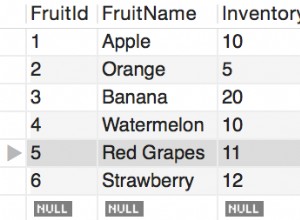
Po pierwsze, mamy praktyczne powodów. Klucze obce są utrzymywane i sprawdzane za pomocą indeksów. Aby indeks był użyteczny, musimy znać (poszukiwane) wartości wszystkich kolumn w indeksie. Jeśli mamy indeks/pk na (a,b) i mamy wartość klucza obcego (NULL,1) , nie możemy szukać w indeksie w celu określenia, czy istnieje wiersz z b wartość 1. To spowodowałoby, że klucz obcy byłby "drogi" w utrzymaniu.
Ale po drugie, musimy wziąć pod uwagę spójność. W przypadku pojedynczej kolumny jest to dość niekontrowersyjne — jeśli masz wartość w kolumnie FK, musi istnieć pasująca wartość w kolumnie, do której istnieje odwołanie. W przeciwnym razie, jeśli kolumna FK ma wartość NULL wtedy ograniczenie nie jest zaznaczone.
Ale jak rozszerzyć to na wiele kolumn? Co to powyższa reguła? Nie ma singla oczywista interpretacja, ale zamiast niej wiele. Czy powyższa reguła to „jeśli wszystkie kolumny nie są NULL, wtedy ograniczenie jest sprawdzane” lub „jeśli jakiekolwiek kolumny nie są NULL, wtedy ograniczenie jest sprawdzane? Te reguły są identyczne, gdy brana jest pod uwagę tylko jedna kolumna.
Spodziewałeś się, że reguła będzie druga, podczas gdy w rzeczywistości jest pierwszą. Jest to wyraźnie udokumentowane :