Jeśli chodzi o graficzne plany wykonania, istnieje tylko jedna ikona sortowania fizycznego w SQL Server:

Ta sama ikona jest używana dla trzech logicznych operatorów sortowania:Sortuj, Sortuj do góry N i Sortuj odrębne:
Idąc głębiej, istnieją cztery różne implementacje sortowania w silniku wykonawczym (nie licząc sortowania wsadowego dla zoptymalizowanych połączeń pętli, co nie jest pełnym sortowaniem i i tak nie jest widoczne w planach). Jeśli używasz SQL Server 2014, liczba implementacji sortowania silnika wykonawczego wzrasta do siedmiu:
- CQScanSortujNowość
- CQScanTopSortujNowość
- CQScanIndex SortujNowość
- CQScanPartitionSortNew (tylko SQL Server 2014)
- CQScanInPamięćSortujNowość
- In-Memory OLTP (Hekaton) skompilowana natywnie procedura Top N Sort (tylko SQL Server 2014)
- In-Memory OLTP (Hekaton) skompilowana natywnie procedura Ogólne sortowanie (tylko SQL Server 2014)
W tym artykule omówiono te implementacje sortowania i kiedy każdy z nich jest używany w programie SQL Server. Część pierwsza obejmuje pierwsze cztery pozycje na liście.
1. CQScanSortNew
Jest to najbardziej ogólna klasa sortowania, używana, gdy żadna z innych dostępnych opcji nie ma zastosowania. Sortowanie ogólne wykorzystuje przyznanie pamięci obszaru roboczego zarezerwowane tuż przed rozpoczęciem wykonywania zapytania. Ta dotacja jest proporcjonalna do szacunków liczności i średniej wielkości wierszy i nie można jej zwiększyć po rozpoczęciu wykonywania zapytania.
Obecna implementacja wydaje się wykorzystywać różne wewnętrzne sortowanie przez scalanie (być może binarne sortowanie przez scalanie), przechodząc do zewnętrznego sortowania przez scalanie (w razie potrzeby z wieloma przebiegami), jeśli zarezerwowana pamięć okazuje się niewystarczająca. Zewnętrzne sortowanie przez scalanie wykorzystuje fizyczne tempdb miejsce na przebiegi sortowania, które nie mieszczą się w pamięci (powszechnie znane jako rozlewanie sortowania). Sortowanie ogólne można również skonfigurować tak, aby podczas operacji sortowania stosowano odmienność.
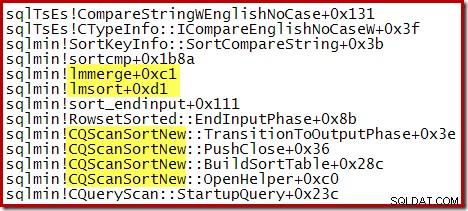
Poniższy częściowy ślad stosu przedstawia przykład CQScanSortNew klas sortowania ciągów za pomocą wewnętrznego sortowania przez scalanie:
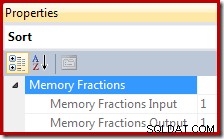
W planach wykonania Sort dostarcza informacji o ułamku całkowitego przydziału pamięci obszaru roboczego zapytania, który jest dostępny dla sortowania podczas odczytywania rekordów (faza wejściowa) oraz ułamku dostępnego, gdy posortowane dane wyjściowe są zużywane przez operatorów planu nadrzędnego (faza wyjściowa ).
