Dostępność, dostępność i wydajność danych mają kluczowe znaczenie dla sukcesu biznesowego. Dostrajanie wydajności i optymalizacja zapytań SQL to trudne, ale niezbędne praktyki dla specjalistów od baz danych. Wymagają one przyjrzenia się różnym zbiorom danych przy użyciu rozszerzonych zdarzeń, perfmonów, planów wykonania, statystyk i indeksów, żeby wymienić tylko kilka. Czasami właściciele aplikacji proszą o zwiększenie zasobów systemowych (procesora i pamięci), aby poprawić wydajność systemu. Jednak te dodatkowe zasoby mogą nie być potrzebne i mogą wiązać się z nimi koszty. Czasami wszystko, co jest wymagane, to wprowadzenie drobnych ulepszeń w celu zmiany zachowania zapytań.
W tym artykule omówimy kilka najlepszych praktyk optymalizacji zapytań SQL, które należy zastosować podczas pisania zapytań SQL.
SELECT * vs SELECT lista kolumn
Zwykle programiści używają instrukcji SELECT * do odczytywania danych z tabeli. Odczytuje wszystkie dostępne dane kolumny w tabeli. Załóżmy, że tabela [AdventureWorks2019].[Zasoby ludzkie].[Pracownik] przechowuje dane 290 pracowników i musisz pobrać następujące informacje:
- Numer dowodu osobistego pracownika
- data urodzenia
- Płeć
- Data wynajmu
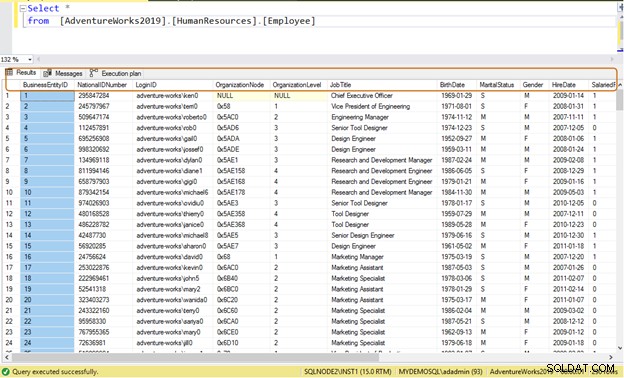
Nieefektywne zapytanie: Jeśli użyjesz instrukcji SELECT *, zwróci ona wszystkie dane z kolumny dla wszystkich 290 pracowników.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
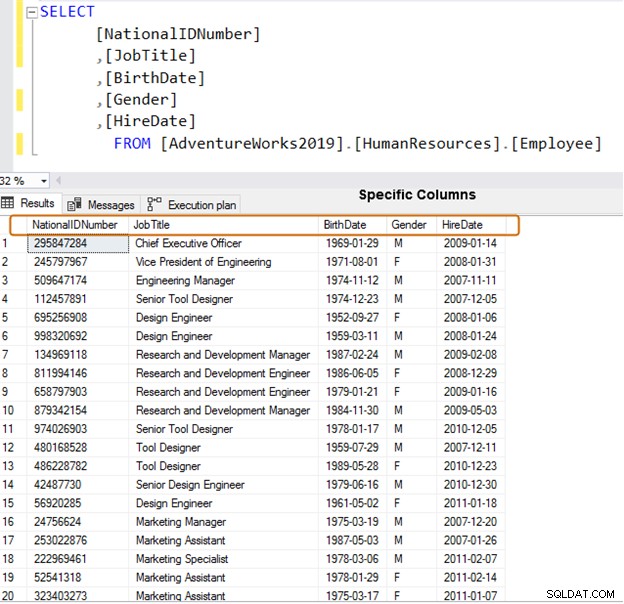
Zamiast tego użyj określonych nazw kolumn do pobierania danych.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
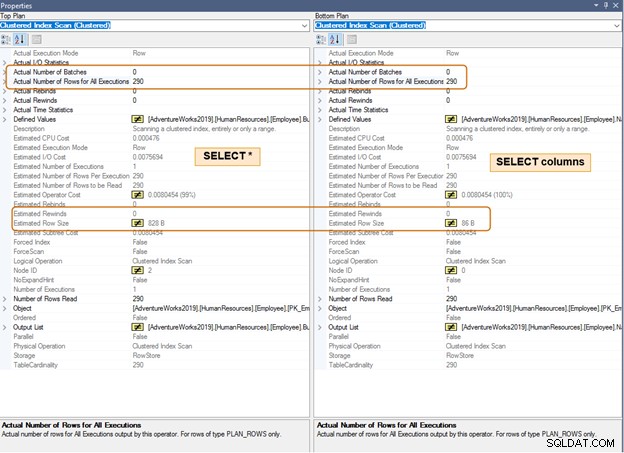
W poniższym planie wykonania zwróć uwagę na różnicę w szacowanym rozmiarze wiersza dla tej samej liczby wierszy. Zauważysz różnicę w CPU i IO dla dużej liczby wierszy.
