SQL Server 2014 CTP1 jest już dostępny od kilku tygodni i prawdopodobnie spotkałeś się z dużym naciskiem na tabele zoptymalizowane pod kątem pamięci i aktualizowalne indeksy magazynu kolumn. Chociaż są one z pewnością godne uwagi, w tym poście chciałem zapoznać się z nowym ulepszeniem równoległości SELECT… INTO. Ulepszenie jest jedną z tych gotowych do noszenia zmian, które z wyglądu nie będą wymagały znaczących zmian w kodzie, aby zacząć z niego korzystać. Moje badania zostały przeprowadzone przy użyciu wersji Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition.
RÓWNOLEGLE WYBIERZ … DO
SQL Server 2014 wprowadza obsługę równoległą SELECT ... INTO dla baz danych i do przetestowania tej funkcji użyłem bazy danych AdventureWorksDW2012 i wersji tabeli FactInternetSales, która zawierała 61 847 552 wierszy (byłem odpowiedzialny za dodanie tych wierszy; domyślnie nie są one dostarczane z bazą danych).
Ponieważ ta funkcja, od CTP1, wymaga poziomu zgodności bazy danych 110, do celów testowych ustawiłem bazę danych na poziom zgodności 100 i wykonałem następujące zapytanie dla mojego pierwszego testu:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; Czas wykonywania zapytania wynosił 3 minuty i 19 sekund na mojej testowej maszynie wirtualnej, a rzeczywisty plan wykonania zapytania był następujący:

SQL Server korzystał z planu szeregowego, jak się spodziewałem. Zauważ również, że moja tabela zawierała indeks nieklastrowanego magazynu kolumn, który został przeskanowany (utworzyłem ten nieklastrowany indeks magazynu kolumn do użytku z innymi testami, ale później pokażę ci również plan wykonania zapytania indeksu magazynu kolumn w klastrach). Plan nie używał równoległości, a skanowanie indeksu magazynu kolumn używało trybu wykonywania wierszy zamiast trybu wykonywania wsadowego.
Następnie zmodyfikowałem poziom zgodności bazy danych (i zauważ, że nie ma jeszcze poziomu zgodności SQL Server 2014 w CTP1):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Upuściłem tabelę FactInternetSales_V2, a następnie ponownie wykonałem mój oryginalny SELECT ... INTO operacja. Tym razem czas wykonania zapytania wynosił 1 minutę i 7 sekund, a rzeczywisty plan wykonania zapytania wyglądał następująco:
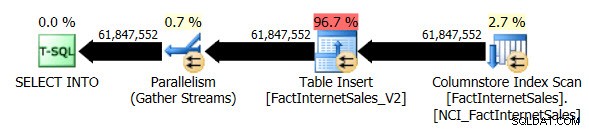
Mamy teraz równoległy plan i jedyną zmianą, jaką musiałem wprowadzić, był poziom zgodności bazy danych dla AdventureWorksDW2012. Moja testowa maszyna wirtualna ma przydzielone do niej cztery procesory wirtualne, a plan wykonania zapytania rozdziela wiersze na cztery wątki:

Nieklastrowane skanowanie indeksu magazynu kolumn, podczas korzystania z równoległości, nie używało trybu wykonywania wsadowego. Zamiast tego używał trybu wykonywania wierszy.
Oto tabela przedstawiająca dotychczasowe wyniki testów:
| Typ skanowania | Poziom zgodności | RÓWNOLEGLE WYBIERZ … DO | Tryb wykonywania | Czas trwania |
|---|---|---|---|---|
| Skanowanie indeksu magazynu kolumn bez klastrów | 100 | Nie | Wiersz | 3:19 |
| Skanowanie indeksu magazynu kolumn bez klastrów | 110 | Tak | Wiersz | 1:07 |
Więc w następnym teście upuściłem nieklastrowany indeks magazynu kolumn i ponownie wykonałem SELECT ... INTO zapytanie przy użyciu poziomu zgodności bazy danych 100 i 110.
Test na poziomie zgodności 100 trwał 5 minut i 44 sekundy i został wygenerowany następujący plan:
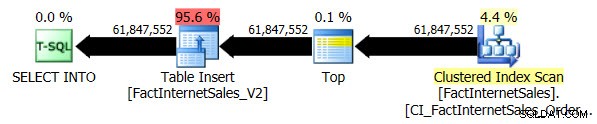
Szeregowe skanowanie indeksu klastrowego zajęło 2 minuty i 25 sekund dłużej niż szeregowe skanowanie indeksu magazynu bezklastrowego.
Przy użyciu poziomu zgodności 110 uruchomienie zapytania zajęło 1 minutę i 55 sekund i wygenerowano następujący plan:

