Niedawno napisaliśmy kilka blogów opisujących, jak różni dostawcy usług w chmurze radzą sobie z przełączaniem awaryjnym bazy danych. Porównaliśmy wydajność przełączania awaryjnego w Amazon Aurora, Amazon RDS i ClusterControl, przetestowaliśmy zachowanie przełączania awaryjnego w Amazon RDS, a także w Google Cloud Platform. Chociaż usługi te zapewniają świetne opcje przełączania awaryjnego, mogą nie być odpowiednie dla każdej aplikacji.
W tym poście na blogu poświęcimy trochę czasu na analizę zalet i wad korzystania z rozwiązań DBaaS w porównaniu z ręcznym projektowaniem środowiska lub przy użyciu platformy zarządzania bazą danych, takiej jak ClusterControl.
Wdrażanie baz danych o wysokiej dostępności za pomocą rozwiązań zarządzanych
Głównym powodem korzystania z istniejących rozwiązań jest łatwość użytkowania. Wystarczy kilka kliknięć, aby wdrożyć wysoce dostępne rozwiązanie z automatycznym przełączaniem awaryjnym. Nie ma potrzeby łączenia ze sobą różnych narzędzi, ręcznego zarządzania bazami danych, wdrażania narzędzi, pisania skryptów, projektowania monitoringu ani żadnych innych operacji związanych z zarządzaniem bazami danych. Wszystko jest już na swoim miejscu. Może to poważnie skrócić krzywą uczenia się i wymaga mniejszego doświadczenia, aby skonfigurować wysoce dostępne środowisko dla baz danych; pozwalając w zasadzie każdemu na wdrożenie takich konfiguracji.
W większości przypadków z tymi rozwiązaniami proces przełączania awaryjnego jest wykonywany w rozsądnym czasie. Może działać błyskawicznie, jak w przypadku Amazon Aurora, lub nieco wolniej, jak w przypadku węzłów SQL Google Cloud Platform. W większości przypadków tego typu wyniki są akceptowalne.
Dolna linia. Jeśli możesz zaakceptować 30 - 60 sekund przestoju, powinieneś być w porządku, używając dowolnej platformy DBaaS.
Wady korzystania z rozwiązania zarządzanego dla HA
Chociaż rozwiązania DBaaS są proste w użyciu, mają też poważne wady. Na początek zawsze należy wziąć pod uwagę element uzależnienia od dostawcy. Po wdrożeniu klastra w Amazon Web Services migracja z tego dostawcy jest dość trudna. Nie ma łatwych metod na pobranie pełnego zestawu danych poprzez fizyczną kopię zapasową. W przypadku większości dostawców dostępne są tylko ręcznie wykonywane logiczne kopie zapasowe. Jasne, zawsze istnieją opcje, aby to osiągnąć, ale zazwyczaj jest to złożony, czasochłonny proces, który mimo wszystko może wymagać przestoju.
Korzystanie z dostawcy takiego jak Amazon RDS również wiąże się z ograniczeniami. Niektóre czynności nie są łatwe do wykonania, co byłoby bardzo proste do wykonania na środowiskach wdrożonych w sposób w pełni kontrolowany przez użytkownika (np. AWS EC2). Niektóre z tych ograniczeń zostały już omówione w innych blogach, ale podsumowując, żadna usługa DBaaS nie zapewnia takiego samego poziomu elastyczności, jak zwykła replikacja MySQL oparta na GTID. Możesz promować dowolnego niewolnika, możesz ponownie podporządkować każdy węzeł z dowolnego innego... praktycznie każda akcja jest możliwa. Dzięki narzędziom takim jak RDS napotykasz ograniczenia wynikające z projektowania, których nie możesz ominąć.