Użycie COUNT() vs. ISTNIEJE
Załóżmy, że chcesz sprawdzić, czy w tabeli SQL istnieje określony rekord. Zwykle używamy COUNT (*) do sprawdzenia rekordu i zwraca liczbę rekordów w danych wyjściowych.
W tym celu możemy jednak użyć funkcji JEŻELI ISTNIEJE(). Dla porównania włączyłem statystyki przed wykonaniem zapytań.
Zapytanie o COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
Zapytanie o IF EXISTS()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
Użyłem statisticsparser do analizy wyników statystycznych obu zapytań. Spójrz na wyniki poniżej. Zapytanie z COUNT(*) ma 276 logicznych odczytów, podczas gdy IF EXISTS() ma 83 logicznych odczytów. Możesz nawet uzyskać bardziej znaczącą redukcję odczytów logicznych za pomocą funkcji IF EXISTS(). Dlatego powinieneś go używać do optymalizacji zapytań SQL w celu uzyskania lepszej wydajności.

Unikaj używania SQL DISTINCT
Ilekroć potrzebujemy unikalnych rekordów z zapytania, zwykle używamy klauzuli SQL DISTINCT. Załóżmy, że połączyłeś ze sobą dwie tabele i w wyniku zwraca zduplikowane wiersze. Szybkim rozwiązaniem jest określenie operatora DISTINCT, który pomija zduplikowany wiersz.
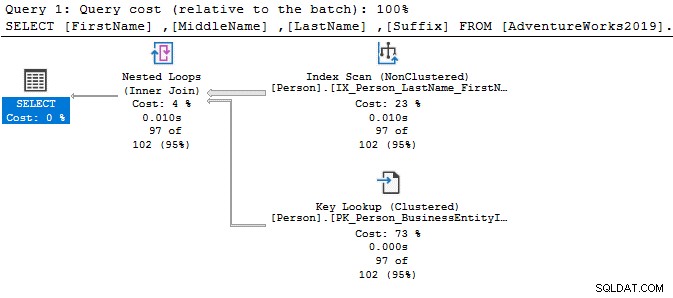
Spójrzmy na proste instrukcje SELECT i porównajmy plany wykonania. Jedyną różnicą między obydwoma zapytaniami jest operator DISTINCT.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
Z operatorem DISTINCT koszt zapytania wynosi 77%, podczas gdy wcześniejsze zapytanie (bez DISTINCT) ma tylko 23% kosztu partii.
Możesz użyć GROUP BY, CTE lub podzapytania do pisania wydajnego kodu SQL zamiast używania DISTINCT do uzyskiwania różnych wartości z zestawu wyników. Dodatkowo możesz pobrać dodatkowe kolumny dla odrębnego zestawu wyników.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Użycie symboli wieloznacznych w zapytaniu SQL
Załóżmy, że chcesz wyszukać określone rekordy zawierające nazwy zaczynające się od określonego ciągu. Deweloperzy używają symboli wieloznacznych do wyszukiwania pasujących rekordów.
W poniższym zapytaniu wyszukuje ciąg Ken w pierwszej kolumnie imienia. To zapytanie pobiera oczekiwane wyniki Ken dra i Ken nie. Ale zapewnia również nieoczekiwane wyniki, na przykład Macken zie i Nken ge.
W planie wykonania widzisz skanowanie indeksu i wyszukiwanie kluczy dla powyższego zapytania.
Możesz uniknąć nieoczekiwanego wyniku, używając symbolu wieloznacznego na końcu ciągu.
