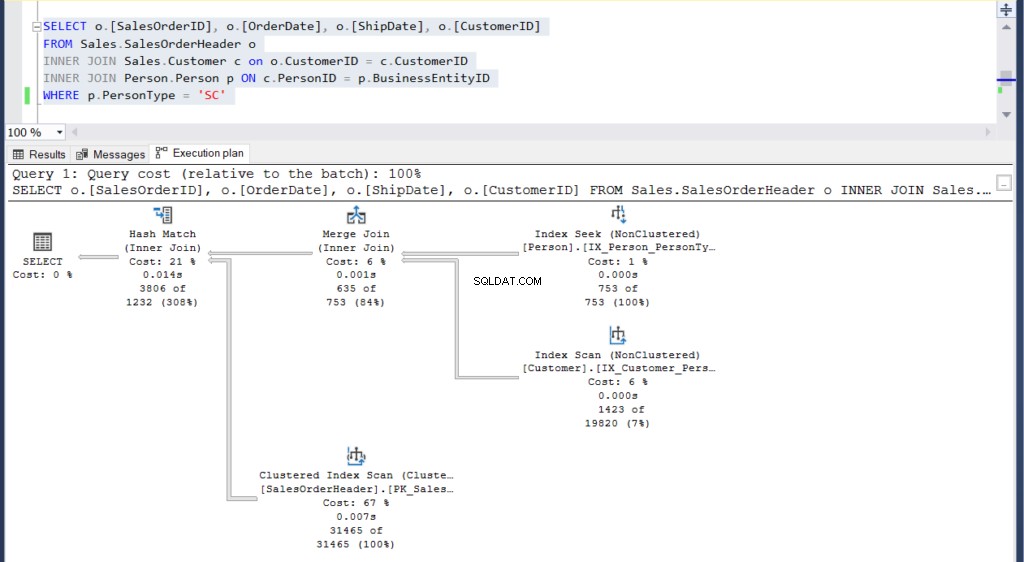
Ilustracja 5:Plan realizacji dla naszego drugiego przykładu z wykorzystaniem złączenia
Czy widzisz 2 plany wykonania i widzisz między nimi różnicę? Na pierwszy rzut oka wyglądają tak samo.
Ale dokładniejsze badanie z Porównaj plan pokazu ujawnia, co naprawdę jest w środku.
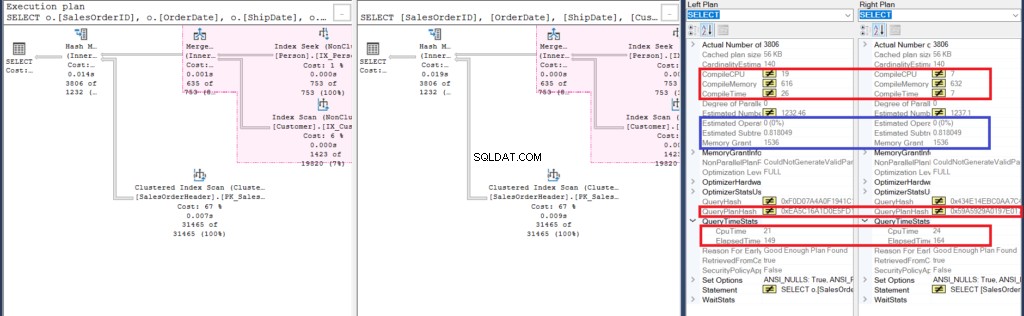
Rysunek 6:Szczegóły planu porównawczego dla drugiego przykładu
Zacznijmy od analizy kilku podobieństw:
- Różowe podświetlenie w planie wykonania pokazuje podobne operacje dla obu zapytań. Ponieważ wewnętrzne zapytanie używa sprzężenia zamiast zagnieżdżania podzapytań, jest to całkiem zrozumiałe.
- Szacowane koszty operatora i poddrzewa są takie same.
Następnie przyjrzyjmy się różnicom:
- Po pierwsze, kompilacja trwała dłużej, gdy używaliśmy złączeń. Możesz to sprawdzić w Compile CPU i Compile Time. Jednak zapytanie z podzapytaniem zajęło większą ilość pamięci kompilacji w KB.
- Zatem QueryPlanHash obu zapytań jest inny, co oznacza, że mają inny plan wykonania.
- Na koniec, czas, który upłynął i czas procesora do wykonania planu są szybsze przy użyciu połączenia niż przy użyciu podzapytania.
Podzapytanie a dołączanie na wynos wydajności
Prawdopodobnie napotkasz zbyt wiele innych problemów związanych z zapytaniami, które można rozwiązać za pomocą sprzężenia lub podzapytania.
Ale najważniejsze jest to, że podzapytanie nie jest z natury złe w porównaniu do złączeń. I nie ma żadnej praktycznej zasady, że w konkretnej sytuacji sprzężenie jest lepsze niż podzapytanie lub odwrotnie.
Aby więc mieć pewność, że masz najlepszy wybór, sprawdź plany wykonania. Celem tego jest uzyskanie wglądu w to, jak SQL Server przetworzy określone zapytanie.
Jeśli jednak zdecydujesz się użyć podzapytania, pamiętaj, że mogą pojawić się problemy, które sprawdzą Twoje umiejętności.
Typowe zastrzeżenia dotyczące używania podzapytań SQL
Istnieją 2 typowe problemy, które mogą spowodować, że Twoje zapytania będą zachowywać się szalenie podczas korzystania z podzapytań SQL.
Ból rozwiązywania nazw kolumn
Ten problem wprowadza logiczne błędy w zapytaniach, które mogą być bardzo trudne do znalezienia. Przykład może dokładniej wyjaśnić ten problem.
Zacznijmy od utworzenia tabeli do celów demonstracyjnych i wypełnienia jej danymi.
UŻYJ [AdventureWorks]GO-- Utwórz tabelę dla naszej demonstracji na podstawie VendorsCREATE TABLE Purchasing.MyVendors(BusinessEntity_id int,AccountNumber nvarchar(15),Name nvarchar(50))GO-- Uzupełnij niektóre dane do naszego nowa tabelaINSERT INTO Purchasing.MyVendorsSELECT BusinessEntityID, AccountNumber, Name FROM Purchasing.VendorWHERE BusinessEntityID IN (SELECT BusinessEntityID FROM Purchasing.ProductVendor)ANDBusinessEntityID jak „14%”GO Teraz, gdy tabela jest ustawiona, uruchommy kilka podzapytań z jej użyciem. Ale przed wykonaniem poniższego zapytania pamiętaj, że identyfikatory dostawców, których użyliśmy w poprzednim kodzie, zaczynają się od „14”.
SELECT b.Name, b.ListPrice, a.BusinessEntityIDFROM Purchasing.ProductVendor aINNER JOIN Produkcja.Produkt b na a.ProductID =b.ProductIDWHERE a.BusinessIdentityID IN (SELECT BusinessEntityID FROM Purchasing.MyVendors) Powyższy kod działa bez błędów, jak widać poniżej. W każdym razie zwróć uwagę na listę BusinessEntityID .
