Wprowadzenie
Tabela jest strukturą logiczną. Tworząc tabelę, zwykle nie obchodzi Cię, na którym dysku znajduje się w warstwie pamięci masowej. Jeśli jednak jesteś administratorem bazy danych, ta wiedza może okazać się niezbędna, jeśli musisz przenieść niektóre części bazy danych do alternatywnej pamięci masowej lub woluminu. Następnie możesz chcieć, aby określone tabele znajdowały się na określonym woluminie lub zestawie dysków.
Grupy plików w SQL Server oferują tę warstwę abstrakcji, która pozwala nam kontrolować fizyczną lokalizację naszych struktur logicznych – tabel, indeksów itp.
Grupy plików
Grupa plików to logiczna struktura do grupowania plików danych w SQL Server. Jeśli utworzymy grupę plików i skojarzymy ją z zestawem plików danych, każdy obiekt logiczny utworzony na tej grupie plików będzie fizycznie zlokalizowany w tym zestawie plików fizycznych.
Podstawowym celem takiego fizycznego grupowania plików jest przydzielanie i umieszczanie danych. Na przykład chcemy, aby nasze dane transakcyjne były przechowywane na jednym zestawie szybkich dysków. Jednocześnie potrzebujemy danych historycznych przechowywanych na innym zestawie tańszych dysków. W takim scenariuszu stworzylibyśmy Trans tabela w grupie plików TXN i TranHist tabeli na innej grupie plików HIST. W dalszej części tego artykułu zobaczymy, jak przekłada się to na posiadanie danych na różnych dyskach.
Tworzenie grup plików
Składnia tworzenia grup plików jest pokazana na Listing 1 . Uwaga :kontekst bazy danych to główny Baza danych. Wydając instrukcje, modyfikujemy bazę danych DB2, dodając do niej nowe grupy plików. Zasadniczo te grupy plików są w tym momencie jedynie logicznymi konstrukcjami. Nie zawierają żadnych danych.
-- Listing 1: Creating File Groups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILEGROUP [TXN]
GO
Dodawanie plików do grup plików
Następnym krokiem jest dodanie pliku do każdej z grup plików. Możemy dodać więcej niż jeden plik, ale zachowujemy prostotę w celach demonstracyjnych. Zauważ, że każdy plik znajduje się na zupełnie innym dysku, a składnia pozwala nam określić zamierzoną grupę plików.
-- Listing 2: Adding Files to Filegroups
USE [master]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_HIST_01', FILENAME = N'E:\MSSQL\Data\DB2_HIST_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [HIST]
GO
ALTER DATABASE [DB2] ADD FILE ( NAME = N'DB2_TXN_01', FILENAME = N'C:\MSSQL\Data\DB2_TXN_01.ndf' , SIZE = 102400KB , FILEGROWTH = 131072KB ) TO FILEGROUP [TXN]
GO
Tworzenie tabel do grup plików
Tutaj zapewniamy, że tabele znajdują się na żądanych dyskach. Składnia tworzenia tabel pozwala nam określić żądaną grupę plików.
-- Listing 3: Creating a table on Filegroups TXN and HIST
USE [DB2]
GO
CREATE TABLE [dbo].[tran](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [TXN]
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [TXN]
GO
CREATE TABLE [dbo].[tranhist](
[TranID] [int] NULL
,TranTime [datetime]
,TranAmt [money]
) ON [HIST]
GO
Cofając się o krok, zauważamy, że osiągnęliśmy teraz, co następuje:
- Utworzono dwie grupy plików.
- Określono pliki danych (i dyski) skojarzone z każdą grupą plików.
- Określono tabele skojarzone z każdą grupą plików.
Zasadniczo grupa plików to warstwa abstrakcji .
Sprawdzanie, na których grupach plików znajdują się nasze tabele
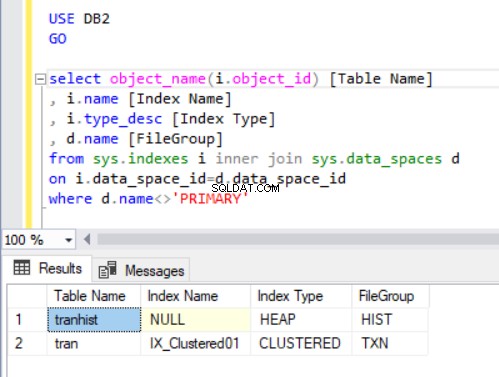
Aby sprawdzić, do jakiej grupy plików należy każda tabela, wykonamy kod z Listingu 4. Używamy dwóch głównych widoków katalogu systemowego:sys.indexes i sys.data_spaces . sys.data_spaces widok katalogu zawiera informacje o grupach plików i partycjach oraz głównych strukturach logicznych, w których przechowywane są tabele i indeksy.
Uwaga:nie używaliśmy sys.tables . SQL Server kojarzy indeksy w tabeli z przestrzeniami danych, a nie z tabelami, jak możemy intuicyjnie sądzić.
