SQL Server 2008 (lub nowszy)
Najpierw w bazie danych utwórz następujące dwa obiekty:
CREATE TYPE dbo.IDList
AS TABLE
(
ID INT
);
GO
CREATE PROCEDURE dbo.DoSomethingWithEmployees
@List AS dbo.IDList READONLY
AS
BEGIN
SET NOCOUNT ON;
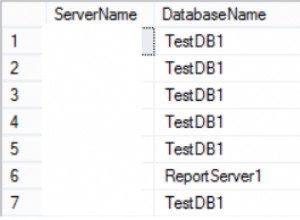
SELECT ID FROM @List;
END
GO
Teraz w kodzie C#:
// Obtain your list of ids to send, this is just an example call to a helper utility function
int[] employeeIds = GetEmployeeIds();
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("ID", typeof(int)));
// populate DataTable from your List here
foreach(var id in employeeIds)
tvp.Rows.Add(id);
using (conn)
{
SqlCommand cmd = new SqlCommand("dbo.DoSomethingWithEmployees", conn);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@List", tvp);
// these next lines are important to map the C# DataTable object to the correct SQL User Defined Type
tvparam.SqlDbType = SqlDbType.Structured;
tvparam.TypeName = "dbo.IDList";
// execute query, consume results, etc. here
}
Serwer SQL 2005
Jeśli używasz SQL Server 2005, nadal polecam funkcję split zamiast XML. Najpierw utwórz funkcję:
CREATE FUNCTION dbo.SplitInts
(
@List VARCHAR(MAX),
@Delimiter VARCHAR(255)
)
RETURNS TABLE
AS
RETURN ( SELECT Item = CONVERT(INT, Item) FROM
( SELECT Item = x.i.value('(./text())[1]', 'varchar(max)')
FROM ( SELECT [XML] = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>') + '</i>').query('.')
) AS a CROSS APPLY [XML].nodes('i') AS x(i) ) AS y
WHERE Item IS NOT NULL
);
GO
Teraz Twoja procedura składowana może być po prostu:
CREATE PROCEDURE dbo.DoSomethingWithEmployees
@List VARCHAR(MAX)
AS
BEGIN
SET NOCOUNT ON;
SELECT EmployeeID = Item FROM dbo.SplitInts(@List, ',');
END
GO
A w kodzie C# wystarczy przekazać listę jako '1,2,3,12' ...
Uważam, że metoda przekazywania parametrów o wartościach tabelarycznych upraszcza konserwację rozwiązania, które go używa i często ma zwiększoną wydajność w porównaniu z innymi implementacjami, w tym XML i dzieleniem ciągów.
Dane wejściowe są jasno określone (nikt nie musi zgadywać, czy separatorem jest przecinek czy średnik) i nie mamy zależności od innych funkcji przetwarzania, które nie są oczywiste bez sprawdzenia kodu procedury składowanej.
W porównaniu z rozwiązaniami wykorzystującymi schemat XML zdefiniowany przez użytkownika zamiast UDT, wymaga to podobnej liczby kroków, ale z mojego doświadczenia wynika, że kod jest znacznie prostszy w zarządzaniu, utrzymaniu i czytaniu.
W wielu rozwiązaniach możesz potrzebować tylko jednego lub kilku z tych UDT (typów zdefiniowanych przez użytkownika), których używasz ponownie w wielu procedurach składowanych. Podobnie jak w tym przykładzie, powszechnym wymaganiem jest przejście przez listę wskaźników identyfikatorów, nazwa funkcji opisuje kontekst, jaki te identyfikatory powinny reprezentować, nazwa typu powinna być ogólna.