Frakcja przyznania pamięci to liczba z zakresu od 0 do 1 (gdzie 1 =100% przyznanej pamięci) i jest widoczna w SSMS po podświetleniu Sortuj i przejrzeniu okna Właściwości. Poniższy przykład został zaczerpnięty z zapytania z tylko jednym operatorem sortowania, więc ma dostęp do pełnego przydziału pamięci obszaru roboczego zapytania zarówno w fazie wejściowej, jak i wyjściowej:
Ułamki pamięci odzwierciedlają fakt, że podczas fazy wejściowej Sort musi udostępniać ogólne przyznanie pamięci zapytań ze współbieżnie wykonywanymi operatorami zużywającymi pamięć poniżej w planie wykonania. Podobnie, podczas fazy wyjściowej, Sort musi współdzielić przyznaną pamięć z współbieżnie wykonywanymi operatorami zużywającymi pamięć powyżej w planie wykonania.
Procesor zapytań jest wystarczająco inteligentny, aby wiedzieć, że niektóre operatory blokują (stop-and-go), skutecznie wyznaczając granice, w których przydział pamięci może zostać wykorzystany i ponownie wykorzystany. W planach równoległych część przyznania pamięci dostępna dla ogólnego sortowania jest dzielona równo między wątki i nie może być ponownie zrównoważona w czasie wykonywania w przypadku przekrzywienia (częsta przyczyna rozlewania w równoległych planach sortowania).
SQL Server 2012 i nowsze zawierają dodatkowe informacje na temat minimalnego przydziału pamięci do obszaru roboczego wymaganego do zainicjowania operatorów planu zużywających pamięć oraz pożądane przyznanie pamięci ("idealna" ilość pamięci szacowana jako potrzebna do zakończenia całej operacji w pamięci). W planie wykonania po wykonaniu („rzeczywistym”) pojawiły się również nowe informacje o wszelkich opóźnieniach w uzyskaniu przydziału pamięci, maksymalnej faktycznie wykorzystanej ilości pamięci i sposobie rozłożenia rezerwacji pamięci na węzły NUMA.
Wszystkie poniższe przykłady AdventureWorks używają CQScanSortNew sortowanie ogólne:
-- An Ordinary Sort (CQScanSortNew)
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Distinct Sort (also CQScanSortNew)
SELECT DISTINCT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName;
-- Same query expressed using GROUP BY
-- Same Distinct Sort (CQScanSortNew) execution plan
SELECT
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
GROUP BY
P.FirstName,
P.MiddleName,
P.LastName
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Pierwsze zapytanie (sortowanie nieodróżniające) daje następujący plan wykonania:
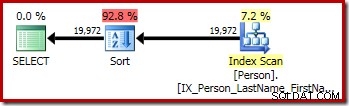
Drugie i trzecie (równoważne) zapytanie tworzą ten plan:
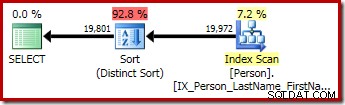
CQScanSortNew może być używany zarówno do logicznego ogólnego sortowania, jak i logicznego sortowania odrębnego.
2. CQScanTopSortNowość
CQScanTopSortNowy jest podklasą CQScanSortNew używany do implementacji sortowania Top N (jak sama nazwa wskazuje). CQScanTopSortNowy deleguje większość podstawowej pracy do CQScanSortNew , ale modyfikuje szczegółowe zachowanie na różne sposoby, w zależności od wartości N.
Dla N> 100, CQScanTopSortNew jest zasadniczo zwykłym CQScanSortNew sort, który automatycznie przestaje tworzyć posortowane wiersze po N wierszach. Dla N <=100, CQScanTopSortNew zachowuje tylko bieżące wyniki Top N podczas operacji sortowania i śledzi najniższą wartość klucza, która obecnie się kwalifikuje.
