Koszty poddrzewa należy traktować z dużym przymrużeniem oka (a zwłaszcza wtedy, gdy masz ogromne błędy kardynalne). SET STATISTICS IO ON; SET STATISTICS TIME ON; wynik jest lepszym wskaźnikiem rzeczywistej wydajności.
Sortowanie wierszy zerowych nie zajmuje 87% zasobów. Ten problem w Twoim planie polega na szacowaniu statystyk. Koszty wykazane w rzeczywistym planie są nadal kosztami szacunkowymi. Nie dostosowuje ich do tego, co faktycznie się wydarzyło.
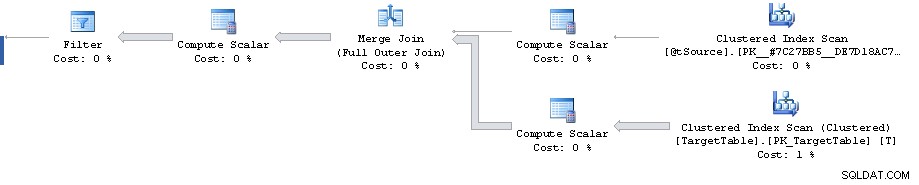
W planie jest punkt, w którym filtr redukuje 1 911 721 wierszy do 0, ale szacowane wiersze w przyszłości to 1 860 310. Następnie wszystkie koszty są fałszywe, a ich punkt kulminacyjny wynosi 87%, szacowany na 3 348 560 rzędów sortowania.
Błąd oszacowania kardynalności można odtworzyć poza Merge oświadczenie, patrząc na szacunkowy plan dla Full Outer Join z równoważnymi predykatami (daje to samo oszacowanie 1 860 310 wierszy).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
To powiedziawszy, jednak plan aż do samego filtra wygląda dość nieoptymalnie. Wykonuje pełne skanowanie indeksu klastrowego, gdy być może potrzebujesz planu z 2 szukaniami klastrowanego zakresu indeksu. Jeden do pobrania pojedynczego wiersza dopasowanego przez klucz podstawowy z połączenia w źródle, a drugi do pobrania T.Key1 = @id zakres (choć może ma to na celu uniknięcie konieczności późniejszego sortowania według kolejności kluczy klastrowych?)
Być może mógłbyś spróbować tego przepisać i sprawdzić, czy działa lepiej lub gorzej
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;