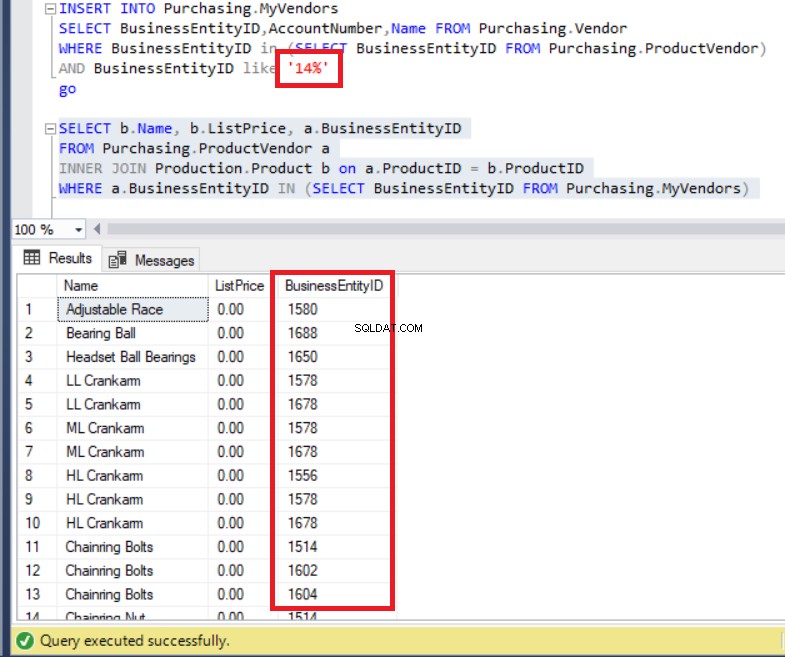
Rysunek 7:BusinessEntityIDs zestawu wyników są niezgodne z rekordami tabeli MyVendors
Czy nie wstawiliśmy danych z BusinessEntityID? zaczynając od „14”? Więc o co chodzi? W rzeczywistości możemy zobaczyć BusinessEntityIDs które zaczynają się od „15” i „16”. Skąd się one wzięły?
W rzeczywistości zapytanie zawierało wszystkie dane od ProductVendor tabela.
W takim przypadku możesz pomyśleć, że alias rozwiąże ten problem, tak aby odwoływał się do MyVendors tabela taka jak ta poniżej:
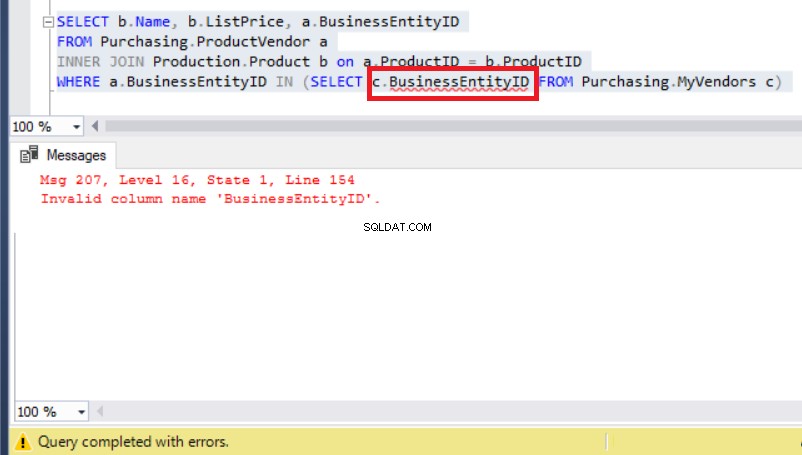
Rysunek 8:Dodanie aliasu do BusinessEntityID skutkuje błędem
Tyle że teraz prawdziwy problem pojawił się z powodu błędu w czasie wykonywania.
Sprawdź MyVendors tabeli ponownie, a zobaczysz, że zamiast BusinessEntityID , nazwa kolumny musi mieć postać BusinessEntity_id (z podkreśleniem).
