W poprzednim blogu ogłosiliśmy nową funkcję ClusterControl 1.7.4 o nazwie Cluster-to-Cluster Replication. Automatyzuje cały proces konfigurowania klastra DR poza klastrem podstawowym, z replikacją pomiędzy nimi. Aby uzyskać bardziej szczegółowe informacje, zapoznaj się z wyżej wspomnianym wpisem na blogu.
Teraz w tym blogu przyjrzymy się, jak skonfigurować tę nową funkcję dla istniejącego klastra. W tym zadaniu założymy, że masz zainstalowany ClusterControl, a Master Cluster został wdrożony przy jego użyciu.
Wymagania dla Master Cluster
Istnieją pewne wymagania, aby Master Cluster działał:
- Percona XtraDB Cluster w wersji 5.6.x i nowszej lub MariaDB Galera Cluster w wersji 10.x i nowszej.
- GTID włączone.
- Logowanie binarne włączone w co najmniej jednym węźle bazy danych.
- Poświadczenia kopii zapasowej muszą być takie same w klastrze głównym i klastrze podrzędnym.
Przygotowywanie głównego klastra
Główny klaster musi być przygotowany do korzystania z tej nowej funkcji. Wymaga konfiguracji zarówno po stronie ClusterControl, jak i bazy danych.
Konfiguracja ClusterControl
W węźle bazy danych sprawdź kopię zapasową poświadczeń użytkownika przechowywaną w /etc/my.cnf.d/secrets-backup.cnf (dla systemu operacyjnego RedHat) lub w /etc/mysql/secrets-backup .cnf (dla systemu operacyjnego opartego na Debianie).
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElW węźle ClusterControl edytuj plik konfiguracyjny /etc/cmon.d/cmon_ID.cnf (gdzie ID to numer ID klastra) i upewnij się, że zawiera on te same poświadczenia przechowywane w kopii zapasowej obiektów tajnych. por.
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...Każda zmiana w tym pliku wymaga ponownego uruchomienia usługi cmon:
$ service cmon restartSprawdź parametry replikacji bazy danych, aby upewnić się, że masz włączone GTID i rejestrowanie binarne.
Konfiguracja bazy danych
W węźle bazy danych sprawdź plik /etc/my.cnf (dla systemu operacyjnego opartego na RedHat) lub /etc/mysql/my.cnf (dla systemu operacyjnego opartego na Debianie), aby zobaczyć konfigurację związaną z proces replikacji.
Percona XtraDB:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7Klaster MariaDB Galera:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7Zacząłem sprawdzać pliki konfiguracyjne, możesz sprawdzić, czy jest włączony w interfejsie użytkownika ClusterControl. Przejdź do ClusterControl -> Wybierz Cluster -> Węzły. Powinieneś mieć coś takiego:

Dodana rola „Master” w pierwszym węźle oznacza, że logowanie binarne jest włączony.
Włączanie rejestrowania binarnego
Jeśli nie masz włączonego rejestrowania binarnego, przejdź do ClusterControl -> Wybierz Cluster -> Węzły -> Akcje węzłów -> Włącz rejestrowanie binarne.
Następnie musisz określić przechowywanie dziennika binarnego i ścieżkę do przechowywania to. Powinieneś również określić, czy chcesz, aby ClusterControl zrestartował węzeł bazy danych po jego skonfigurowaniu, czy wolisz go zrestartować samodzielnie.
Pamiętaj, że włączenie rejestrowania binarnego zawsze wymaga ponownego uruchomienia usługi bazy danych .
Tworzenie klastra Slave z GUI ClusterControl
Aby utworzyć nowy klaster Slave, przejdź do ClusterControl -> Wybierz Cluster -> Cluster Actions -> Create Slave Cluster.
Klaster Slave można utworzyć poprzez strumieniowe przesyłanie danych z bieżącego klastra głównego lub przy użyciu istniejącej kopii zapasowej.
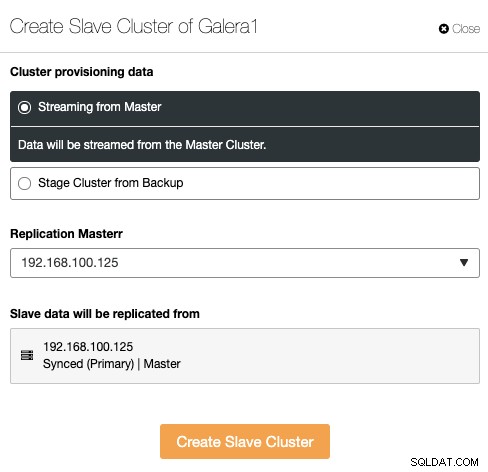
W tej sekcji musisz również wybrać węzeł główny bieżącego klastra z którego dane będą replikowane.