-- Listing 4: Check the filegroup of an index or table
USE DB2
GO
select object_name(i.object_id) [Table Name]
, i.name [Index Name]
, i.type_desc [Index Type]
, d.name [FileGroup]
from sys.indexes i inner join sys.data_spaces d
on i.data_space_id=d.data_space_id
where d.name<>'PRIMARY'
Dane wyjściowe zapytania z Listingu 4 zawierają dwie właśnie utworzone tabele. Zauważ, że tranhist tabela nie posiada indeksu. Mimo to pojawia się w zestawie wyników, oznaczony jako sterta .
sterta jest tabelą, która nie ma indeksu klastrowego określającego kolejność danych fizycznie przechowywanych w tabeli. W tabeli może być tylko jeden indeks klastrowy.
Wypełnianie tabeli Tran
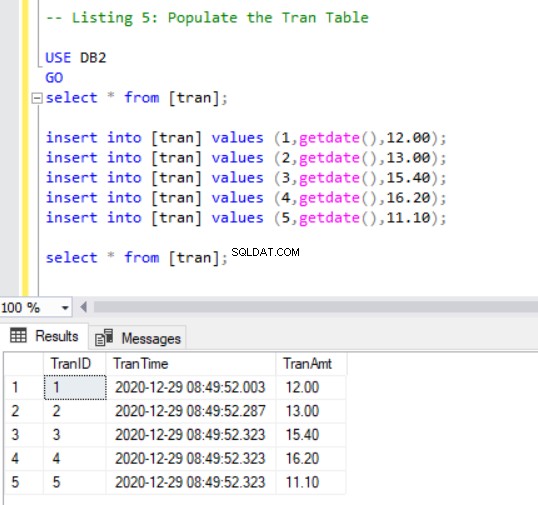
Teraz musimy dodać kilka rekordów do trans tabela używając następującego kodu:
-- Listing 5: Populate the Tran Table
USE DB2
GO
SELECT * FROM [tran];
INSERT INTO [tran] VALUES (1, GETDATE(),12.00);
INSERT INTO [tran] VALUES (2, GETDATE(),13.00);
INSERT INTO [tran] VALUES (3, GETDATE(),15.40);
INSERT INTO [tran] VALUES (4, GETDATE(),16.20);
INSERT INTO [tran] VALUES (5, GETDATE(),11.10);
SELECT * FROM [tran];
Przenoszenie tabeli do innej grupy plików
Aby przenieść trans tabeli do innej grupy plików, musimy tylko odbudować indeks klastrowy i określ nową grupę plików podczas wykonywania tej przebudowy. Listing 5 pokazuje to podejście.
Wykonujemy dwa kroki:najpierw upuszczamy indeks, a następnie odtwarzamy go. W międzyczasie sprawdzamy, czy dane i położenie dwóch tabel, które utworzyliśmy wcześniej, pozostają nienaruszone.
-- Listing 6: Check what filegroup an index or table belongs to
USE [DB2]
GO
DROP INDEX [IX_Clustered01] ON [dbo].[tran] WITH ( ONLINE = OFF )
GO
CREATE CLUSTERED INDEX [IX_Clustered01] ON [dbo].[tran]
(
[TranID] ASC
) ON [HIST]
GO
Usuwając indeks klastrowy z tran tabeli, przekonwertowaliśmy ją na stertę :
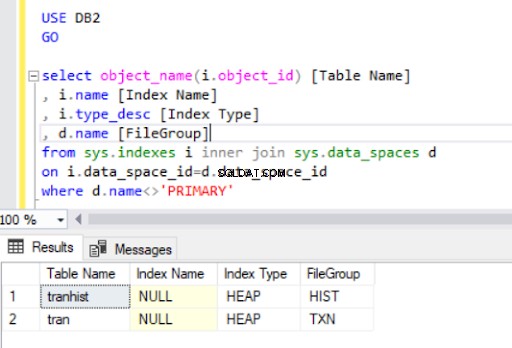
Kiedy odtworzymy indeks klastrowy, zostanie on również wskazany w danych wyjściowych z Listingu 4.
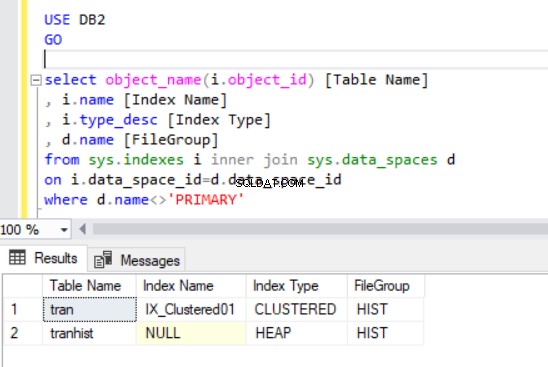
Teraz mamy tran tabeli w grupie plików HIST.
Wniosek
W tym artykule przedstawiono relacje między tabelami, indeksami, plikami i grupami plików w zakresie przechowywania danych programu SQL Server. Wyjaśniliśmy również przenoszenie tabeli z jednej grupy plików do drugiej przez ponowne utworzenie indeksu klastrowanego.
Ta umiejętność będzie pomocna, gdy musisz przenieść dane do nowej pamięci (szybsze dyski lub wolniejsze dyski do archiwizacji). W bardziej zaawansowanych scenariuszach możesz użyć grup plików do zarządzania cyklem życia danych poprzez implementację partycji tabel.
Referencje
- Pliki bazy danych i grupy plików
- Wyłączanie partycji tabeli – przewodnik