Dlatego użycie prawidłowej nazwy kolumny ostatecznie rozwiąże ten problem, jak widać poniżej:
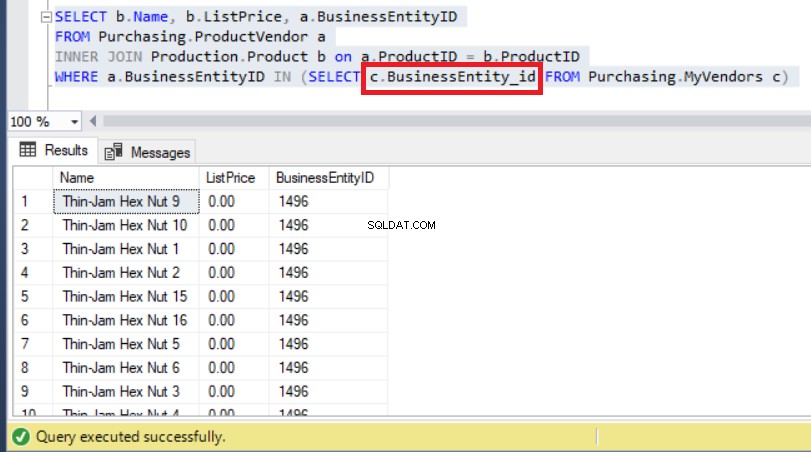
Rysunek 9:Zmiana podzapytania z prawidłową nazwą kolumny rozwiązała problem
Jak widać powyżej, możemy teraz obserwować BusinessEntityIDs zaczynając od „14”, tak jak oczekiwaliśmy wcześniej.
Ale możesz się zastanawiać: dlaczego na Ziemi SQL Server pozwolił na pomyślne uruchomienie zapytania?
Oto kicker:rozwiązywanie nazw kolumn bez aliasów działa w kontekście podzapytania od samego siebie do zapytania zewnętrznego. Dlatego odniesienie do BusinessEntityID wewnątrz podzapytania nie wywołał błędu, ponieważ znajduje się poza podzapytaniem – w ProductVendor tabela.
Innymi słowy, SQL Server szuka kolumny bez aliasu BusinessEntityID w MyVendors stół. Ponieważ go tam nie ma, wyjrzał na zewnątrz i znalazł go w ProductVendor stół. Szalone, prawda?
Można powiedzieć, że jest to błąd w SQL Server, ale w rzeczywistości jest to zgodne z projektem w standardzie SQL, a Microsoft go zastosował.
W porządku, jasne, nie możemy nic zrobić ze standardem, ale jak możemy uniknąć błędu?
- Najpierw poprzedź nazwy kolumn nazwą tabeli lub użyj aliasu. Innymi słowy, unikaj nazw tabel bez prefiksu lub bez aliasów.
- Po drugie, miej spójne nazewnictwo kolumn. Unikaj posiadania obu BusinessEntityID i BusinessEntity_id na przykład.
Brzmi dobrze? Tak, to wnosi trochę rozsądku do sytuacji.
Ale to nie koniec.
Szalone NULL
Jak wspomniałem, jest więcej do omówienia. T-SQL używa logiki trójwartościowej ze względu na obsługę NULL . I NULL może prawie doprowadzić nas do szału, gdy używamy podzapytań SQL z NIE W .