Na przykład podczas zoptymalizowanego sortowania Top N (gdzie N <=100) stos wywołań zawiera RowsetTopN podczas gdy z ogólnym sortowaniem w sekcji 1 widzieliśmy RowsetSorted :
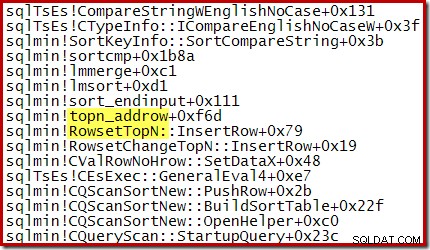
W przypadku sortowania Top N, gdzie N> 100, stos wywołań na tym samym etapie wykonywania jest taki sam jak sortowanie ogólne widziane wcześniej:
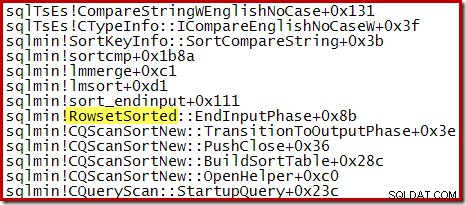
Zauważ, że CQScanTopSortNew nazwa klasy nie pojawia się w żadnym z tych śladów stosu. Wynika to po prostu ze sposobu działania podklas. W innych momentach wykonywania tych zapytań CQScanTopSortNew metody (np. Open, GetRow i CreateTopNTable) pojawiają się jawnie na stosie wywołań. Jako przykład, poniższe zostało wykonane na późniejszym etapie wykonywania zapytania i pokazuje CQScanTopSortNew nazwa klasy:
Sortowanie Top N i optymalizator zapytań
Optymalizator zapytań nie wie nic o sortowaniu Top N, które jest tylko operatorem silnika wykonywania. Gdy optymalizator utworzy drzewo wyjściowe z fizycznym operatorem Top bezpośrednio nad (nieodrębnym) fizycznym sortowaniem, przepisanie po optymalizacji może zwinąć dwie fizyczne operacje w jeden operator Top N Sort. Nawet w przypadku N> 100, oznacza to oszczędności w przejściu wierszy iteracyjnie między wyjściem Sort a wejściem Top.
Poniższe zapytanie używa kilku nieudokumentowanych flag śledzenia, aby pokazać dane wyjściowe optymalizatora i przepisywanie po optymalizacji w akcji:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName
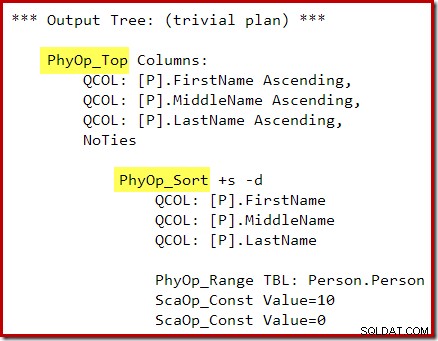
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 7352); Drzewo wyjściowe optymalizatora pokazuje oddzielne fizyczne operatory Top i Sort:
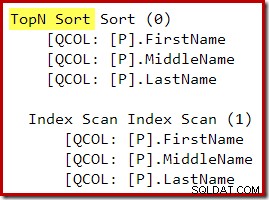
Po przepisaniu po optymalizacji, Top i Sort zostały połączone w jeden Top N Sort:
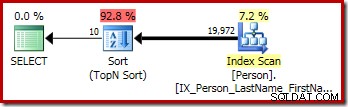
Graficzny plan wykonania powyższego zapytania T-SQL pokazuje pojedynczy operator sortowania Top N:
Przełamywanie przepisywania Top N Sort
Przepisywanie po optymalizacji Top N Sort może tylko zwinąć sąsiednie Top N Sort do Top N Sort. Dodanie DISTINCT (lub równoważnej klauzuli GROUP BY) do powyższego zapytania zapobiegnie przepisaniu Top N Sort:
SELECT DISTINCT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Ostateczny plan wykonania tego zapytania zawiera oddzielne operatory Top i Sort (Distinct Sort):
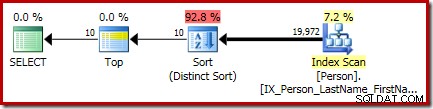
Sortowanie to ogólne CQScanSortNew klasa działa w odrębnym trybie, jak pokazano w sekcji 1 wcześniej.