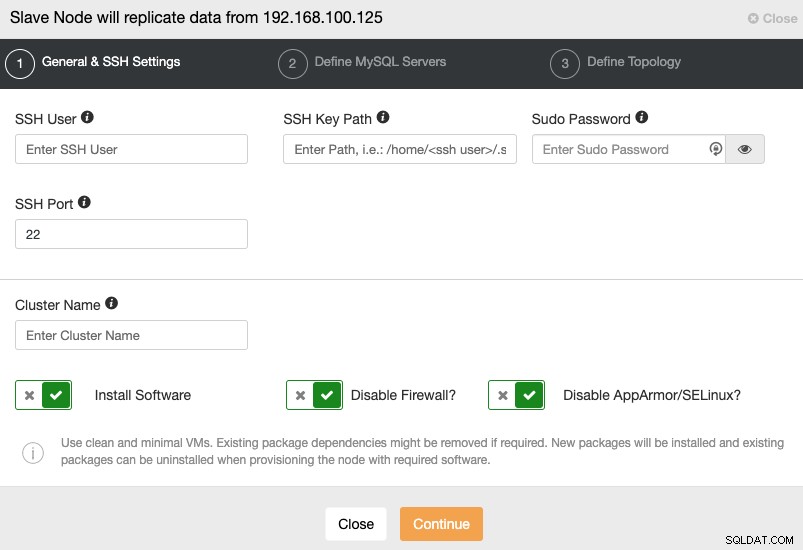
Gdy przejdziesz do następnego kroku, musisz określić Użytkownika, Klucz lub Hasło i port do łączenia się przez SSH z Twoimi serwerami. Potrzebujesz również nazwy dla swojego klastra Slave i jeśli chcesz, aby ClusterControl zainstalował dla Ciebie odpowiednie oprogramowanie i konfiguracje.
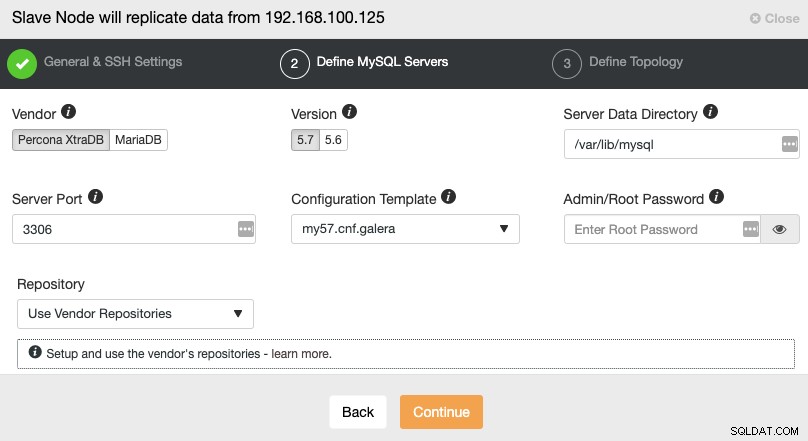
Po skonfigurowaniu informacji o dostępie SSH należy zdefiniować dostawcę bazy danych i wersja, katalog danych, port bazy danych i hasło administratora. Upewnij się, że używasz tego samego dostawcy/wersji i poświadczeń, które są używane przez klaster główny. Możesz także określić, którego repozytorium chcesz użyć.
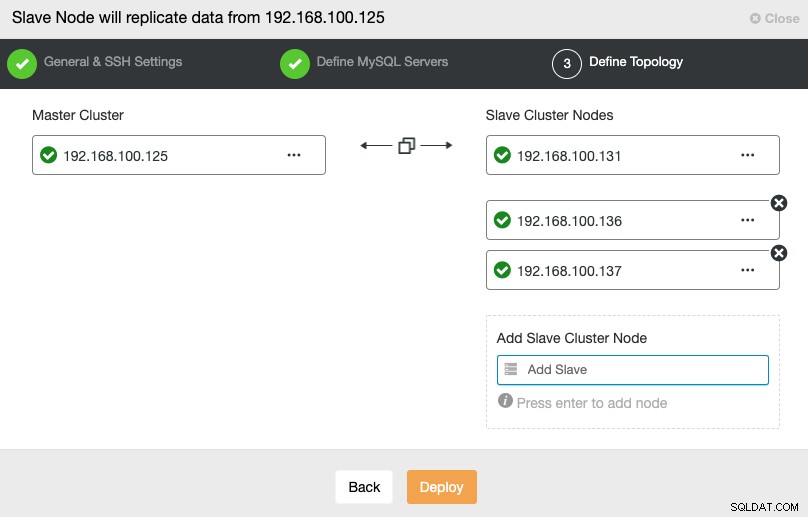
W tym kroku musisz dodać serwery do nowego klastra Slave. W tym zadaniu możesz wprowadzić adres IP lub nazwę hosta każdego węzła bazy danych.
