Jest to część serii Problematic Operators SQL Server Internals. Koniecznie przeczytaj pierwszy i drugi post Kalena na ten temat.
SQL Server istnieje od ponad 30 lat, a ja pracuję z SQL Server prawie tak samo długo. Widziałem wiele zmian na przestrzeni lat (i dziesięcioleci!) i wersji tego niesamowitego produktu. W tych postach podzielę się z Wami tym, jak patrzę na niektóre funkcje lub aspekty SQL Server, czasami wraz z odrobiną perspektywy historycznej.
Ostatnio mówiłem o mieszaniu w planie zapytań SQL Server jako potencjalnie problematycznym operatorze w diagnostyce serwera SQL. Haszowanie jest często używane do złączeń i agregacji, gdy nie ma użytecznego indeksu. I podobnie jak skany (o których mówiłem w pierwszym poście z tej serii), są chwile, kiedy hashowanie jest faktycznie lepszym wyborem niż alternatywy. W przypadku złączeń mieszających jedną z alternatyw jest LOOP JOIN, o której również mówiłem ostatnim razem.
W tym poście opowiem Ci o innej alternatywie dla hashowania. Większość alternatyw dla mieszania wymaga sortowania danych, więc albo plan musi zawierać operator SORT, albo wymagane dane muszą być już posortowane ze względu na istniejące indeksy.
Różne typy złączeń w diagnostyce SQL Server
W przypadku operacji JOIN najpopularniejszym i najbardziej użytecznym typem operacji JOIN jest JOIN JOIN. Algorytm dla LOOP JOIN opisałem w poprzednim poście. Chociaż same dane nie muszą być sortowane w przypadku LOOP JOIN, obecność indeksu w wewnętrznej tabeli sprawia, że łączenie jest znacznie wydajniejsze i jak powinieneś wiedzieć, obecność indeksu implikuje pewne sortowanie. Podczas gdy indeks klastrowy sortuje same dane, indeks nieklastrowy sortuje kolumny klucza indeksu. W rzeczywistości w większości przypadków bez indeksu optymalizator SQL Server wybierze algorytm HASH JOIN. Widzieliśmy to w przykładzie ostatnim razem, że bez indeksów wybrano HASH JOIN, a z indeksami otrzymaliśmy LOOP JOIN.
Trzecim typem złączenia jest MERGE JOIN. Ten algorytm działa na dwóch już posortowanych zestawach danych. Jeśli próbujemy połączyć (lub JOIN) dwa zestawy danych, które są już posortowane, wystarczy jedno przejście przez każdy zestaw, aby znaleźć pasujące wiersze. Oto pseudokod algorytmu łączenia przez scalanie:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Chociaż MERGE JOIN jest bardzo wydajnym algorytmem, wymaga, aby oba wejściowe zestawy danych były sortowane według klucza łączenia, co zwykle oznacza posiadanie indeksu klastrowego na kluczu łączenia dla obu tabel. Ponieważ otrzymujesz tylko jeden indeks klastrowany na tabelę, wybranie kolumny klucza klastrowego tylko po to, aby umożliwić MERGE JOINS, może nie być najlepszym wyborem dla klucza klastrowania.
Dlatego zwykle nie zalecam tworzenia indeksów tylko w celu MERGE JOINS, ale jeśli otrzymasz MERGE JOIN z powodu już istniejących indeksów, zwykle jest to dobra rzecz. Oprócz wymagania posortowania obu wejściowych zestawów danych, MERGE JOIN wymaga również, aby co najmniej jeden z zestawów danych miał unikalne wartości dla klucza łączenia.
Spójrzmy na przykład. Najpierw odtworzymy nagłówki i Szczegóły stoły:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Następnie spójrz na plan połączenia między tymi tabelami:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Oto plan:

Zauważ, że nawet przy indeksie klastrowym w obu tabelach otrzymujemy JOIN HASH. Możemy przebudować jeden z indeksów na UNIKATOWY. W tym przypadku musi to być indeks w nagłówkach tabeli, ponieważ jest to jedyna, która ma unikalne wartości dla SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Teraz uruchom zapytanie ponownie i zauważ, że plan działa tak, jak MERGE JOIN.

Plany te korzystają z tego, że dane są już posortowane w indeksie, ponieważ plan wykonania może korzystać z sortowania. Ale czasami SQL Server musi wykonać sortowanie w ramach wykonywania zapytania. Czasami możesz zobaczyć operatora SORT w planie, nawet jeśli nie prosisz o posortowane dane wyjściowe. Jeśli SQL Server uzna, że MERGE JOIN może być dobrą opcją, ale jedna z tabel nie ma odpowiedniego indeksu klastrowego i jest wystarczająco mała, aby sortowanie było bardzo tanie, można przeprowadzić SORTOWANIE, aby umożliwić MERGE JOIN używany.
Ale zwykle operator SORT pojawia się w zapytaniach, w których poprosiliśmy o posortowane dane za pomocą ORDER BY, jak w poniższym przykładzie.
SELECT * FROM Details
ORDER BY ProductID;
GO

