Podsumowanie:
Każde zapytanie wykonałem 10 razy, używając poniższego zestawu danych testowych.
- Bardzo duży zestaw wyników podzapytania (100000 wierszy)
- Zduplikowane wiersze
- Zerowe wiersze
We wszystkich powyższych scenariuszach zarówno IN i EXISTS wykonywane w identyczny sposób.
Kilka informacji o bazy danych Performance V3 używane do testowania.20000 klientów posiadających 1000000 zamówień, więc każdy klient jest losowo duplikowany (w zakresie od 10 do 100) w tabeli zamówień.
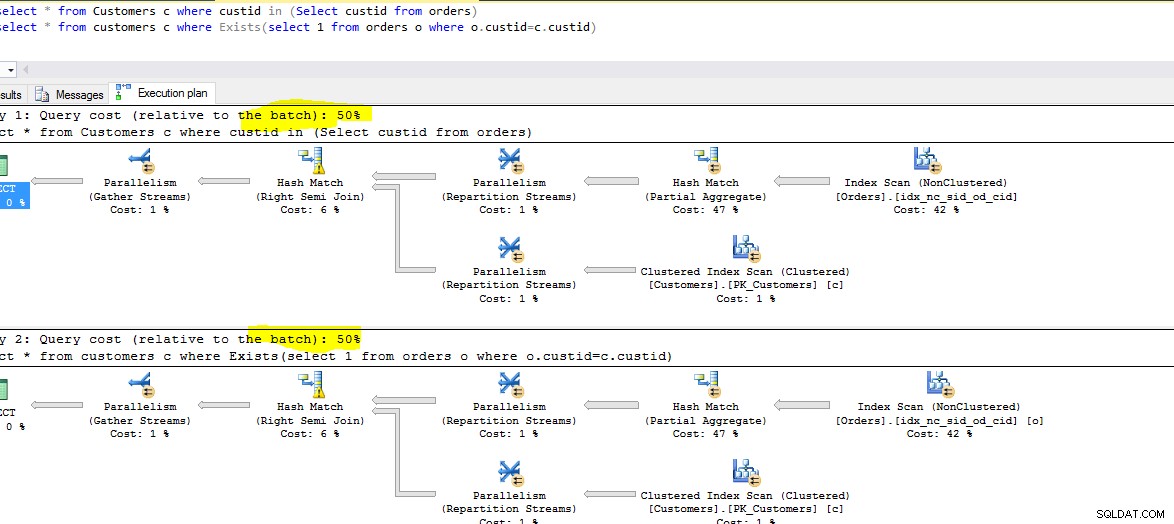
Koszt wykonania,Czas:
Poniżej znajduje się zrzut ekranu obu uruchomionych zapytań. Obserwuj względny koszt każdego zapytania.
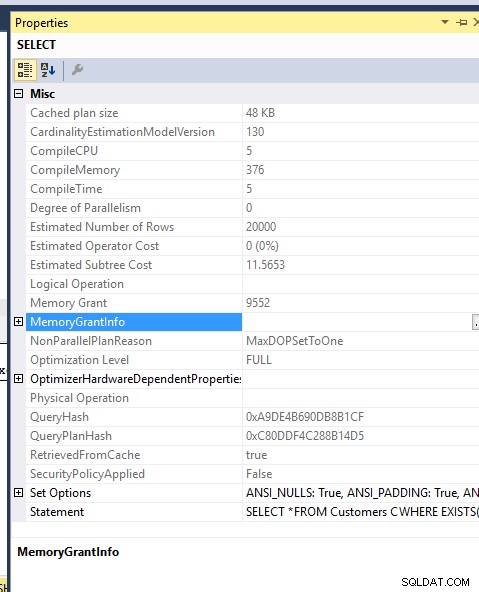
Koszt pamięci:
Przydział pamięci dla dwóch zapytań jest również taki sam... Wymusiłem MDOP 1, aby nie rozlać ich do TEMPDB..
Czas procesora, odczyty:
W przypadku istnienia:
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 469 ms, elapsed time = 595 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
Dla IN:
(20000 row(s) affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 1, logical reads 109, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 1, logical reads 3855, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 547 ms, elapsed time = 669 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
W każdym przypadku optymalizator jest wystarczająco inteligentny, aby zmienić kolejność zapytań.
Zwykle używam EXISTS tylko chociaż (moja opinia). Jeden przypadek użycia do użycia EXISTS jest wtedy, gdy nie chcesz zwracać zestawu wyników drugiej tabeli.
