Indeksy bazy danych służą do przyspieszenia działania bazy danych w tabeli z dużą liczbą rekordów. Indeksy bazy danych (zarówno indeksy klastrowe, jak i indeksy nieklastrowe) są pod względem funkcjonalności bardzo podobne do indeksów książkowych. Indeks książek pozwala od razu przejść do różnych tematów omawianych w książce. Jeśli chcesz wyszukać określony temat, po prostu przejdź do indeksu, znajdź numer strony zawierającej temat, którego szukasz, a następnie możesz przejść bezpośrednio do tej strony. Bez indeksu musiałbyś przeszukać całą książkę.
Indeksy bazy danych działają w ten sam sposób. Bez indeksów musiałbyś przeszukać całą tabelę w celu wykonania określonej operacji na bazie danych. Dzięki indeksom nie musisz przeglądać wszystkich rekordów tabeli. Indeks wskazuje bezpośrednio na rekord, którego szukasz, znacznie skracając czas wykonania zapytania.
Indeksy SQL Server można podzielić na dwa główne typy:
- Indeksy klastrowe
- Indeksy nieklastrowane
W tym artykule przyjrzymy się, czym są indeksy klastrowe i nieklastrowe, jak są tworzone i jakie są główne różnice między nimi. Przyjrzymy się również, kiedy należy używać indeksów klastrowych lub nieklastrowych w SQL Server.
Zacznijmy od indeksu klastrowego.
Indeks klastrowy
Indeks klastrowy to indeks, który definiuje fizyczną kolejność przechowywania rekordów tabeli w bazie danych. Ponieważ może istnieć tylko jeden sposób fizycznego przechowywania rekordów w tabeli bazy danych, może istnieć tylko jeden indeks klastrowy na tabelę. Domyślnie indeks klastrowy jest tworzony w kolumnie klucza podstawowego.
Domyślne indeksy klastrowe
Utwórzmy fikcyjną tabelę z kolumną klucza podstawowego, aby zobaczyć domyślny indeks klastrowy. Wykonaj następujący skrypt:
CREATE DATABASE Hospital
CREATE TABLE Patients
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
age INT NOT NULL
)
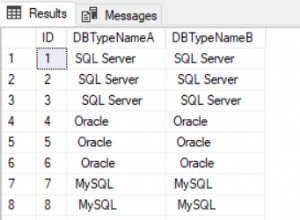
Powyższy skrypt tworzy fikcyjną bazę danych Hospital. Baza posiada 4 kolumny:id, imię, płeć, wiek. Kolumna id jest kolumną klucza podstawowego. Po wykonaniu powyższego skryptu indeks klastrowy jest automatycznie tworzony w kolumnie identyfikatora. Aby zobaczyć wszystkie indeksy w tabeli, możesz użyć procedury przechowywanej „sp_helpindex”.
USE Hospital
EXECUTE sp_helpindex Patients
Oto wynik:

Możesz zobaczyć nazwę indeksu, opis i kolumnę, na której tworzony jest indeks. Jeśli dodasz nowy rekord do tabeli Pacjenci, zostanie on zapisany w porządku rosnącym według wartości w kolumnie id. Jeśli pierwszy rekord wstawiony do tabeli ma identyfikator trzy, rekord zostanie zapisany w trzecim wierszu zamiast w pierwszym wierszu, ponieważ indeks klastrowy utrzymuje porządek fizyczny.
Niestandardowe indeksy klastrowe
Możesz tworzyć własne indeksy klastrowe. Jednak zanim to zrobisz, musisz utworzyć istniejący indeks klastrowy. Mamy jeden indeks klastrowy ze względu na kolumnę klucza podstawowego. Jeśli usuniemy ograniczenie klucza podstawowego, domyślny klaster zostanie usunięty. Poniższy skrypt usuwa ograniczenie klucza podstawowego.
USE Hospital
ALTER TABLE Patients
DROP CONSTRAINT PK__Patients__3213E83F3DFAFAAD
GO
Poniższy skrypt tworzy indeks niestandardowy „IX_tblPatient_Age” w kolumnie wiek tabeli Pacjenci. Dzięki temu indeksowi wszystkie zapisy w tabeli Pacjenci będą przechowywane w porządku rosnącym według wieku.
use Hospital
CREATE CLUSTERED INDEX IX_tblPatient_Age
ON Patients(age ASC)
Dodajmy teraz kilka fikcyjnych rekordów w tabeli Pacjenci, aby sprawdzić, czy rzeczywiście są one wstawiane w porządku rosnącym według wieku:
USE Hospital
INSERT INTO Patients
VALUES
(1, 'Sara', 'Female', 34),
(2, 'Jon', 'Male', 20),
(3, 'Mike', 'Male', 54),
(4, 'Ana', 'Female', 10),
(5, 'Nick', 'Female', 29)
W powyższym skrypcie dodajemy 5 fikcyjnych rekordów. Zwróć uwagę na wartości w kolumnie wiek. Mają wartości losowe i nie są w żadnej logicznej kolejności. Jednak ponieważ utworzyliśmy indeks klastrowy, rekordy będą faktycznie wstawiane w porządku rosnącym według wartości w kolumnie wiek. Możesz to sprawdzić, wybierając wszystkie rekordy z tabeli Pacjenci.