Drugim sposobem zapobiegania przepisywania do sortowania Top N jest wprowadzenie jednego lub więcej dodatkowych operatorów między Top i Sort. Na przykład:
SELECT TOP (10)
P.FirstName,
P.MiddleName,
P.LastName,
rn = RANK() OVER (ORDER BY P.FirstName)
FROM Person.Person AS P
ORDER BY
P.FirstName,
P.MiddleName,
P.LastName; Tak się składa, że dane wyjściowe optymalizatora zapytań zawierają teraz operację między Top i Sort, więc sortowanie Top N nie jest generowane podczas fazy przepisywania po optymalizacji:
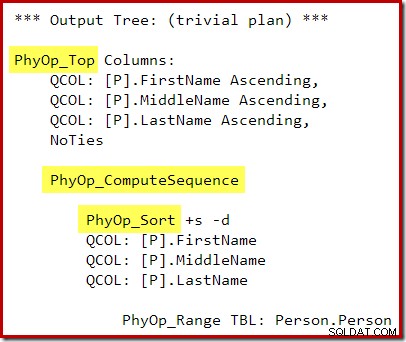
Plan wykonania to:

Sekwencja obliczeń (zaimplementowana jako dwa segmenty i projekt sekwencji) między Top i Sort zapobiega zwinięciu Top i Sort do jednego operatora Top N Sort. Oczywiście ten plan nadal zapewnia prawidłowe wyniki, ale wykonanie może być nieco mniej wydajne niż w przypadku połączonego operatora sortowania Top N.
3. CQScanIndexSortNew
CQScanIndexSortNew służy tylko do sortowania w planach budowy indeksu DDL. Ponownie wykorzystuje niektóre ogólne funkcje sortowania, które już widzieliśmy, ale dodaje określone optymalizacje dla wstawiania indeksów. Jest to również jedyna klasa sortująca, która może dynamicznie żądać większej ilości pamięci po rozpoczęciu egzekucji.
Szacowanie liczności jest często dokładne dla planu budowania indeksu, ponieważ łączna liczba wierszy w tabeli jest zwykle znaną wielkością. Nie oznacza to, że przydziały pamięci dla sortowania planu budowania indeksu będą zawsze dokładne; po prostu sprawia, że demonstracja jest trochę trudniejsza. Tak więc następujący przykład używa nieudokumentowanego, ale dość dobrze znanego rozszerzenia polecenia UPDATE STATISTICS, aby zmylić optymalizator, aby pomyślał, że tabela, na której budujemy indeks, ma tylko jeden wiersz:
-- Test table
CREATE TABLE dbo.People
(
FirstName dbo.Name NOT NULL,
LastName dbo.Name NOT NULL
);
GO
-- Copy rows from Person.Person
INSERT dbo.People WITH (TABLOCKX)
(
FirstName,
LastName
)
SELECT
P.FirstName,
P.LastName
FROM Person.Person AS P;
GO
-- Pretend the table only has 1 row and 1 page
UPDATE STATISTICS dbo.People
WITH ROWCOUNT = 1, PAGECOUNT = 1;
GO
-- Index building plan
CREATE CLUSTERED INDEX cx
ON dbo.People (LastName, FirstName);
GO
-- Tidy up