Aktualizuj zgodnie z zapytaniami Martina Smitha:
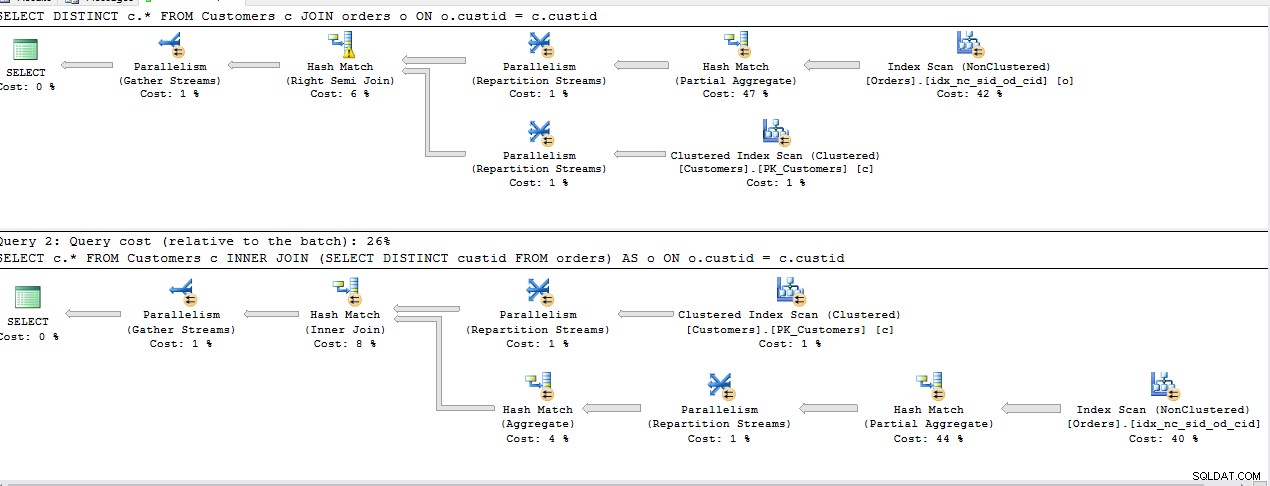
Uruchomiłem poniższe zapytania, aby znaleźć najbardziej efektywny sposób na pobranie wierszy z pierwszej tabeli, do której odwołanie istnieje w drugiej tabeli.
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
SELECT *
FROM Customers C
WHERE EXISTS(SELECT 1 FROM Orders o WHERE o.custid = c.custid)
SELECT *
FROM Customers c
WHERE custid IN (SELECT custid FROM Orders)
Wszystkie powyższe zapytania mają ten sam koszt, z wyjątkiem drugiego INNER JOIN , Plan jest taki sam dla reszty.
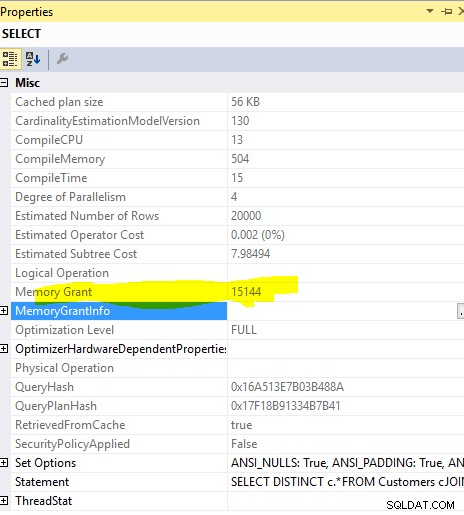
Przyznanie pamięci:
To zapytanie
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
wymagane przyznanie pamięci
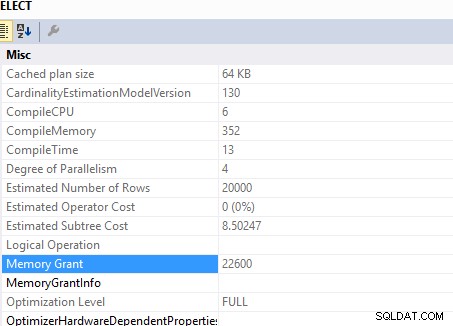
To zapytanie
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
wymagane przyznanie pamięci ..
Czas procesora, odczyty:
W przypadku zapytania:
SELECT DISTINCT c.*
FROM Customers c
JOIN Orders o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 48, logical reads 1344, physical reads 96, read-ahead reads 1248, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1453 ms, elapsed time = 781 ms.
Dla zapytania:
SELECT c.*
FROM Customers c
INNER JOIN (SELECT DISTINCT custid FROM Orders) AS o ON o.custid = c.custid
(20000 row(s) affected)
Table 'Customers'. Scan count 5, logical reads 322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Orders'. Scan count 5, logical reads 3929, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1499 ms, elapsed time = 403 ms.