Zacznę od wprowadzenia tego przykładu:
SELECT b.Name, b.ListPrice, a.BusinessEntityIDFROM Purchasing.ProductVendor aINNER JOIN Produkcja.Produkt b na a.ProductID =b.ProductIDWHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id FROM Purchasing.MyVendors c ) Wynik zapytania prowadzi nas do listy produktów, których nie ma w MyVendors tabela., jak widać poniżej:
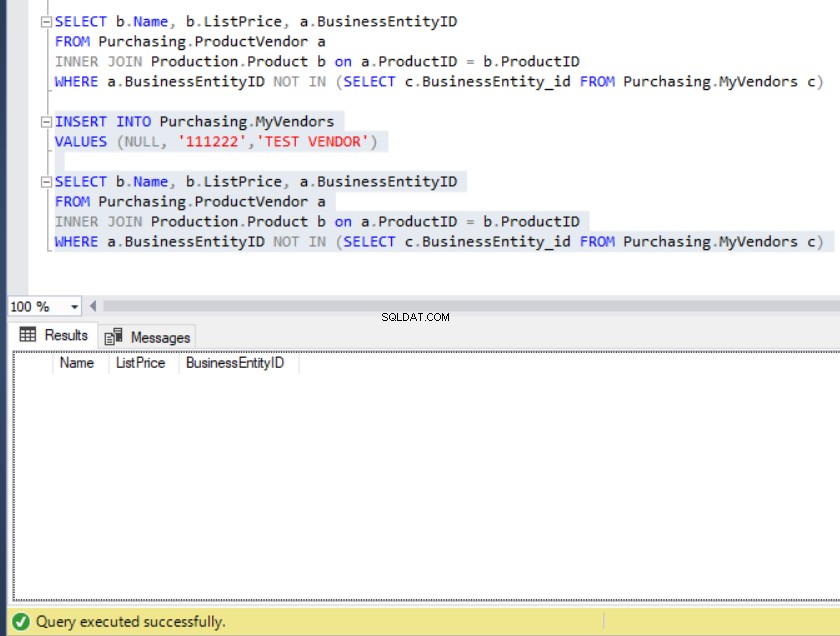
Rysunek 10:Wynik przykładowego zapytania przy użyciu NOT IN
Załóżmy teraz, że ktoś niechcący umieścił rekord w MyVendors tabela z NULL BusinessEntity_id . Co zamierzamy z tym zrobić?
Rysunek 11:Zestaw wyników staje się pusty po wstawieniu NULL BusinessEntity_id do MyVendors
Gdzie się podziały wszystkie dane?
Widzisz, NIE operator zanegował IN orzec. A więc NIEPRAWDA zmieni się teraz na FAŁSZ . Ale NIE NULL jest nieznany. To spowodowało, że filtr odrzucił wiersze, które są NIEZNANE i to jest winowajcą.
Aby upewnić się, że ci się to nie przydarzy:
- Spraw, aby kolumna tabeli nie zezwalała na NULL jeśli dane nie powinny być w ten sposób.
- Lub dodaj nazwę kolumny NIE JEST NULL do Twojego GDZIE klauzula. W naszym przypadku podzapytanie wygląda następująco:
SELECT b.Name, b.ListPrice, a.BusinessEntityIDFROM Purchasing.ProductVendor aINNER JOIN Produkcja.Produkt b na a.ProductID =b.ProductIDWHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id FROM Purchasing.MyVendors c GDZIE c.BusinessEntity_id NIE JEST NULL) Na wynos
Rozmawialiśmy już prawie o podzapytaniach i nadszedł czas, aby przedstawić główne wnioski tego postu w formie skróconej listy:
Podzapytanie:
- to zapytanie w zapytaniu.
- jest ujęty w nawiasy.
- może zastąpić wyrażenie w dowolnym miejscu.
- może być używany w SELECT , WSTAW , AKTUALIZUJ , USUŃ, lub inne instrukcje T-SQL.
- może być samowystarczalny lub skorelowany.
- wyprowadza pojedyncze, wielokrotne lub wartości w tabeli.
- działa z operatorami porównania, takimi jak =, <>,>, <,>=, <=i operatorami logicznymi, takimi jak IN /NIE W i ISTNIEJE /NIE ISTNIEJE .
- nie jest zła ani zła. Może działać lepiej lub gorzej niż JOIN s w zależności od sytuacji. Więc skorzystaj z mojej rady i zawsze sprawdzaj plany wykonania.
- może mieć nieprzyjemne zachowanie na NULL s gdy jest używany z NIE W , a także gdy kolumna nie jest wyraźnie identyfikowana za pomocą tabeli lub aliasu tabeli.
Zapoznaj się z kilkoma dodatkowymi odniesieniami dla przyjemności z czytania:
- Discussion of Subqueries from Microsoft.
- IN (Transact-SQL)
- EXISTS (Transact-SQL)
- ALL (Transact-SQL)
- SOME | ANY (Transact-SQL)
- Comparison Operators