Jeśli dobrze zrozumiałem, chcesz policzyć odrębny wpis dla określonego statusu w twoim okresie... jeśli tak, powinieneś użyć DISTINCT klauzula w twoim count() zmiana z count(*) na count(distinct Entry_id)
with c (Status_Id, Entry_Id, Start_Date) AS (
select Status_Id, Entry_Id, Start_Date from tbl where
(End_Date BETWEEN '19000101' AND '21000101')
AND ((Start_Date BETWEEN '19000101' AND '21000101')
OR End_Date <= '21000101'))
select Status_Id, count(distinct Entry_Id) as cnt from
(select Entry_Id, max(start_date) as start_date from c
group by Entry_Id) d inner join
c on c.Entry_Id = d.Entry_Id
and c.start_date = d.start_date
GROUP BY Status_Id WITH ROLLUP
EDYTUJ
Tak długo, jak nie obchodzi Cię, który status jest zwracany dla danego wpisu, myślę, że możesz zmodyfikować wewnętrzne zapytanie, aby zwrócić pierwszy status i dołączyć również do statusu
with c (Status_Id, Entry_Id, Start_Date) AS (
select Status_Id, Entry_Id, Start_Date from tbl where
(End_Date BETWEEN '19000101' AND '21000101')
AND ((Start_Date BETWEEN '19000101' AND '21000101')
OR End_Date <= '21000101'))
select c.Status_Id, count(c.Entry_Id) as cnt from
(select Entry_Id, Start_Date, (select top 1 Status_id from c where Entry_Id = CC.Entry_Id and Start_Date = CC.Start_Date) as Status_Id
from (select Entry_Id, max(start_date) as start_date from c
group by Entry_Id) as CC) d inner join
c on c.Entry_Id = d.Entry_Id
and c.start_date = d.start_date
and c.status_id = d.status_id
GROUP BY c.Status_Id
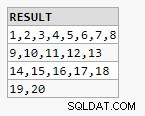
Wynik
Status_id Count
489 2
492 1
495 1