Problem polega również na zdolności do zrozumienia szczegółów wydajności. Projektując własną wysoce dostępną konfigurację, zdobywasz wiedzę na temat potencjalnych problemów z wydajnością, które mogą się pojawić. Z drugiej strony RDS i podobne środowiska to w zasadzie „czarne skrzynki”. Tak, dowiedzieliśmy się, że Amazon RDS używa DRBD do tworzenia kopii w tle mastera, wiemy, że Aurora używa współdzielonej, zreplikowanej pamięci masowej do wdrażania bardzo szybkich przełączeń awaryjnych. To tylko ogólna wiedza. Nie możemy powiedzieć, jakie są implikacje wydajnościowe tych rozwiązań, inne niż to, co moglibyśmy przypadkowo zauważyć. Jakie są wspólne problemy z nimi związane? Jak stabilne są te rozwiązania? Tylko programiści stojący za rozwiązaniem wiedzą na pewno.
Jaka jest alternatywa dla rozwiązań DBaaS?
Możesz się zastanawiać, czy istnieje alternatywa dla DBaaS? W końcu tak wygodnie jest uruchomić usługę zarządzaną, w której można uzyskać dostęp do większości typowych działań za pośrednictwem interfejsu użytkownika. Możesz tworzyć i przywracać kopie zapasowe, przełączanie awaryjne jest obsługiwane automatycznie. Środowisko jest łatwe w użyciu, co może być atrakcyjne dla firm, które nie mają oddanego i doświadczonego personelu do obsługi baz danych.
ClusterControl stanowi doskonałą alternatywę dla usług DBaaS opartych na chmurze. Zapewnia graficzny interfejs użytkownika, którego można używać do wdrażania, zarządzania i monitorowania baz danych typu open source.
Za pomocą kilku kliknięć możesz łatwo wdrożyć klaster bazy danych o wysokiej dostępności, z automatycznym przełączaniem awaryjnym (szybszym niż większość ofert DBaaS), zarządzaniem kopiami zapasowymi, zaawansowanym monitorowaniem i innymi funkcjami, takimi jak integracja z narzędziami zewnętrznymi (np. Slack lub PagerDuty) lub zarządzanie aktualizacjami. Wszystko to przy całkowitym uniknięciu uzależnienia od dostawcy.
ClusterControl nie dba o to, gdzie znajdują się Twoje bazy danych, o ile może połączyć się z nimi za pomocą SSH. Możesz mieć konfiguracje w chmurze, lokalnie lub w mieszanym środowisku wielu dostawców chmury. Dopóki istnieje łączność, ClusterControl będzie w stanie zarządzać środowiskiem. Korzystanie z pożądanych rozwiązań (a nie tych, których nie znasz ani których nie znasz) pozwala przejąć pełną kontrolę nad otoczeniem w dowolnym momencie.
Niezależnie od tego, jaką konfigurację wdrożyłeś za pomocą ClusterControl, możesz łatwo nią zarządzać w bardziej tradycyjny, ręczny lub skryptowy sposób. ClusterControl zapewnia nawet interfejs wiersza poleceń, który umożliwia włączenie zadań wykonywanych przez ClusterControl do skryptów powłoki. Masz pełną kontrolę, jakiej potrzebujesz - nic nie jest czarną skrzynką, każdy element środowiska zostałby zbudowany przy użyciu rozwiązań open source połączonych ze sobą i wdrożonych przez ClusterControl.
Przyjrzyjmy się, jak łatwo można wdrożyć klaster MySQL Replication za pomocą ClusterControl. Załóżmy, że masz przygotowane środowisko z ClusterControl zainstalowanym na jednej instancji i wszystkimi innymi węzłami dostępnymi przez SSH z hosta ClusterControl.
Zaczniemy od wybrania kreatora „Wdrażanie”.