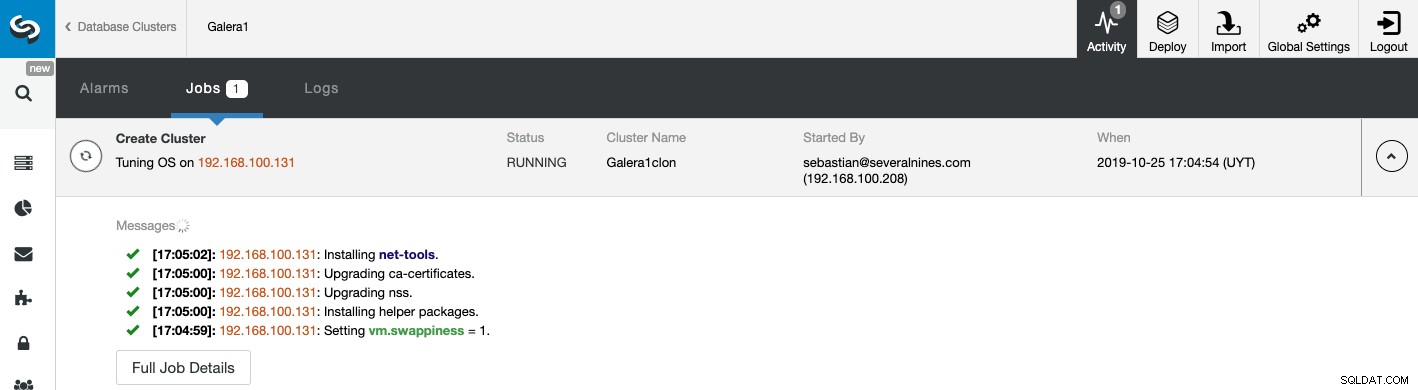
Możesz monitorować stan tworzenia nowego klastra Slave z poziomu Monitor aktywności ClusterControl. Po zakończeniu zadania możesz zobaczyć klaster na głównym ekranie ClusterControl.
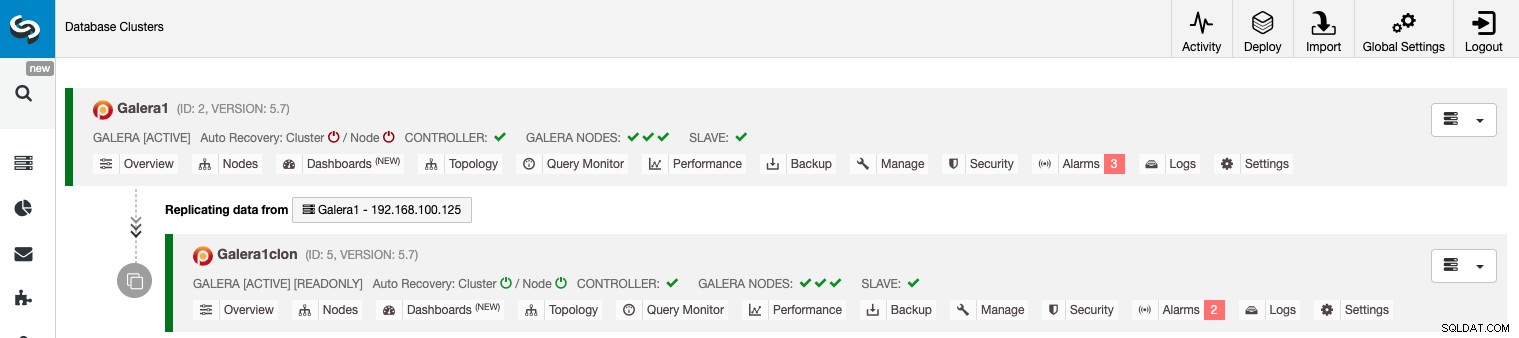
Zarządzanie replikacją między klastrami za pomocą interfejsu GUI ClusterControl
Teraz masz już uruchomioną replikację klastrów do klastrów, możesz wykonać różne czynności w tej topologii za pomocą ClusterControl.
Konfiguruj klastry aktywny-aktywny
Jak widać, domyślnie klaster Slave jest ustawiony w trybie tylko do odczytu. Możliwe jest wyłączenie flagi tylko do odczytu na węzłach jeden po drugim w interfejsie użytkownika ClusterControl, ale należy pamiętać, że klastrowanie Active-Active jest zalecane tylko wtedy, gdy aplikacje dotykają tylko rozłącznych zestawów danych w jednym z klastrów, ponieważ MySQL/MariaDB tego nie robi. oferować dowolne wykrywanie lub rozwiązywanie konfliktów.
