Poza czubkiem głowy mam dla Ciebie 50% rozwiązanie.
Problem
SSIS naprawdę troszczy się o metadane, więc zmiany w nich mają tendencję do powodowania wyjątków. W tym sensie DTS był znacznie bardziej wyrozumiały. Ta silna potrzeba spójnych metadanych sprawia, że korzystanie z Flat File Source jest kłopotliwe.
Rozwiązanie oparte na zapytaniach
Jeśli problemem jest komponent, nie używajmy go. To, co podoba mi się w tym podejściu, to to, że koncepcyjnie jest to to samo, co wysyłanie zapytań do tabeli — kolejność kolumn nie ma znaczenia, ani obecność dodatkowych kolumn nie ma znaczenia.
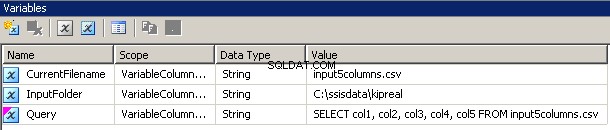
Zmienne
Utworzyłem 3 zmienne, wszystkie typu string:CurrentFileName, InputFolder i Query.
- InputFolder jest na stałe połączony z folderem źródłowym. W moim przykładzie jest to
C:\ssisdata\Kipreal - CurrentFileName to nazwa pliku. W czasie projektowania był to
input5columns.csvale to się zmieni w czasie wykonywania. - Zapytanie to wyrażenie
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Menedżer połączeń
Skonfiguruj połączenie z plikiem wejściowym za pomocą sterownika JET OLEDB. Po utworzeniu go zgodnie z opisem w połączonym artykule zmieniłem jego nazwę na FileOLEDB i ustawiłem wyrażenie w menedżerze połączeń "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Przepływ sterowania
Mój przepływ sterowania wygląda jak zadanie przepływu danych zagnieżdżone w module wyliczającym plików Foreach
Enumerator plików Foreach
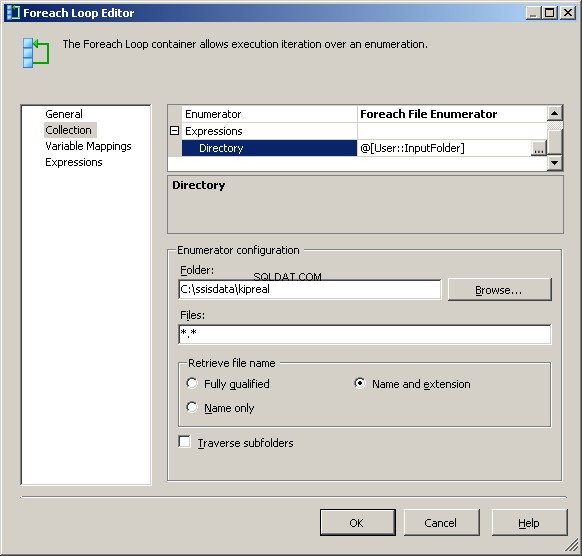
Mój moduł wyliczający plików Foreach jest skonfigurowany do operowania na plikach. Umieściłem wyrażenie w katalogu dla @[User::InputFolder] Zauważ, że w tym momencie, jeśli wartość tego folderu musi się zmienić, zostanie on poprawnie zaktualizowany zarówno w Menedżerze połączeń, jak iw module wyliczającym pliki. W polu „Pobierz nazwę pliku” zamiast domyślnego „W pełni kwalifikowany” wybierz „Nazwa i rozszerzenie”
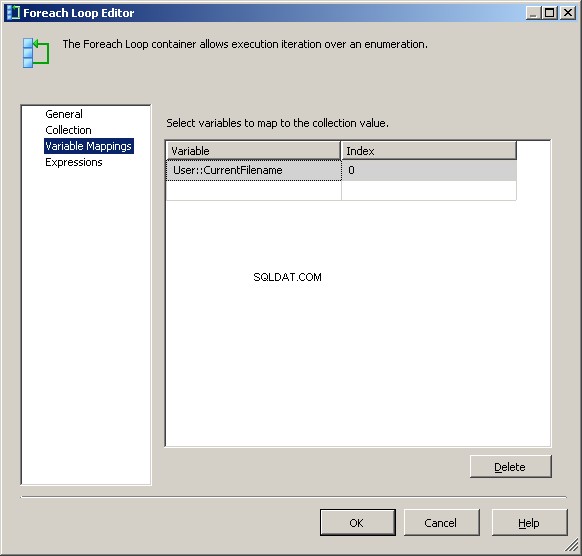
Na karcie Mapowania zmiennych przypisz wartość do naszego @[User::CurrentFileName] zmienna
W tym momencie każda iteracja pętli zmieni wartość @[User::Query aby odzwierciedlić obecną nazwę pliku.