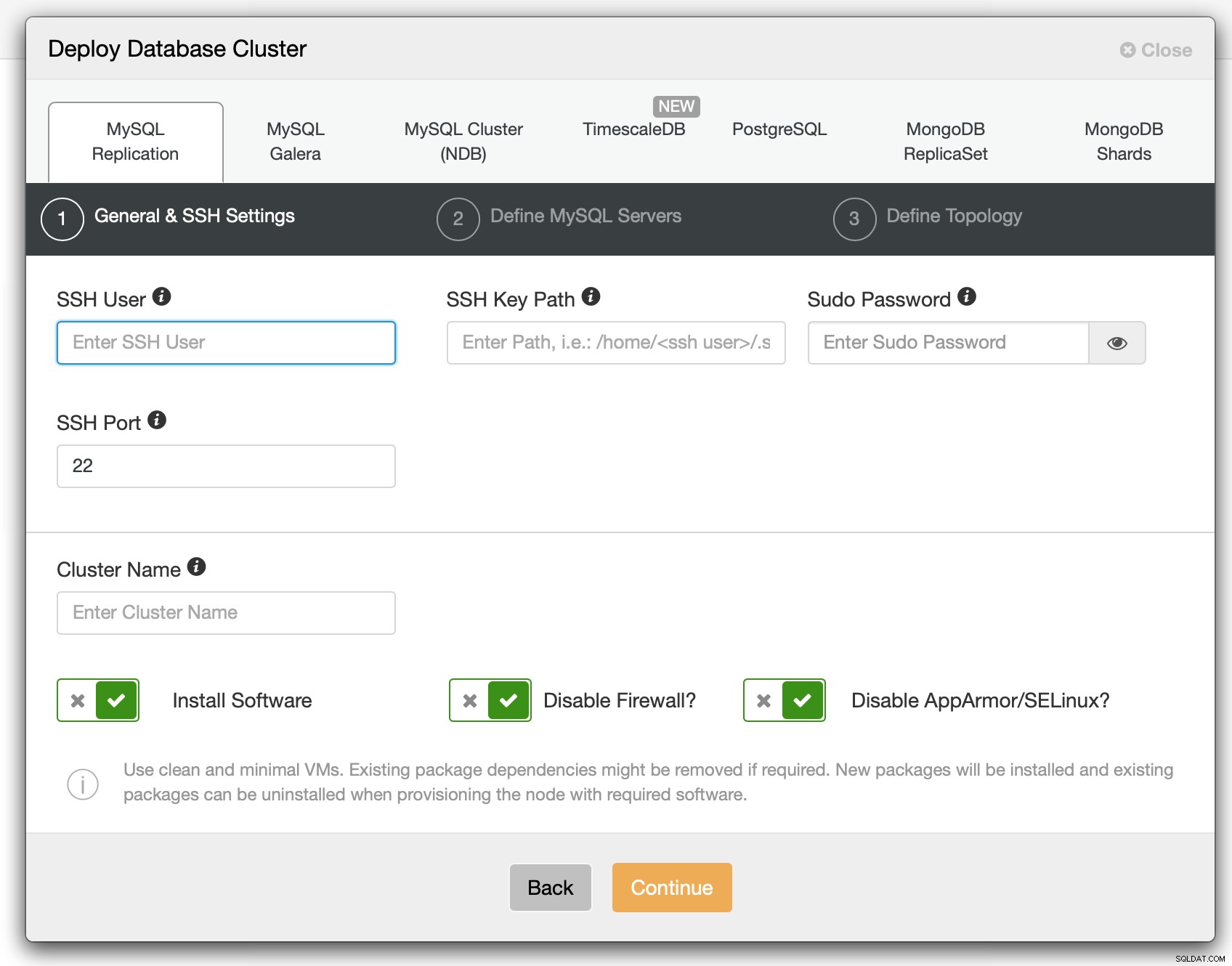
W pierwszym kroku musimy zdefiniować, w jaki sposób ClusterControl ma łączyć się z węzłami na których bazy danych mają zostać wdrożone. Obsługiwany jest zarówno dostęp root, jak i sudo (z hasłem lub bez).