SELECT * FROM Patients
Oto wynik:

Możesz zobaczyć, że rekordy są uporządkowane w porządku rosnącym według wartości w kolumnie wiek.
Indeksy nieklastrowane
Indeks nieklastrowy jest również używany do przyspieszenia operacji wyszukiwania. W przeciwieństwie do indeksu klastrowego indeks nieklastrowy nie definiuje fizycznie kolejności, w jakiej rekordy są wstawiane do tabeli. W rzeczywistości indeks nieklastrowy jest przechowywany w innej lokalizacji niż tabela danych. Indeks nieklastrowy jest jak indeks książkowy, który znajduje się oddzielnie od głównej treści książki. Ponieważ indeksy nieklastrowe znajdują się w oddzielnej lokalizacji, w tabeli może znajdować się wiele indeksów nieklastrowych.
Aby utworzyć indeks nieklastrowy, musisz użyć instrukcji „CREATE NOCLUSTERED”. Pozostała składnia pozostaje taka sama jak składnia tworzenia indeksu klastrowego. Poniższy skrypt tworzy indeks nieklastrowy „IX_tblPatient_Name”, który sortuje rekordy w porządku rosnącym według nazwy.
use Hospital
CREATE NONCLUSTERED INDEX IX_tblPatient_Name
ON Patients(name ASC)
Powyższy skrypt utworzy indeks zawierający imiona i nazwiska pacjentów oraz adresy odpowiadających im zapisów, jak pokazano poniżej:
| Nazwa | Adres rekordu |
| Ana | Record Address |
| Jon | Record Address |
| Mike | Record Address |
| nick | Record Address |
| Sara | Record Address |
Tutaj „Adres rekordu” w każdym wierszu jest odniesieniem do rzeczywistych rekordów tabeli dla Pacjentów o odpowiadających im nazwiskach.
Na przykład, jeśli chcesz pobrać wiek i płeć pacjenta o imieniu „Mike”, baza danych najpierw przeszuka „Mick” w indeksie nieklastrowym „IX_tblPatient_Name”, a z indeksu nieklastrowego pobierze rzeczywiste odniesienie do rekordu i użyje go do zwrócenia rzeczywistego wieku i płci Pacjenta o imieniu „Mike”
Ponieważ baza danych musi przeprowadzić dwa wyszukiwania, najpierw w indeksie nieklastrowym, a następnie w rzeczywistej tabeli, indeksy nieklastrowe mogą działać wolniej podczas operacji wyszukiwania. Jednak w przypadku operacji INSERT i UPDATE indeksy nieklastrowane są szybsze, ponieważ kolejność rekordów wymaga aktualizacji tylko w indeksie, a nie w rzeczywistej tabeli.
Kiedy używać indeksów klastrowych lub nieklastrowych
Teraz, gdy znasz już różnice między indeksem klastrowym i nieklastrowym, przyjrzyjmy się różnym scenariuszom użycia każdego z nich.
1. Liczba indeksów
To dość oczywiste. Jeśli potrzebujesz utworzyć wiele indeksów w swojej bazie danych, wybierz indeks nieklastrowy, ponieważ może istnieć tylko jeden indeks klastrowy.
2. WYBIERZ operacje
Jeśli chcesz wybrać tylko wartość indeksu, która jest używana do tworzenia i indeksowania, indeksy nieklastrowane są szybsze. Na przykład, jeśli utworzyłeś indeks w kolumnie „nazwa” i chcesz wybrać tylko nazwę, indeksy nieklastrowane szybko zwrócą nazwę.
Jeśli jednak chcesz wybrać inne wartości kolumny, takie jak wiek, płeć za pomocą indeksu nazwisk, operacja SELECT będzie wolniejsza, ponieważ najpierw zostanie wyszukane imię i nazwisko z indeksu, a następnie do wyszukiwania zostanie użyte odwołanie do rzeczywistego rekordu tabeli wiek i płeć.
Z drugiej strony, w przypadku indeksów klastrowych, ponieważ wszystkie rekordy są już posortowane, operacja SELECT jest szybsza, jeśli dane są wybierane z kolumn innych niż kolumna z indeksem klastrowym.
3. INSERT/UPDATE Operacje
Operacje INSERT i UPDATE są szybsze w przypadku indeksów nieklastrowych, ponieważ rzeczywiste rekordy nie muszą być sortowane podczas wykonywania operacji INSERT lub UPDATE. Aktualizacji wymaga raczej tylko indeks nieklastrowany.
4. Miejsce na dysku
Ponieważ indeksy nieklastrowe są przechowywane w innej lokalizacji niż oryginalna tabela, indeksy nieklastrowe zajmują dodatkowe miejsce na dysku. Jeśli problemem jest miejsce na dysku, użyj indeksu klastrowego.
5. Ostateczny werdykt
Zgodnie z ogólną zasadą, każda tabela powinna mieć co najmniej jeden indeks klastrowy, najlepiej w kolumnie używanej do WYBIERANIA rekordów i zawierającej unikatowe wartości. Kolumna klucza podstawowego jest idealnym kandydatem do indeksu klastrowego.
Z drugiej strony kolumny, które są często zaangażowane w zapytania INSERT i UPDATE, powinny mieć indeks nieklastrowany, zakładając, że miejsce na dysku nie jest problemem.