Przepływ danych
To jest właściwie najłatwiejszy kawałek. Użyj źródła OLE DB i podłącz go zgodnie ze wskazówkami.
Użyj menedżera połączeń FileOLEDB i zmień tryb dostępu do danych na "Polecenie SQL ze zmiennej". Użyj @[User::Query] tam zmienna, kliknij OK i jesteś gotowy do pracy. 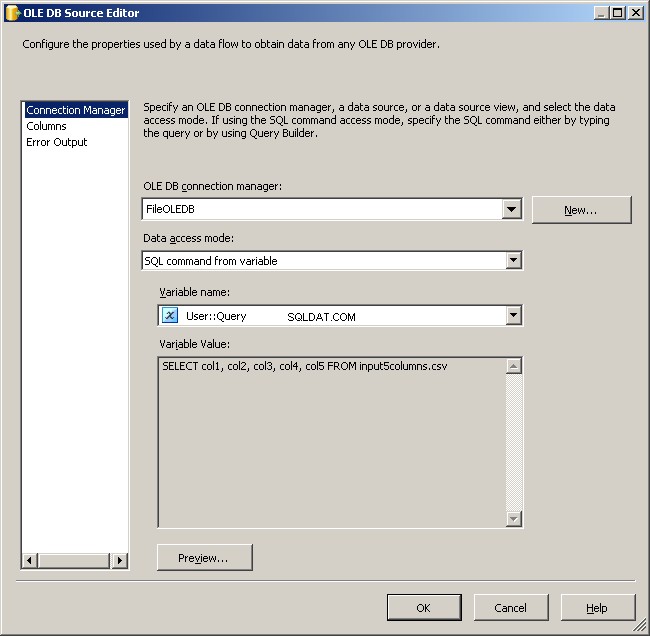
Przykładowe dane
Utworzyłem dwa przykładowe pliki input5columns.csv i input7columns.csv Wszystkie kolumny 5 są w 7, ale 7 ma je w innej kolejności (col2 to pozycja porządkowa 2 i 6). Zanegowałem wszystkie wartości w 7, aby łatwo było widać, który plik jest obsługiwany.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
i
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
Uruchomienie pakietu daje te dwa zrzuty ekranu
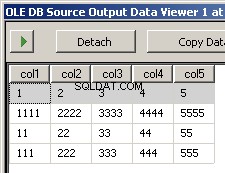
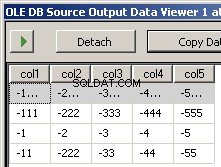
Czego brakuje
Nie znam sposobu, aby powiedzieć podejściu opartemu na zapytaniu, że jest OK, jeśli kolumna nie istnieje. Jeśli istnieje unikalny klucz, przypuszczam, że możesz zdefiniować zapytanie tak, aby zawierało tylko te kolumny, które muszą być tam, a następnie przeprowadzić wyszukiwanie w pliku, aby spróbować uzyskać kolumny, które powinny być tam i nie zawieść wyszukiwania, jeśli kolumna nie istnieje. Jednak dość niezdarne.



