Mam nadzieję, że dobrze to zrozumiałem. Więc powtórzę.
- Masz 1 tabelę z dużą ilością wpisów
- Masz tę listę z programu Excel, w której szukasz „kolumny wyszukiwania”
- W przypadku dopasowania, zamień całą wartość na „zamień kolumnę”
W takim przypadku może to być rozwiązanie:
declare @data table (Column1 nvarchar(50))
insert into @data
(Column1)
values (N'RbC investment for Seniors 65+'),
(N'RBC inv for juniors')
declare @replace table
(
OriginalValue nvarchar(50),
NewValue nvarchar(50),
[priority] int
)
insert into @replace
(OriginalValue, NewValue, [priority])
values (N'rbc inv', N'RBC dominion securities', 2),
(N'rbc dom', N'RBC dominion securities', 2),
(N'RBC', N'RBC Bank', 3)
update @data
set Column1 = coalesce((
select top 1
NewValue
from @replace
where Column1 like '%' + OriginalValue + '%'
order by [priority]
), Column1)
select *
from @data
Tabela „dane” będzie tą, w której dokonujesz zamiany.
Użycie tego może powodować pewne efekty uboczne (np. symbole wieloznaczne, takie jak % w „kolumnie_wyszukiwania”, może wiele dopasowań – w tej chwili bierze się „losowy”, wydajność może nie być najlepsza, ...) Ale myślę, że dla bardziej precyzyjna odpowiedź, potrzebuję lepszego pytania.
Edytuj:
Dzięki Ralphowi... dodałem priorytet do tabeli "zamień", aby móc obsłużyć zduplikowane mecze.
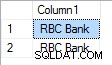
W przypadku, gdy „RBC” ma priorytet 3, wynik jest następujący:
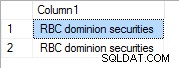
Przy priorytecie 1 jest to: