Odpowiedź będzie oczywiście brzmiała „to zależy”, ale po przetestowaniu tego celu...
Zakładając
- 1 milion produktów
productma klastrowany indeks naproduct_id- Większość (jeśli nie wszystkie) produktów ma odpowiednie informacje w
product_codestół - Idealne indeksy obecne w
product_codedla obu zapytań.
PIVOT wersja idealnie potrzebuje indeksu product_code(product_id, type) INCLUDE (code) natomiast JOIN wersja idealnie potrzebuje indeksu product_code(type,product_id) INCLUDE (code)
Jeśli są one na miejscu, podając poniższe plany
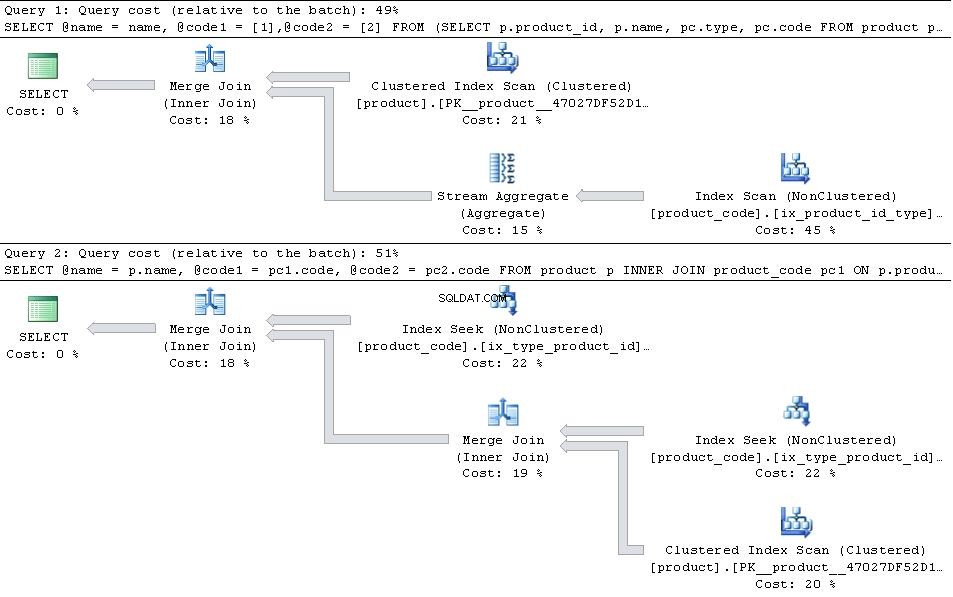
następnie JOIN wersja jest bardziej wydajna.
W przypadku, gdy type 1 i type 2 są jedynymi types w tabeli następnie PIVOT wersja ma nieco przewagę pod względem liczby odczytów, ponieważ nie musi szukać w product_code dwa razy, ale jest to więcej niż przeważone przez dodatkowe obciążenie operatora agregatu strumienia
PIVOT
Table 'product_code'. Scan count 1, logical reads 10467
Table 'product'. Scan count 1, logical reads 4750
CPU time = 3297 ms, elapsed time = 3260 ms.
DOŁĄCZ
Table 'product_code'. Scan count 2, logical reads 10471
Table 'product'. Scan count 1, logical reads 4750
CPU time = 1906 ms, elapsed time = 1866 ms.
Jeśli istnieją dodatkowe type rekordy inne niż 1 i 2 JOIN wersja zwiększy swoją przewagę, ponieważ po prostu łączy połączenia w odpowiednich sekcjach type,product_id indeks, podczas gdy PIVOT plan używa product_id, type więc musiałby przeskanować dodatkowy type wiersze przemieszane z 1 i 2 wiersze.