Możesz rozwiązać ten problem bez sprzężenia, co oznacza, że powinien mieć lepszą wydajność. Chodzi o to, aby pogrupować dane według identyfikatora object_id, licząc numer wiersza każdego identyfikatora object_id. To właśnie robi "partycjonowanie przez". Następnie możesz zaktualizować, gdzie row_num jest> 1. Spowoduje to aktualizację wszystkich zduplikowanych identyfikatorów_obiektów z wyjątkiem pierwszego!
update t set t.status_val = 'some_status'
from (
select *, row_number() over(partition by object_id order by (select null)) row_num
from foo
) t
where row_num > 1
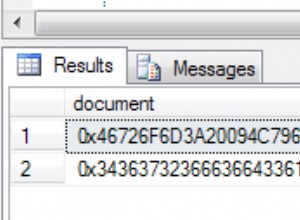
Na stole testowym 82944 rekordów wydajność była taka (Twój przebieg może się różnić!):Tabela „test”. Liczba skanów 5, odczyty logiczne 82283, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0. Czas procesora =141 ms, czas, który upłynął =150 ms.
Z pewnością możemy również rozwiązać ten problem za pomocą sprzężenia wewnętrznego, jednak generalnie powinno to prowadzić do większej liczby logicznych odczytów i większego procesora:
Tabela „test”. Liczba skanów 10, odczyty logiczne 83622, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lob 0, odczyty fizyczne lob 0, odczyty z wyprzedzeniem lob 0. Tabela „Plik roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne LOB 0, odczyty fizyczne LOB 0, odczyty z wyprzedzeniem LOB 0. Tabela „Tabela robocza”. Liczba skanów 4, odczyty logiczne 167426, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0. Czas procesora =342 ms, czas, który upłynął =233 ms.
Aby przeglądać wyniki i aktualizować je w mniejszych partiach:
declare @rowcount int = 1;
declare @batch_size int = 1000;
while @rowcount > 0
begin
update top(@batch_size) t set t.status_val = 'already updated'
from (
select *, row_number() over(partition by object_id order by (select null)) row_num
from foo
where status_val <> 'already updated'
) t
where row_num > 1
set @rowcount = @@rowcount;
end
Pomoże to utrzymać blokowanie, jeśli inne współbieżne sesje próbują uzyskać dostęp do tej tabeli.