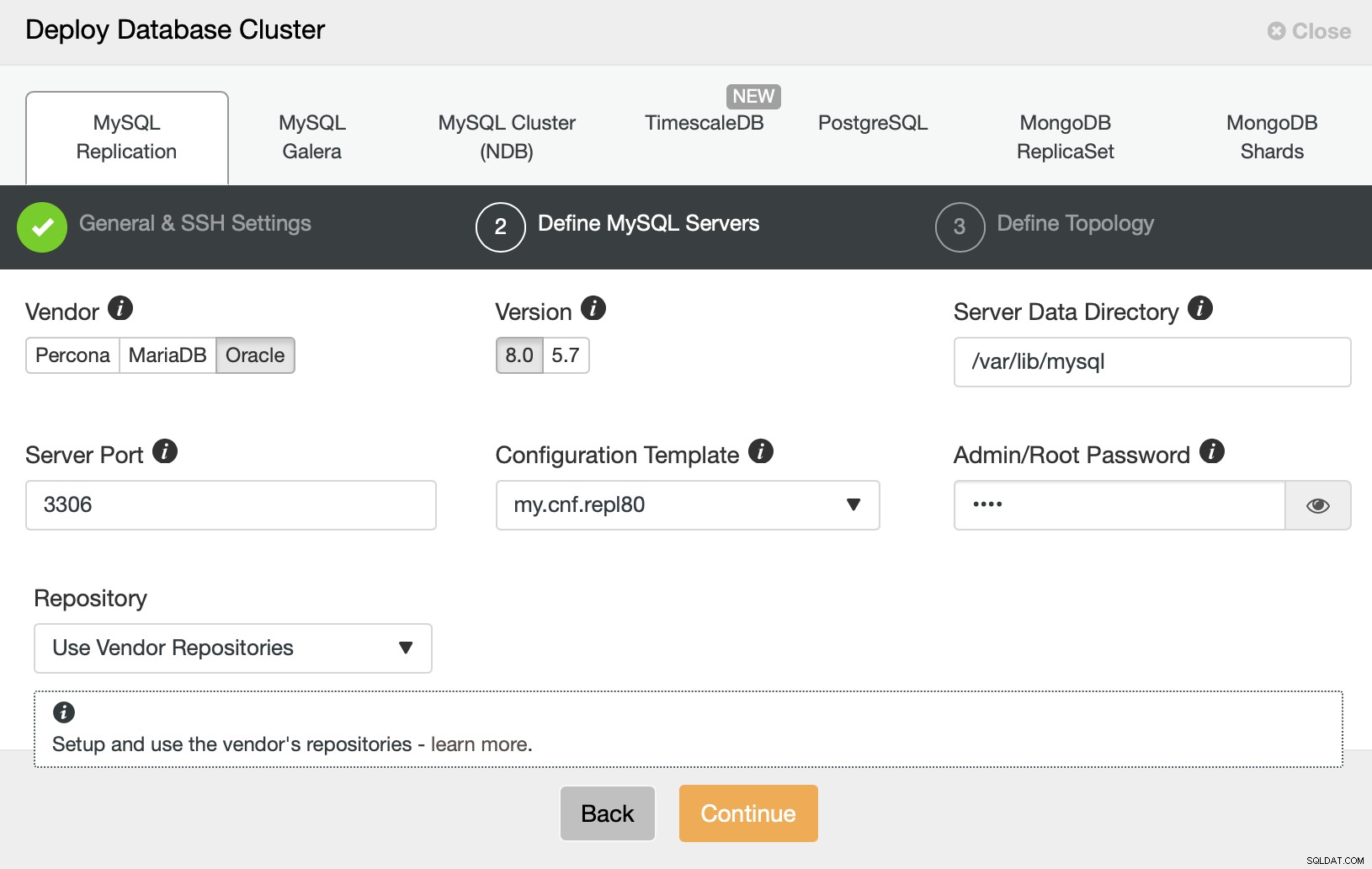
Następnie chcemy wybrać dostawcę, wersję i przekazać hasło dla użytkownik administracyjny w naszej bazie danych MySQL.
