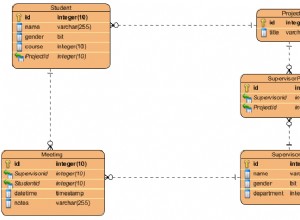
Idealnym indeksem dla tego zapytania byłyby kolumny kluczowe uidNode , dtCreated i uwzględnione kolumny wszystkie pozostałe kolumny w tabeli, aby indeks pokrywał podczas zwracania r.* . Jeśli zapytanie generalnie zwróci tylko stosunkowo małą liczbę wierszy (co wydaje się prawdopodobne ze względu na WHERE r.ix = 1 filtr) może nie być opłacalne tworzenie indeksu obejmującego, ponieważ koszt kluczowych wyszukiwań może nie przewyższać negatywnych skutków dużego indeksu na wyciągi CUD.