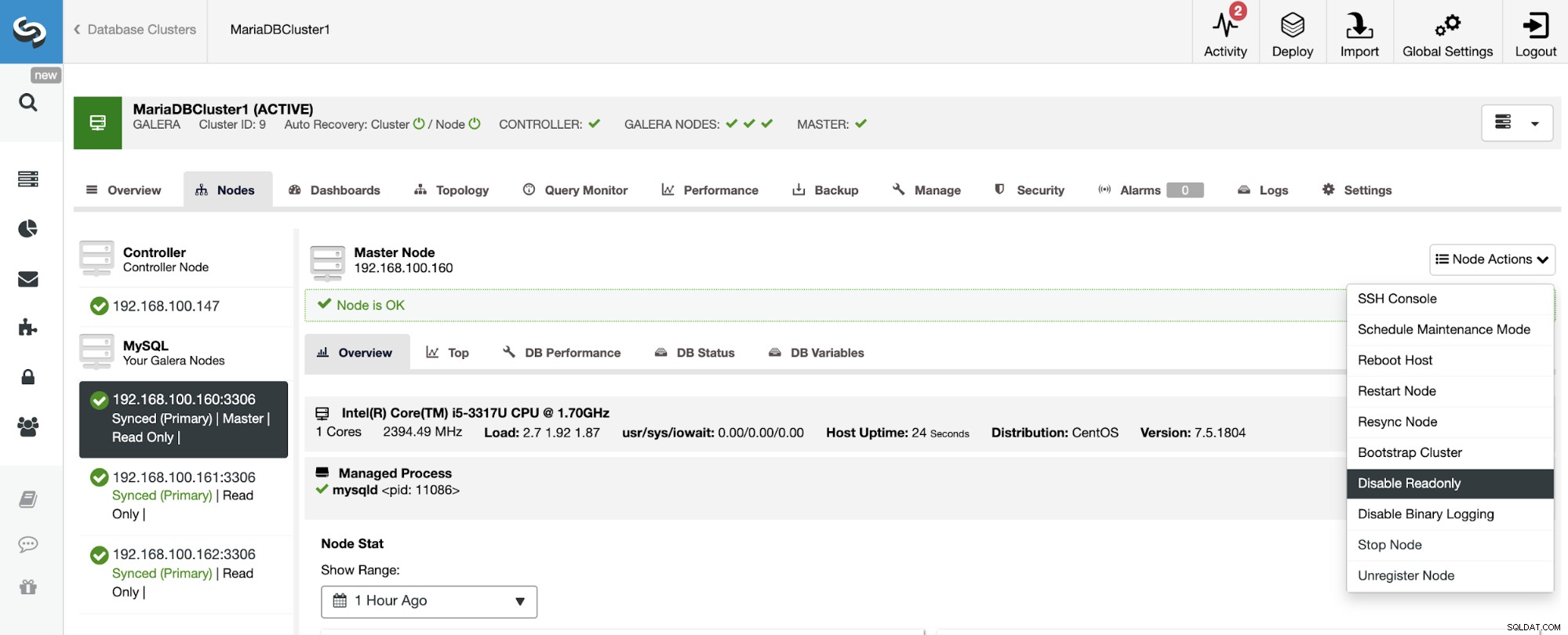
Aby wyłączyć tryb tylko do odczytu, przejdź do ClusterControl -> Wybierz urządzenie podrzędne Klaster -> Węzły. W tej sekcji wybierz każdy węzeł i użyj opcji Wyłącz tylko do odczytu.
Odbudowa klastra niewolników
Aby uniknąć niespójności, jeśli chcesz odbudować klaster podrzędny, musi to być klaster tylko do odczytu, co oznacza, że wszystkie węzły muszą być w trybie tylko do odczytu.