Podobnie jak w przypadku równoległego testu nieklastrowego skanowania indeksu magazynu kolumn, równoległe skanowanie indeksu klastrowego jest rozproszone w czterech wątkach:
Poniższa tabela podsumowuje te dwa wyżej wymienione testy:
| Typ skanowania | Poziom zgodności | RÓWNOLEGLE WYBIERZ … DO | Tryb wykonywania | Czas trwania |
|---|---|---|---|---|
| Skanowanie indeksu klastrowego | 100 | Nie | Wiersz (nie dotyczy) | 5:44 |
| Skanowanie indeksu klastrowego | 110 | Tak | Wiersz (nie dotyczy) | 1:55 |
Zatem zastanawiałem się nad wydajnością klastrowanego indeksu magazynu kolumn (nowość w SQL Server 2014), więc upuściłem istniejące indeksy i utworzyłem klastrowany indeks magazynu kolumn w tabeli FactInternetSales. Musiałem również usunąć osiem różnych ograniczeń kluczy obcych zdefiniowanych w tabeli, zanim mogłem utworzyć klastrowany indeks magazynu kolumn.
Dyskusja staje się nieco akademicka, ponieważ porównuję SELECT ... INTO wydajność na poziomach zgodności bazy danych, które nie oferowały klastrowanych indeksów magazynu kolumn – podobnie jak wcześniejsze testy dla nieklastrowanych indeksów magazynu kolumn na poziomie zgodności bazy danych 100 – a mimo to warto zobaczyć i porównać ogólną charakterystykę wydajności.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
Nawiasem mówiąc, operacja utworzenia klastrowanego indeksu magazynu kolumn w tabeli 61 847 552 milionów wierszy zajęła 11 minut i 25 sekund z czterema dostępnymi procesorami wirtualnymi (z których operacja wykorzystywała je wszystkie), 4 GB pamięci RAM i wirtualną pamięcią gości na dyskach SSD OCZ Vertex. W tym czasie procesory nie były ustawione przez cały czas, ale raczej wyświetlały szczyty i doliny (próbka 60 sekund aktywności procesora pokazana poniżej):
Po utworzeniu klastrowanego indeksu magazynu kolumn ponownie wykonałem dwa SELECT ... INTO testy. Test poziomu zgodności 100 trwał 3 minuty i 22 sekundy, a plan był planem szeregowym zgodnie z oczekiwaniami (pokazuję wersję planu SQL Server Management Studio od czasu klastrowanego skanowania indeksu magazynu kolumn, od SQL Server 2014 CTP1 , nie jest jeszcze w pełni rozpoznawany przez Eksplorator planów):

Następnie zmieniłem poziom zgodności bazy danych na 110 i ponownie wykonałem test, który tym razem trwał 1 minutę i 11 sekund i miał następujący rzeczywisty plan wykonania:

Plan rozłożył wiersze na cztery wątki i podobnie jak nieklastrowany indeks magazynu kolumn, trybem wykonywania klastrowanego skanowania indeksu magazynu kolumn był wiersz, a nie wsadowy.
Poniższa tabela podsumowuje wszystkie testy w tym poście (w kolejności czasu trwania, od niskiego do wysokiego):
| Typ skanowania | Poziom zgodności | RÓWNOLEGLE WYBIERZ … DO | Tryb wykonywania | Czas trwania |
|---|---|---|---|---|
| Skanowanie indeksu magazynu kolumn bez klastrów | 110 | Tak | Wiersz | 1:07 |
| Skanowanie indeksu klastrowego magazynu kolumn | 110 | Tak | Wiersz | 1:11 |
| Skanowanie indeksu klastrowego | 110 | Tak | Wiersz (nie dotyczy) | 1:55 |
| Skanowanie indeksu magazynu kolumn bez klastrów | 100 | Nie | Wiersz | 3:19 |
| Skanowanie indeksu klastrowego magazynu kolumn | 100 | Nie | Wiersz | 3:22 |
| Skanowanie indeksu klastrowego | 100 | Nie | Wiersz (nie dotyczy) | 5:44 |
Kilka obserwacji:
- Nie jestem pewien, czy różnica między równoległym
SELECT ... INTOoperacja względem nieklastrowanego indeksu magazynu kolumn w porównaniu z klastrowanym indeksem magazynu kolumn jest statystycznie istotna. Musiałbym zrobić więcej testów, ale myślę, że poczekałbym z ich wykonaniem do czasu RTM. - Mogę śmiało powiedzieć, że równoległy
SELECT ... INTOznacznie przewyższała seryjne odpowiedniki w testach indeksu klastrowanego, nieklastrowanego magazynu kolumn i klastrowanego magazynu kolumn.
Warto wspomnieć, że te wyniki dotyczą wersji CTP produktu, a moje testy powinny być postrzegane jako coś, co może zmienić zachowanie przez RTM – więc mniej interesowały mnie czasy trwania autonomiczne w porównaniu z tym, jak te czasy trwania w porównaniu między seryjnymi i równoległymi warunki.
Niektóre funkcje wydajności wymagają znacznej refaktoryzacji – ale dla SELECT ... INTO poprawy, wszystko, co musiałem zrobić, to podnieść poziom zgodności bazy danych, aby zacząć dostrzegać korzyści, co zdecydowanie doceniam.