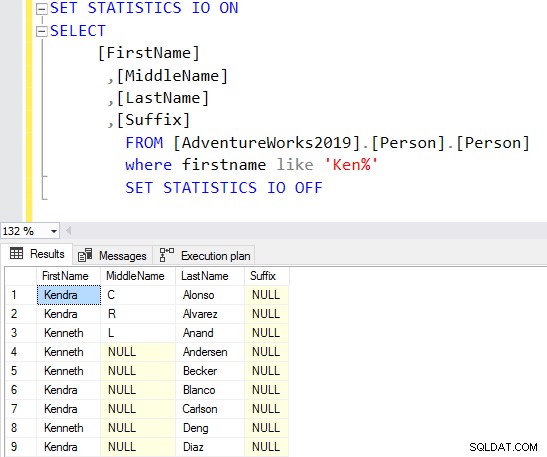
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Teraz otrzymujesz przefiltrowany wynik na podstawie Twoich wymagań.
Używając symbolu wieloznacznego na początku, optymalizator zapytań może nie być w stanie użyć odpowiedniego indeksu. Jak pokazano na poniższym zrzucie ekranu, z końcowym symbolem wieloznacznym, optymalizator zapytań sugeruje również brakujący indeks.
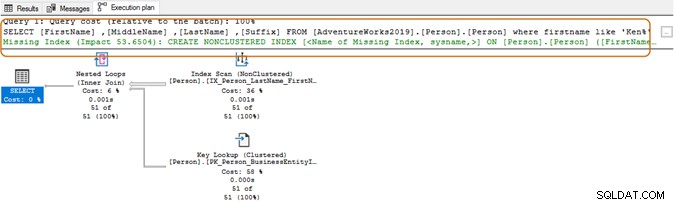
Tutaj będziesz chciał ocenić swoje wymagania dotyczące aplikacji. Należy starać się unikać używania znaku wieloznacznego w ciągach wyszukiwania, ponieważ może to zmusić optymalizator zapytań do użycia skanowania tabeli. Jeśli tabela jest ogromna, wymagałoby to większych zasobów systemowych dla operacji we/wy, procesora i pamięci i może powodować problemy z wydajnością dla zapytania SQL.
Stosowanie klauzul WHERE i HAVING
Klauzule WHERE i HAVING są używane jako filtry wierszy danych. Klauzula WHERE filtruje dane przed zastosowaniem logiki grupowania, podczas gdy klauzula HAVING filtruje wiersze po obliczeniach agregujących.
Na przykład w poniższym zapytaniu używamy filtra danych w klauzuli HAVING bez klauzuli WHERE.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
Poniższe zapytanie najpierw filtruje dane w klauzuli WHERE, a następnie używa klauzuli HAVING do filtrowania danych zbiorczych.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Zalecam stosowanie klauzuli WHERE do filtrowania danych i klauzuli HAVING do filtrowania danych zbiorczych jako najlepszej praktyki.
Użycie klauzul IN i EXISTS
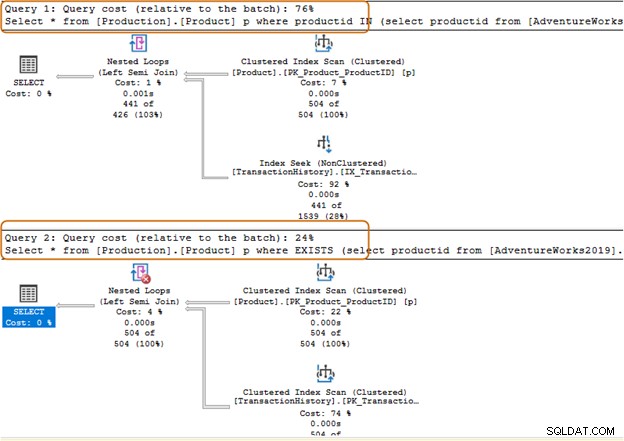
Należy unikać używania klauzuli IN-operator w zapytaniach SQL. Na przykład w poniższym zapytaniu najpierw znaleźliśmy identyfikator produktu z tabeli [Produkcja].[Historia transakcji]), a następnie wyszukaliśmy odpowiednie rekordy w tabeli [Produkcja].[Produkt].
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
W poniższym zapytaniu zastąpiliśmy klauzulę IN klauzulą EXISTS.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
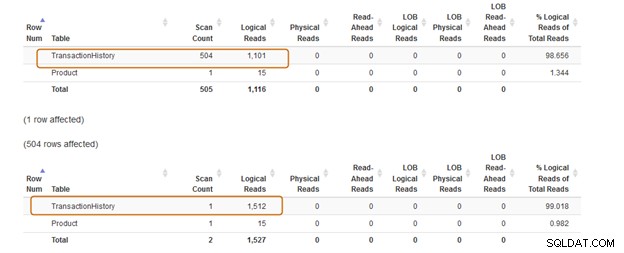
Porównajmy teraz statystyki po wykonaniu obu zapytań.
