Przypuszczam, że powodem jest to, że po prostu nie uznali tej funkcji za priorytetową, którą warto wdrożyć. Wygląda na to, że Postgres robi wspierać oba
UNION i UNION ALL .
Jeśli masz mocne argumenty za tą funkcją, możesz przekazać opinię na stronie Połącz (lub jakikolwiek będzie adres URL jego zamiennika).
Zapobieganie dodawaniu duplikatów może być przydatne, ponieważ zduplikowany wiersz dodany w późniejszym kroku do poprzedniego prawie zawsze spowoduje nieskończoną pętlę lub przekroczenie maksymalnego limitu rekurencji.
Istnieje kilka miejsc w Standardach SQL
gdzie używany jest kod demonstrujący UNION takie jak poniżej
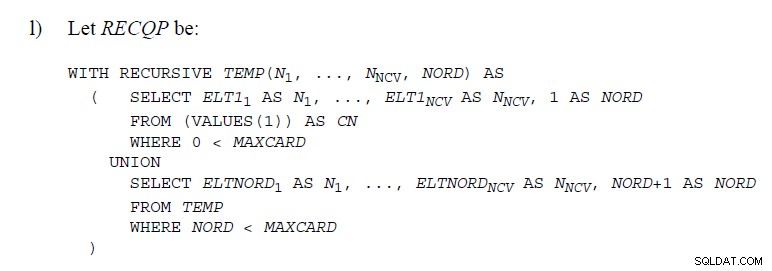
W tym artykule wyjaśniono, jak są implementowane w SQL Server . Nie robią nic takiego „pod maską”. Bufor stosu usuwa wiersze w miarę upływu czasu, więc nie byłoby możliwe sprawdzenie, czy późniejszy wiersz jest duplikatem usuniętego. Obsługa UNION wymagałoby nieco innego podejścia.
W międzyczasie możesz całkiem łatwo osiągnąć to samo w wielowyrazowym TVF.
Weźmy głupi przykład poniżej (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Zmiana UNION do UNION ALL i dodanie DISTINCT na końcu nie uratuje cię przed nieskończoną rekurencją.
Ale możesz to zaimplementować jako
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Powyższe używa IGNORE_DUP_KEY aby odrzucić duplikaty. Jeśli lista kolumn jest zbyt szeroka, aby można ją było zindeksować, potrzebujesz DISTINCT i NOT EXISTS zamiast. Prawdopodobnie chciałbyś również ustawić parametr, aby ustawić maksymalną liczbę rekurencji i uniknąć nieskończonych pętli.