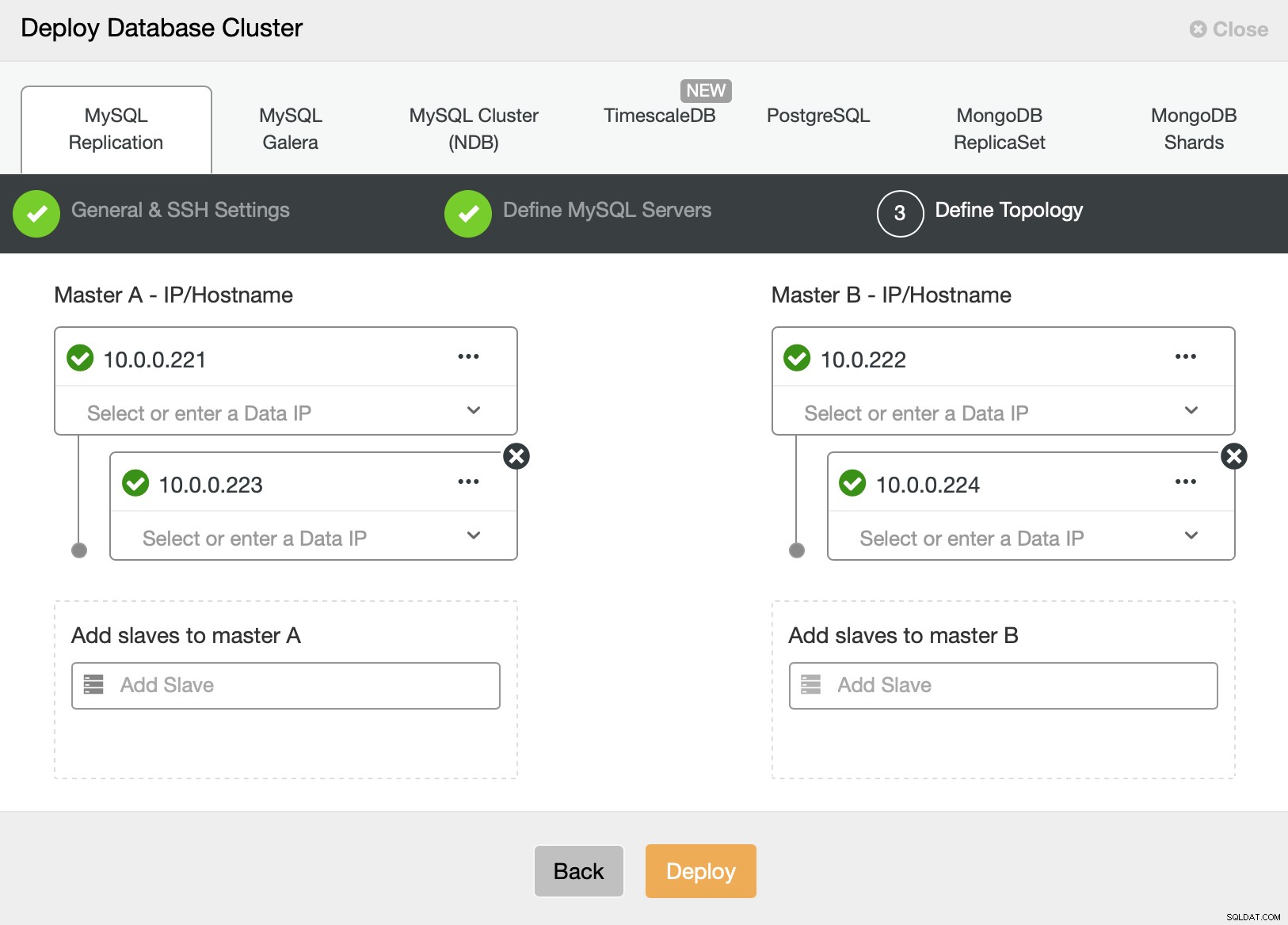
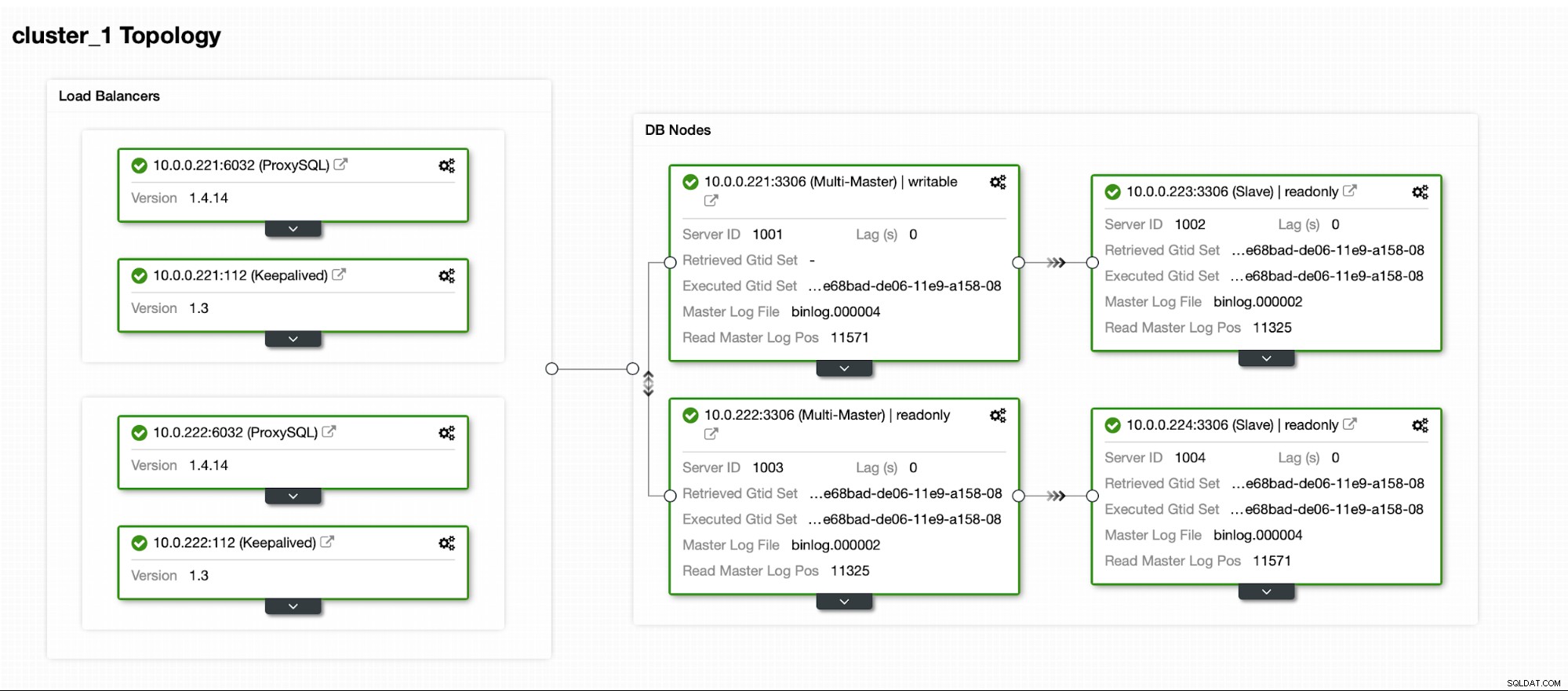
Na koniec chcemy zdefiniować topologię naszego nowego klastra. Jak widać, jest to już dość złożona konfiguracja, w przeciwieństwie do czegoś, co można wdrożyć za pomocą węzła AWS RDS lub GCP SQL.