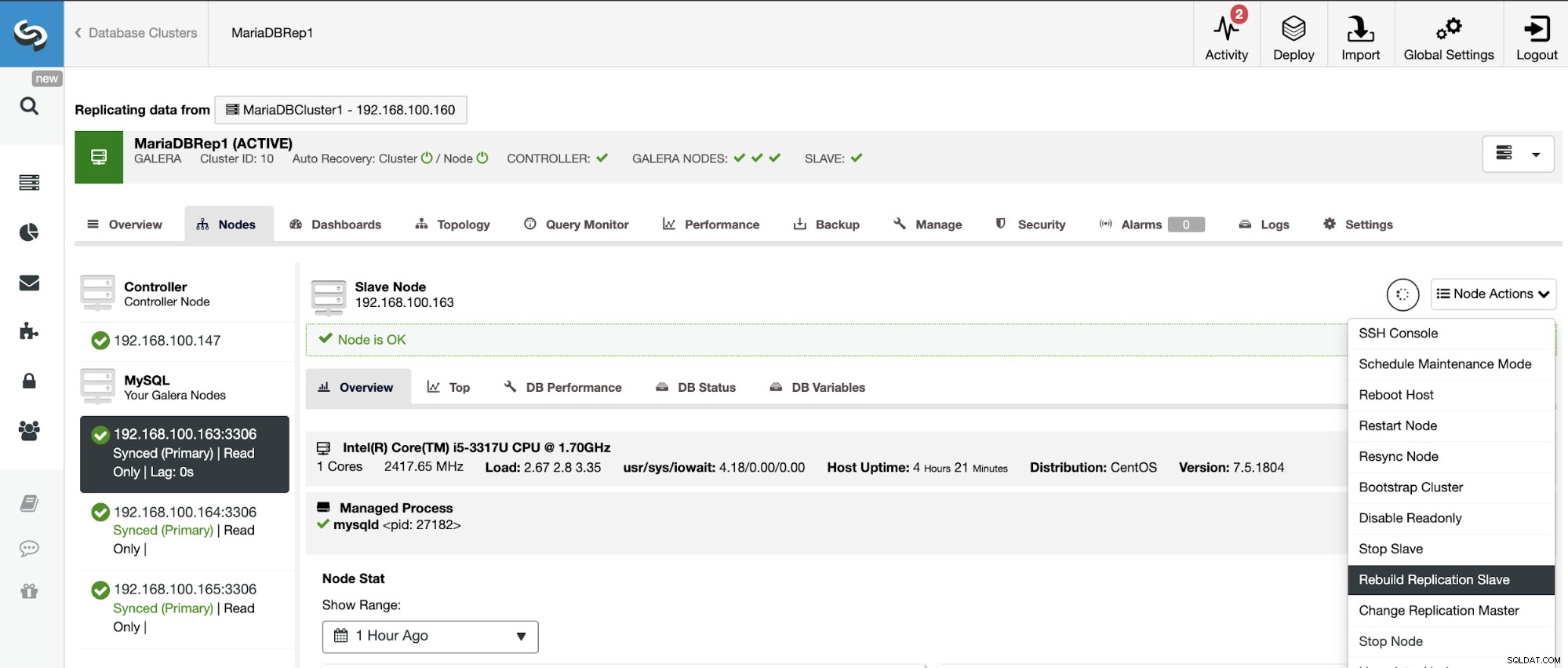
Przejdź do ClusterControl -> Wybierz klaster podrzędny -> Węzły -> Wybierz Węzeł połączony z klastrem głównym -> Akcje węzła -> Odbuduj replikację podrzędną.
Zmiany topologii
Jeśli masz następującą topologię:
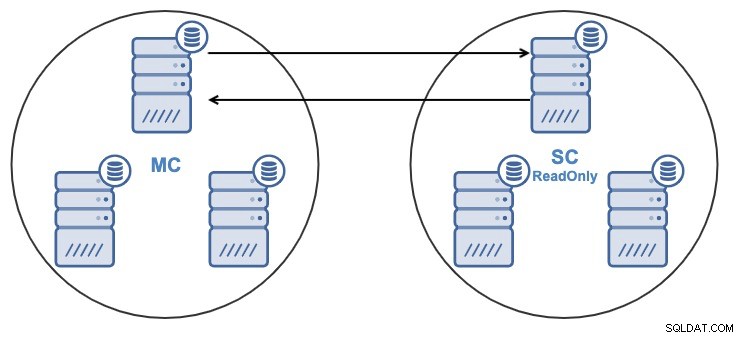
I z jakiegoś powodu chcesz zmienić węzeł replikacji w Master Grupa. Istnieje możliwość zmiany węzła głównego używanego przez klaster podrzędny na inny węzeł główny w klastrze głównym.
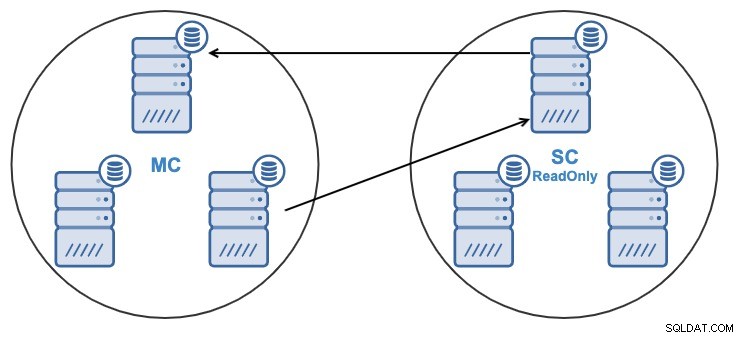
Aby można go było uznać za węzeł główny, musi mieć włączone logowanie binarne .
Przejdź do ClusterControl -> Wybierz klaster podrzędny -> Węzły -> Wybierz Węzeł podłączony do Master Cluster -> Node Actions -> Stop Slave/Start Slave.
Zatrzymaj/uruchom replikację podrzędną
Możesz zatrzymywać i uruchamiać urządzenia podrzędne replikacji w łatwy sposób za pomocą ClusterControl.
