Nie ma różnicy.
Powód:
Książki on-line mówią „COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } ) "
„1” jest wyrażeniem innym niż null:jest więc tym samym co COUNT(*) .Optymalizator rozpoznaje to, czym jest:trywialne.
To samo co EXISTS (SELECT * ... lub EXISTS (SELECT 1 ...
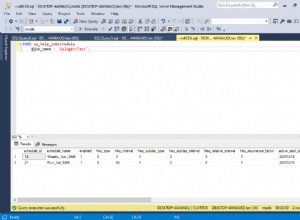
Przykład:
SELECT COUNT(1) FROM dbo.tab800krows
SELECT COUNT(1),FKID FROM dbo.tab800krows GROUP BY FKID
SELECT COUNT(*) FROM dbo.tab800krows
SELECT COUNT(*),FKID FROM dbo.tab800krows GROUP BY FKID
To samo IO, ten sam plan, prace
Edycja, sierpień 2011
Podobne pytanie na DBA.SE.
Edycja, grudzień 2011
COUNT(*) jest wymieniony konkretnie w ANSI-92 (poszukaj "Scalar expressions 125 ")
Sprawa:
a) Jeśli określono COUNT(*), wynikiem jest liczność T.
Oznacza to, że standard ANSI rozpoznaje to jako krwawiące oczywiste, co masz na myśli. COUNT(1) został zoptymalizowany przez dostawców RDBMS ponieważ tego przesądu. W przeciwnym razie zostanie to ocenione zgodnie z ANSI
b) W przeciwnym razie niech TX będzie tabelą jednokolumnową, która jest wynikiem zastosowania