DROP TABLE dbo.People; Plan wykonania po wykonaniu („rzeczywisty”) dla kompilacji indeksu nie wyświetla ostrzeżenia o rozlanym sortowaniu (w przypadku uruchomienia w programie SQL Server 2012 lub nowszym) pomimo oszacowania jednego wiersza i rzeczywiście posortowanych 19 972 wierszy:
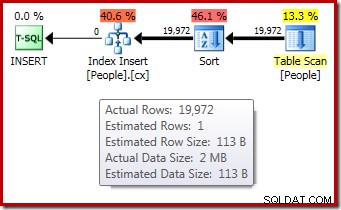
Potwierdzenie, że początkowy przydział pamięci został dynamicznie rozszerzony, pochodzi z analizy właściwości iteratora głównego. Zapytanie początkowo otrzymało 1024 KB pamięci, ale ostatecznie pochłonęło 1576 KB:
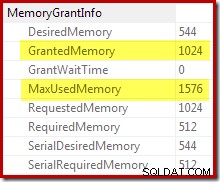
Dynamiczny wzrost przyznanej pamięci można również śledzić za pomocą kanału debugowania Extended Event sort_memory_grant_adjustment. To zdarzenie jest generowane za każdym razem, gdy alokacja pamięci jest dynamicznie zwiększana. Jeśli to zdarzenie jest monitorowane, możemy przechwycić ślad stosu po jego opublikowaniu, za pośrednictwem zdarzeń rozszerzonych (z pewną niezręczną konfiguracją i flagą śledzenia) lub z dołączonego debugera, jak poniżej:
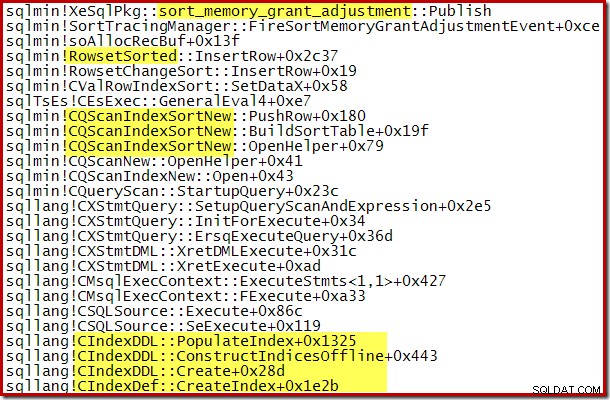
Dynamiczne rozszerzanie przyznawania pamięci może również pomóc w równoległych planach budowania indeksów, w których rozkład wierszy w wątkach jest nierównomierny. Ilość pamięci, którą można w ten sposób wykorzystać, nie jest jednak nieograniczona. SQL Server sprawdza za każdym razem, gdy potrzebne jest rozszerzenie, aby sprawdzić, czy żądanie jest uzasadnione, biorąc pod uwagę dostępne w tym czasie zasoby.
Pewien wgląd w ten proces można uzyskać, włączając nieudokumentowaną flagę śledzenia 1504 wraz z 3604 (dla danych wyjściowych komunikatów do konsoli) lub 3605 (dane wyjściowe do dziennika błędów programu SQL Server). Jeśli plan budowania indeksu jest równoległy, skuteczny jest tylko 3605, ponieważ równoległe procesy robocze nie mogą wysyłać komunikatów śledzenia między wątkami do konsoli.
Poniższa sekcja danych wyjściowych śledzenia została przechwycona podczas tworzenia umiarkowanie dużego indeksu na instancji SQL Server 2014 z ograniczoną pamięcią:
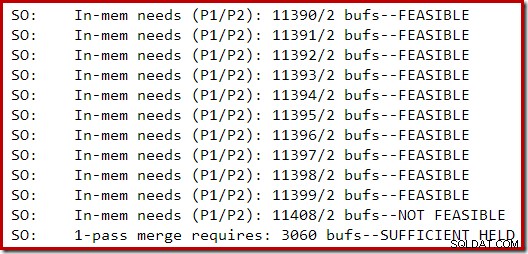
Rozszerzanie pamięci dla sortowania trwało do momentu uznania żądania za niewykonalne, w którym to momencie ustalono, że była już wystarczająca ilość pamięci, aby zakończyć jednoprzebiegowe rozlanie sortowania.