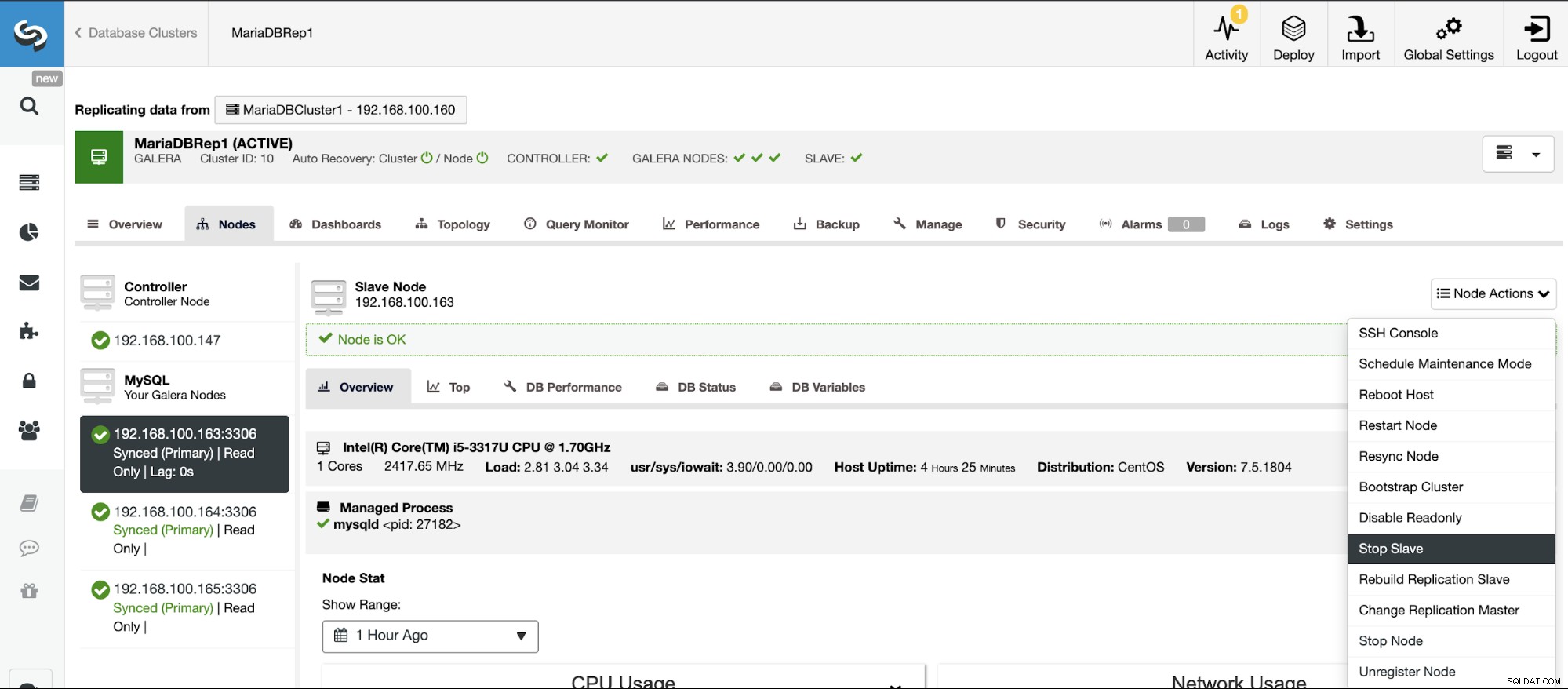
Przejdź do ClusterControl -> Wybierz klaster podrzędny -> Węzły -> Wybierz Węzeł podłączony do Master Cluster -> Node Actions -> Stop Slave/Start Slave.
Zresetuj podrzędną replikację
Za pomocą tej akcji możesz zresetować proces replikacji za pomocą opcji RESETUJ SLAVE lub RESETUJ SLAVE WSZYSTKO. Różnica między nimi polega na tym, że RESET SLAVE nie zmienia żadnego parametru replikacji, takiego jak host główny, port i poświadczenia. Aby usunąć te informacje, musisz użyć polecenia RESETUJ SLAVE WSZYSTKO, które usuwa całą konfigurację replikacji, więc użycie tego polecenia spowoduje zniszczenie łącza replikacji klastrów do klastrów.
Przed użyciem tej funkcji należy zatrzymać proces replikacji (proszę zapoznać się z poprzednią funkcją).