Indeks klastrowy jest skanowany (co jest tym samym, co skanowanie tabeli), a następnie wiersze są sortowane zgodnie z żądaniem.
Radzenie sobie z już posortowanym indeksem klastrowym
Ale co, jeśli dane są już posortowane w indeksie klastrowym, a zapytanie zawiera ORDER BY w kolumnie klucza klastrowanego? W powyższym przykładzie zbudowaliśmy indeks klastrowy na SalesOrderID w tabeli Details. Spójrz na następujące dwa pytania:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Jeśli uruchomimy te zapytania razem, okno analizy pakietu Quest Spotlight Tuning Pack wskaże, że oba plany mają równy koszt; każdy to 50% całości. Więc jaka jest właściwie różnica między nimi?
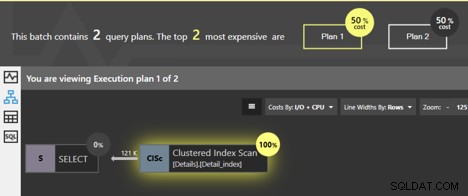
Oba zapytania skanują indeks klastrowy, a SQL Server wie, że jeśli strony na poziomie liścia będą przestrzegane w kolejności, dane zostaną zwrócone w kolejności kluczy klastrowych. Nie trzeba wykonywać dodatkowego sortowania, więc do planu nie jest dodawany operator SORT. Ale jest różnica. Możemy kliknąć operator Clustered Index Scan i uzyskać szczegółowe informacje.
Najpierw spójrz na szczegółowe informacje dla pierwszego planu, dla zapytania bez ORDER BY.

Szczegóły mówią nam, że właściwość „Zamówione” jest fałszem. Nie ma tutaj wymogu, aby dane były zwracane posortowane. Okazuje się, że w większości przypadków najłatwiejszym sposobem pobrania danych jest śledzenie stron indeksu klastrowego, dzięki czemu dane zostaną zwrócone w kolejności, ale nie ma gwarancji. Właściwość False oznacza, że nie ma wymogu, aby SQL Server podążał za uporządkowanymi stronami w celu zwrócenia wyniku. W rzeczywistości istnieją inne sposoby, dzięki którym SQL Server może pobrać wszystkie wiersze tabeli, bez podążania za indeksem klastrowym. Jeśli podczas wykonywania SQL Server wybierze inną metodę pobierania wierszy, nie zobaczymy uporządkowanych wyników.
W przypadku drugiego zapytania szczegóły wyglądają tak:
 Ponieważ zapytanie zawierało ORDER BY, ISTNIEJE wymóg, aby dane były zwracane w kolejności posortowanej i SQL Server będzie podążać za stronami indeksu klastrowego, w kolejności.
Ponieważ zapytanie zawierało ORDER BY, ISTNIEJE wymóg, aby dane były zwracane w kolejności posortowanej i SQL Server będzie podążać za stronami indeksu klastrowego, w kolejności.
Najważniejszą rzeczą do zapamiętania jest to, że NIE gwarantujemy posortowania danych, jeśli w zapytaniu nie uwzględnisz ORDER BY. Tylko dlatego, że masz indeks klastrowy, nadal nie ma gwarancji! Nawet jeśli za każdym razem w ciągu ostatniego roku, w którym uruchomiłeś zapytanie, odzyskiwałeś dane w porządku bez ORDER BY, nie ma gwarancji, że nadal będziesz je odzyskiwać w porządku. Korzystanie z ORDER BY to jedyny sposób na zagwarantowanie kolejności, w jakiej Twoje wyniki są zwracane.
Wskazówki dotyczące korzystania z operacji sortowania
Czy więc SORT jest operacją, której należy unikać w diagnostyce serwera SQL? Podobnie jak skany i operacje haszujące, odpowiedź brzmi oczywiście „to zależy”. Sortowanie może być bardzo kosztowne, zwłaszcza w przypadku dużych zestawów danych. Właściwe indeksowanie pomaga SQL Server uniknąć wykonywania operacji SORT, ponieważ indeks zasadniczo oznacza, że dane są wstępnie posortowane. Ale indeksowanie wiąże się z kosztami. Każdy indeks ma koszt przechowywania, oprócz kosztów utrzymania. Jeśli Twoje dane są mocno zaktualizowane, musisz ograniczyć liczbę indeksów do minimum.
Jeśli okaże się, że niektóre z twoich wolno działających zapytań pokazują w swoich planach operacje SORT i jeśli te SORT są jednymi z najdroższych operatorów w planie, możesz rozważyć utworzenie indeksów, które pozwolą SQL Serverowi uniknąć sortowania. Musisz jednak przeprowadzić dokładne testy, aby upewnić się, że dodatkowe indeksy nie spowalniają innych zapytań, które mają kluczowe znaczenie dla ogólnej wydajności aplikacji.