Klauzula IN używa 504 skanów, podczas gdy klauzula EXISTS używa 1 skanu dla tabeli [Produkcja].[Historia Transakcji]).
Partia zapytania klauzuli IN kosztuje 74%, podczas gdy koszt klauzuli EXISTS wynosi 24%. Dlatego powinieneś unikać klauzuli IN, zwłaszcza jeśli podzapytanie zwraca duży zestaw danych.
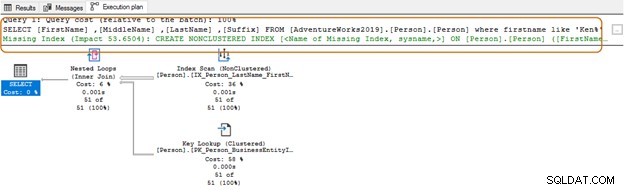
Brakujące indeksy
Czasami, gdy wykonujemy zapytanie SQL i szukamy rzeczywistego planu wykonania w SSMS, pojawia się sugestia dotycząca indeksu, który może ulepszyć Twoje zapytanie SQL.
Alternatywnie możesz użyć dynamicznych widoków zarządzania, aby sprawdzić szczegóły brakujących indeksów w Twoim środowisku.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Zwykle administratorzy baz danych postępują zgodnie z radami SSMS i tworzą indeksy. Na razie może to poprawić wydajność zapytań. Nie należy jednak tworzyć indeksu bezpośrednio na podstawie tych zaleceń. Może to wpłynąć na wydajność innych zapytań i spowolnić instrukcje INSERT i UPDATE.
- Najpierw przejrzyj istniejące indeksy dla swojej tabeli SQL.
- Uwaga, zarówno nadmierne, jak i niedostateczne indeksowanie są złe dla wydajności zapytań.
- Zastosuj brakujące zalecenia dotyczące indeksów z największym wpływem po przejrzeniu istniejących indeksów i zaimplementuj je w niższym środowisku. Jeśli Twoje obciążenie działa dobrze po zaimplementowaniu nowego brakującego indeksu, warto dodać it.
Proponuję zapoznać się z tym artykułem, aby uzyskać szczegółowe informacje na temat najlepszych praktyk w zakresie indeksowania:11 najlepszych praktyk dotyczących indeksowania SQL Server w celu poprawy wydajności.
Wskazówki dotyczące zapytań
Programiści określają wskazówki dotyczące zapytań wprost w swoich instrukcjach t-SQL. Te wskazówki dotyczące zapytań zastępują zachowanie optymalizatora zapytań i zmuszają go do przygotowania planu wykonania na podstawie wskazówki dotyczącej zapytania. Często używane wskazówki dotyczące zapytań to NOLOCK, Optimize For and Recompile Merge/Hash/Loop. Są to krótkoterminowe poprawki dla twoich zapytań. Jednak powinieneś popracować nad analizą zapytania, indeksów, statystyk i planu wykonania, aby uzyskać trwałe rozwiązanie.
Zgodnie z najlepszymi praktykami należy zminimalizować użycie wszelkich wskazówek dotyczących zapytania. Chcesz korzystać ze wskazówek zapytania w zapytaniu SQL po uprzednim zrozumieniu jego konsekwencji i nie używać ich niepotrzebnie.
Przypomnienia dotyczące optymalizacji zapytań SQL
Jak już wspomnieliśmy, optymalizacja zapytań SQL to otwarta droga. Możesz zastosować najlepsze praktyki i drobne poprawki, które mogą znacznie poprawić wydajność. Rozważ następujące wskazówki dotyczące lepszego tworzenia zapytań:
- Zawsze patrz na alokację zasobów systemowych (dysków, procesora, pamięci)
- Przejrzyj swoje flagi śledzenia uruchamiania, indeksy i zadania konserwacji bazy danych
- Analizuj swoje obciążenie pracą za pomocą rozszerzonych zdarzeń, profilera lub narzędzi do monitorowania baz danych innych firm
- Zawsze wdrażaj dowolne rozwiązanie (nawet jeśli masz 100% pewności) najpierw w środowisku testowym i analizuj jego wpływ; gdy będziesz zadowolony, zaplanuj wdrożenia produkcyjne