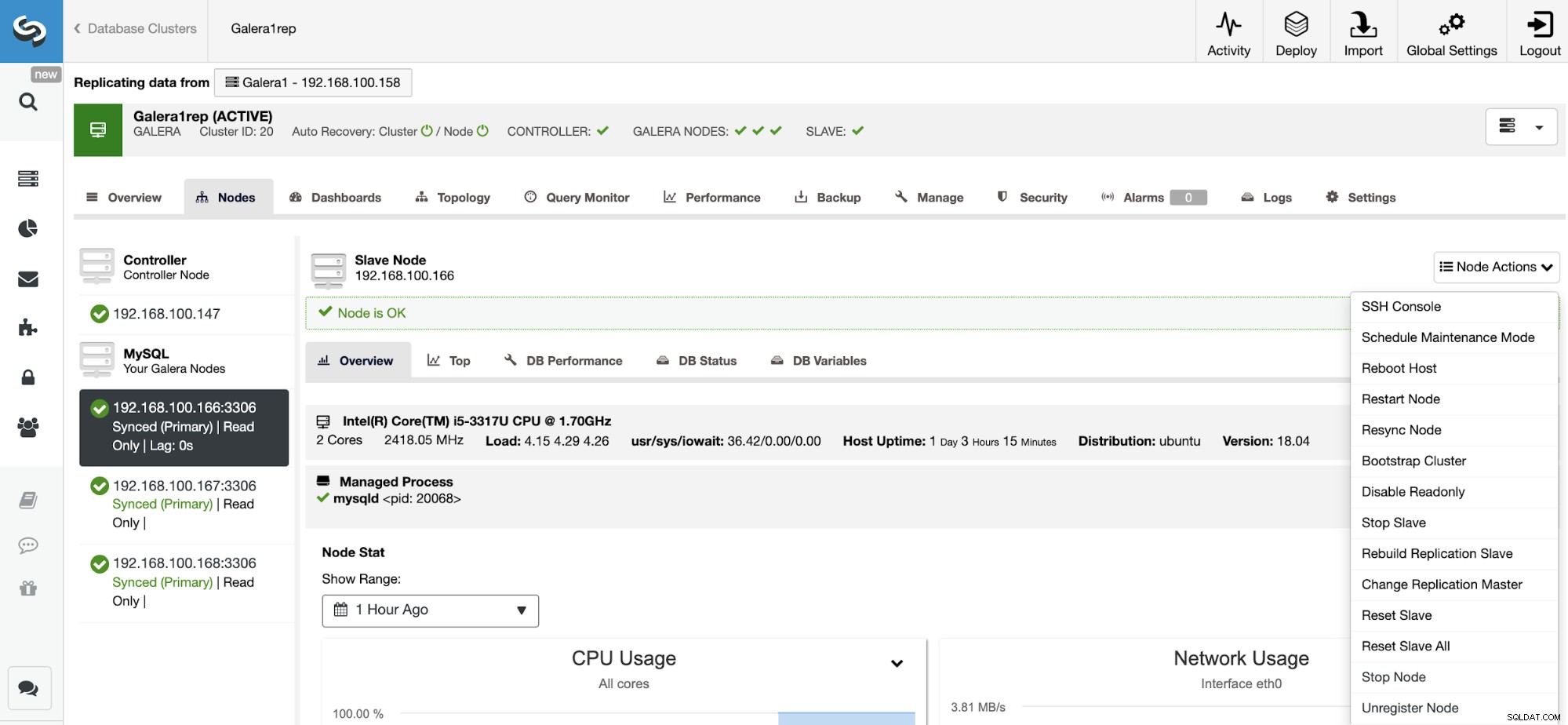
Przejdź do ClusterControl -> Wybierz klaster podrzędny -> Węzły -> Wybierz Węzeł podłączony do Master Cluster -> Akcje węzła -> Resetuj Slave/Reset Slave All.
Zarządzanie replikacją między klastrami za pomocą interfejsu wiersza polecenia ClusterControl
W poprzedniej sekcji można było zobaczyć, jak zarządzać replikacją między klastrami za pomocą interfejsu użytkownika ClusterControl. Zobaczmy teraz, jak to zrobić za pomocą wiersza poleceń.
Uwaga:jak wspomnieliśmy na początku tego bloga, założymy, że masz zainstalowany ClusterControl i Master Cluster został wdrożony przy jego użyciu.
Utwórz klaster niewolników
Najpierw spójrzmy na przykładowe polecenie tworzenia klastra podrzędnego za pomocą CLI Control CLI:
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logTeraz masz uruchomiony proces tworzenia podrzędnego, zobaczmy każdy użyty parametr:
- Klaster:do wyświetlania i manipulowania klastrami.
- Utwórz:utwórz i zainstaluj nowy klaster.
- Nazwa klastra:nazwa nowego klastra podrzędnego.
- Typ klastra:typ klastra do zainstalowania.
- Wersja dostawcy:Wersja oprogramowania.
- Węzły:Lista nowych węzłów w Klastrze Slave.
- Os-user:nazwa użytkownika dla poleceń SSH.
- Plik klucza systemu operacyjnego:plik klucza używany do połączenia SSH.