4. CQScanPartitionSortNew
Ta nazwa klasy może sugerować, że ten typ sortowania jest używany w przypadku danych tabeli partycjonowanej lub podczas tworzenia indeksów w tabelach partycjonowanych, ale w rzeczywistości nie ma to miejsca. Sortowanie danych podzielonych na partycje wykorzystuje CQScanSortNew lub CQScanTopSortNew jak normalnie; sortowanie wierszy w celu wstawienia do indeksu partycjonowanego zazwyczaj używa CQScanIndexSortNew jak widać w sekcji 3.
CQScanPartitionSortNew klasa sort jest obecna tylko w SQL Server 2014. Jest używana tylko podczas sortowania wierszy według identyfikatora partycji, przed wstawieniem do partycjonowanego klastrowanego indeksu magazynu kolumn . Pamiętaj, że jest używany tylko do partycjonowania magazyn kolumn klastrowych; zwykłe (bez partycji) plany wstawiania magazynu kolumn w klastrach nie korzystają z sortowania.
Elementy wstawiane do partycjonowanego klastrowanego indeksu magazynu kolumn nie zawsze zawierają sortowanie. Jest to decyzja oparta na kosztach, która zależy od szacowanej liczby wierszy do wstawienia. Jeśli optymalizator oszacuje, że warto posortować wstawki według partycji w celu optymalizacji we/wy, operator wstawiania magazynu kolumn będzie miał DMLRequestSort właściwość ustawiona na true i CQScanPartitionSortNew sort może pojawić się w planie wykonania.
Demo w tej sekcji wykorzystuje stałą tabelę numerów sekwencyjnych. Jeśli nie masz takiego, możesz go utworzyć za pomocą następującego skryptu:
-- Itzik Ben-Gan's row generator
WITH
L0 AS (SELECT 1 AS c UNION ALL SELECT 1),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM L5)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM Nums AS N
WHERE N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Samo demonstracja obejmuje utworzenie podzielonej na partycje klastrowej tabeli indeksowanej magazynu kolumn i wstawienie wystarczającej liczby wierszy (z powyższej tabeli Numbers), aby przekonać optymalizator do użycia sortowania partycji przed wstawieniem:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES (1000, 2000, 3000);
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
-- A partitioned heap
CREATE TABLE dbo.Partitioned
(
col1 integer NOT NULL,
col2 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID())),
col3 integer NOT NULL DEFAULT ABS(CHECKSUM(NEWID()))
)
ON PS (col1);
GO
-- Convert heap to partitioned clustered columnstore
CREATE CLUSTERED COLUMNSTORE INDEX ccsi
ON dbo.Partitioned
ON PS (col1);
GO
-- Add rows to the partitioned clustered columnstore table
INSERT dbo.Partitioned (col1)
SELECT N.n
FROM dbo.Numbers AS N
WHERE N.n BETWEEN 1 AND 4000; Plan wykonania wstawiania pokazuje sortowanie używane do zapewnienia, że wiersze docierają do klastrowanego iteratora wstawiania magazynu kolumn w kolejności identyfikatora partycji:

Stos wywołań przechwycony podczas CQScanPartitionSortNew sortowanie w toku jest pokazane poniżej:
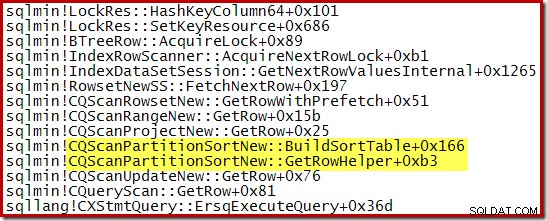
Jest jeszcze coś ciekawego w tej klasie. Sortowanie zwykle zużywają całe dane wejściowe w wywołaniu metody Open. Po posortowaniu zwracają kontrolę swojemu operatorowi nadrzędnemu. Później sortowanie zaczyna generować posortowane wiersze wyjściowe pojedynczo w zwykły sposób za pomocą wywołań GetRow. CQScanPartitionSortNew jest inny, jak widać na powyższym stosie wywołań:nie zużywa danych wejściowych podczas swojej metody Open – czeka, aż GetRow zostanie wywołany przez swojego rodzica po raz pierwszy.