- Db-admin:nazwa użytkownika administratora bazy danych.
- Db-admin-passwd:hasło administratora bazy danych.
- Remote-cluster-id:identyfikator głównego klastra dla replikacji klaster-klaster.
- Dziennik:Poczekaj i monitoruj wiadomości o zadaniach.
Używając flagi --log, będziesz mógł zobaczyć logi w czasie rzeczywistym:
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.Konfiguruj klastry aktywny-aktywny
Jak widać było wcześniej, możesz wyłączyć tryb tylko do odczytu w nowym klastrze, wyłączając go w każdym węźle, więc zobaczmy, jak to zrobić z wiersza poleceń.
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --logZobaczmy każdy parametr:
- Węzeł:do obsługi węzłów.
- Ustaw-odczyt-zapis:Ustaw węzeł w trybie odczytu-zapisu.
- Węzły:węzeł, w którym należy to zmienić.
- Identyfikator klastra:identyfikator klastra, w którym znajduje się węzeł.
Następnie zobaczysz:
192.168.100.166:3306: Setting read_only=OFF.Odbudowa klastra niewolników
Możesz odbudować klaster Slave za pomocą następującego polecenia:
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --logParametry to:
- Replikacja:Do monitorowania i kontrolowania replikacji danych.
- Etap:Etapowanie/odbudowa niewolnika replikacji.
- Master:wzorzec replikacji w klastrze głównym.
- Slave:urządzenie podrzędne replikacji w klastrze podrzędnym.
- Identyfikator klastra:identyfikator klastra podrzędnego.
- Remote-cluster-id:identyfikator nadrzędnego klastra.
- Dziennik:Poczekaj i monitoruj wiadomości o zadaniach.
Dziennik zadań powinien być podobny do tego:
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.Zmiany topologii
Możesz zmienić swoją topologię za pomocą innego węzła w Master Cluster, z którego replikowane są dane, więc możesz na przykład uruchomić:
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --logSprawdźmy używane parametry.
- Replikacja:Do monitorowania i kontrolowania replikacji danych.
- Przełączanie awaryjne:przejmij rolę mistrza od nieudanego/starego mistrza.
- Master:nowy wzorzec replikacji w Master Cluster.
- Slave:Slave replikacji w Klastrze Slave.
- Cluster-id:identyfikator klastra slave.
- Remote-Cluster-id:identyfikator klastra głównego.
- Dziennik:Poczekaj i monitoruj wiadomości o zadaniach.
Zobaczysz ten dziennik:
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'Zatrzymaj/uruchom replikację podrzędną
Możesz zatrzymać replikację danych z Master Cluster w ten sposób:
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logZobaczysz to:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.Teraz możesz zacząć od nowa:
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logWięc zobaczysz:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.Teraz sprawdźmy używane parametry.
- Replikacja:Do monitorowania i kontrolowania replikacji danych.
- Stop/Start:Aby urządzenie podrzędne zatrzymało/rozpoczęło replikację.
- Slave:węzeł podrzędny replikacji.
- Identyfikator klastra:identyfikator klastra, w którym znajduje się węzeł podrzędny.
- Dziennik:Poczekaj i monitoruj wiadomości o zadaniach.
Zresetuj podrzędną replikację
Za pomocą tego polecenia możesz zresetować proces replikacji za pomocą opcji RESET SLAVE lub RESET SLAVE ALL. Aby uzyskać więcej informacji na temat tego polecenia, sprawdź jego użycie w poprzedniej sekcji interfejsu użytkownika ClusterControl.
Przed użyciem tej funkcji należy zatrzymać proces replikacji (proszę zapoznać się z poprzednim poleceniem).
ZRESETUJ PODRĘCZNIK:
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --logDziennik powinien wyglądać następująco:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.ZRESETUJ WSZYSTKIE WSZYSTKIE:
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logI ten dziennik powinien być:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.Zobaczmy używane parametry zarówno dla RESETUJ SLAVE, jak i RESETUJ SLAVE WSZYSTKO.
- Replikacja:Do monitorowania i kontrolowania replikacji danych.
- Reset:Zresetuj węzeł podrzędny.
- Wymuś:Używając tej flagi użyjesz polecenia RESET SLAVE ALL na węźle podrzędnym.
- Slave:węzeł podrzędny replikacji.
- Identyfikator klastra:identyfikator klastra podrzędnego.
- Dziennik:Poczekaj i monitoruj wiadomości o zadaniach.
Wnioski
Ta nowa funkcja ClusterControl umożliwia szybkie tworzenie replikacji Cluster-to-Cluster i zarządzanie nią w łatwy i przyjazny sposób. To środowisko poprawi topologię bazy danych/klastra i będzie przydatne w przypadku planu odzyskiwania po awarii, środowiska testowego i jeszcze innych opcji wymienionych w blogu przeglądowym.