Nie każde sortowanie identyfikatora partycji, które pojawia się w planie wykonania wstawiając wiersze do indeksu magazynu kolumn podzielonego na partycje klastrowane, będzie CQScanPartitionSortNew sortować. Jeśli sortowanie pojawia się bezpośrednio po prawej stronie operatora wstawiania indeksu magazynu kolumn, istnieje duże prawdopodobieństwo, że jest to CQScanPartitionSortNew sortuj.
Na koniec CQScanPartitionSortNew jest jedną z dwóch klas sortowania, które ustawiają właściwość miękkiego sortowania ujawnianą, gdy właściwości planu wykonania operatora sortowania są generowane z włączoną nieudokumentowaną flagą śledzenia 8666:
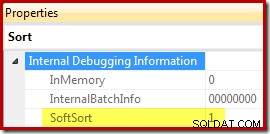
Znaczenie „miękkiego sortu” w tym kontekście jest niejasne. Jest on śledzony jako właściwość w strukturze optymalizatora zapytań i prawdopodobnie jest powiązany ze zoptymalizowanymi wstawkami danych partycjonowanych, ale dokładne określenie, co to oznacza, wymaga dalszych badań. W międzyczasie ta właściwość może służyć do wnioskowania, że sortowanie jest zaimplementowane z CQScanPartitionSortNew bez dołączania debuggera. Znaczenie flagi właściwości InMemory pokazanej powyżej zostanie omówione w części 2. Nie wskaż, czy w pamięci wykonano zwykłe sortowanie, czy nie.
Podsumowanie części pierwszej
- CQScanSortNew jest ogólną klasą sortowania używaną, gdy żadna inna opcja nie ma zastosowania. Wygląda na to, że wykorzystuje różne wewnętrzne sortowanie przez scalanie w pamięci, przechodząc do zewnętrznego sortowania przez scalanie za pomocą tempdb jeśli przyznana przestrzeń robocza pamięci okaże się niewystarczająca. Ta klasa może być używana do sortowania ogólnego i odrębnego.
- CQScanTopSortNowy wdraża Top N Sort. Gdzie N <=100, wykonywane jest wewnętrzne sortowanie przez scalanie w pamięci i nigdy nie rozlewa się do tempdb . Podczas sortowania w pamięci zachowywanych jest tylko n bieżących pierwszych elementów. Dla N> 100 CQScanTopSortNew jest odpowiednikiem CQScanSortNew sortowanie, które automatycznie zatrzymuje się po wyprowadzeniu N wierszy. Posortowanie N> 100 może się rozlać do tempdb jeśli to konieczne.
- Sortowanie Top N widoczne w planach wykonania to przepisanie po optymalizacji po zapytaniu. Jeśli optymalizator zapytań utworzy drzewo wyjściowe z sąsiednim sortowaniem Top N i nierozdzielnym, to przepisanie może zwinąć dwa operatory fizyczne w jeden operator sortowania Top N.
- CQScanIndexSortNew jest używany tylko w planach budowy indeksu DDL. Jest to jedyna standardowa klasa sortowania, która może dynamicznie pobierać więcej pamięci podczas wykonywania. Sortowanie budowania indeksu może nadal w pewnych okolicznościach rozlać się na dysk, w tym gdy SQL Server zdecyduje, że żądany wzrost pamięci nie jest zgodny z bieżącym obciążeniem.
- CQScanPartitionSortNew jest obecny tylko w programie SQL Server 2014 i służy tylko do optymalizacji wstawiania do indeksu magazynu kolumn podzielonego na partycje w klastrze. Zapewnia „miękkie sortowanie”.
Druga część tego artykułu dotyczy CQScanInMemSortNew , oraz dwa rodzaje procedur składowanych skompilowanych natywnie w pamięci OLTP.