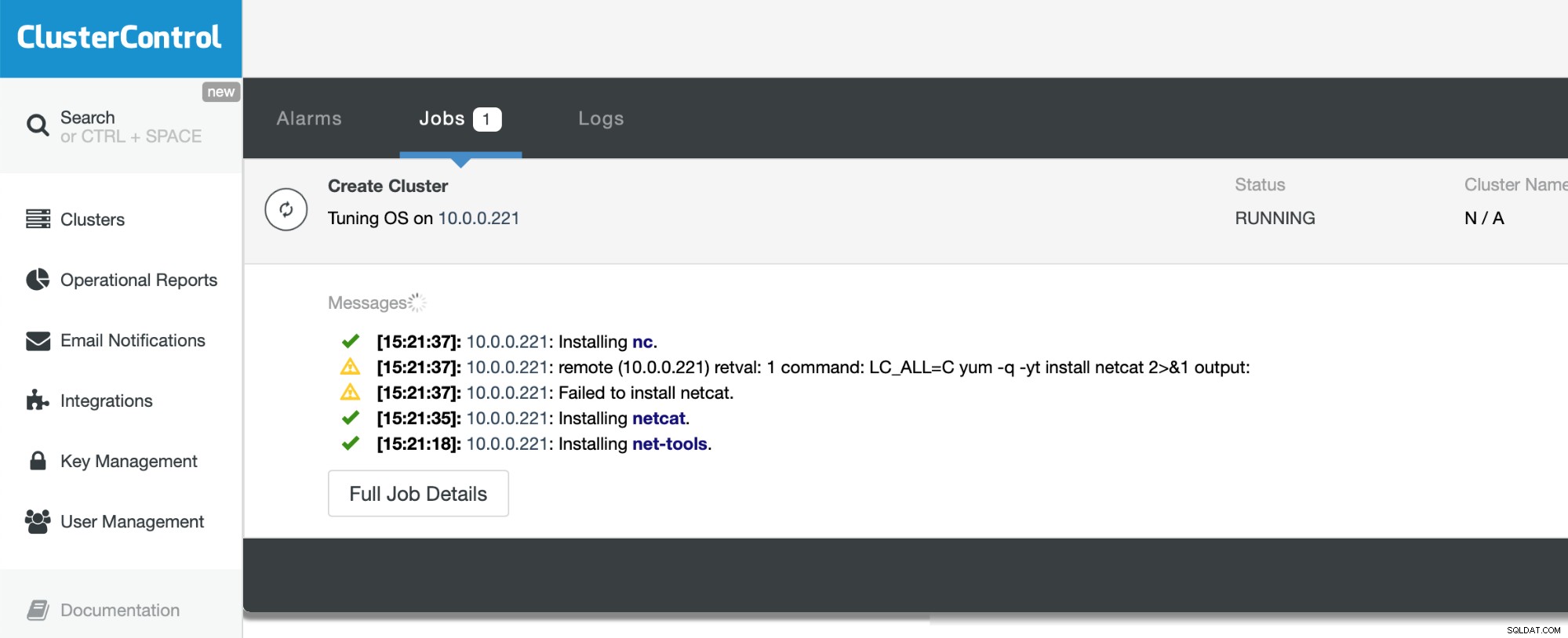
Jedyne, co musimy teraz zrobić, to poczekać na zakończenie procesu. ClusterControl dołoży wszelkich starań, aby zrozumieć środowisko, w którym jest wdrażany, i zainstalować wymagany zestaw pakietów, w tym samą bazę danych.

Po uruchomieniu klastra możesz kontynuować wdrażanie warstwa proxy (która zapewni aplikacji pojedynczy punkt wejścia do warstwy bazy danych). Tak mniej więcej dzieje się za kulisami w przypadku DBaaS, w którym masz również punkty końcowe do łączenia się z klastrem bazy danych. Dosyć powszechne jest używanie jednego punktu końcowego do zapisów i wielu punktów końcowych do dotarcia do konkretnych replik.
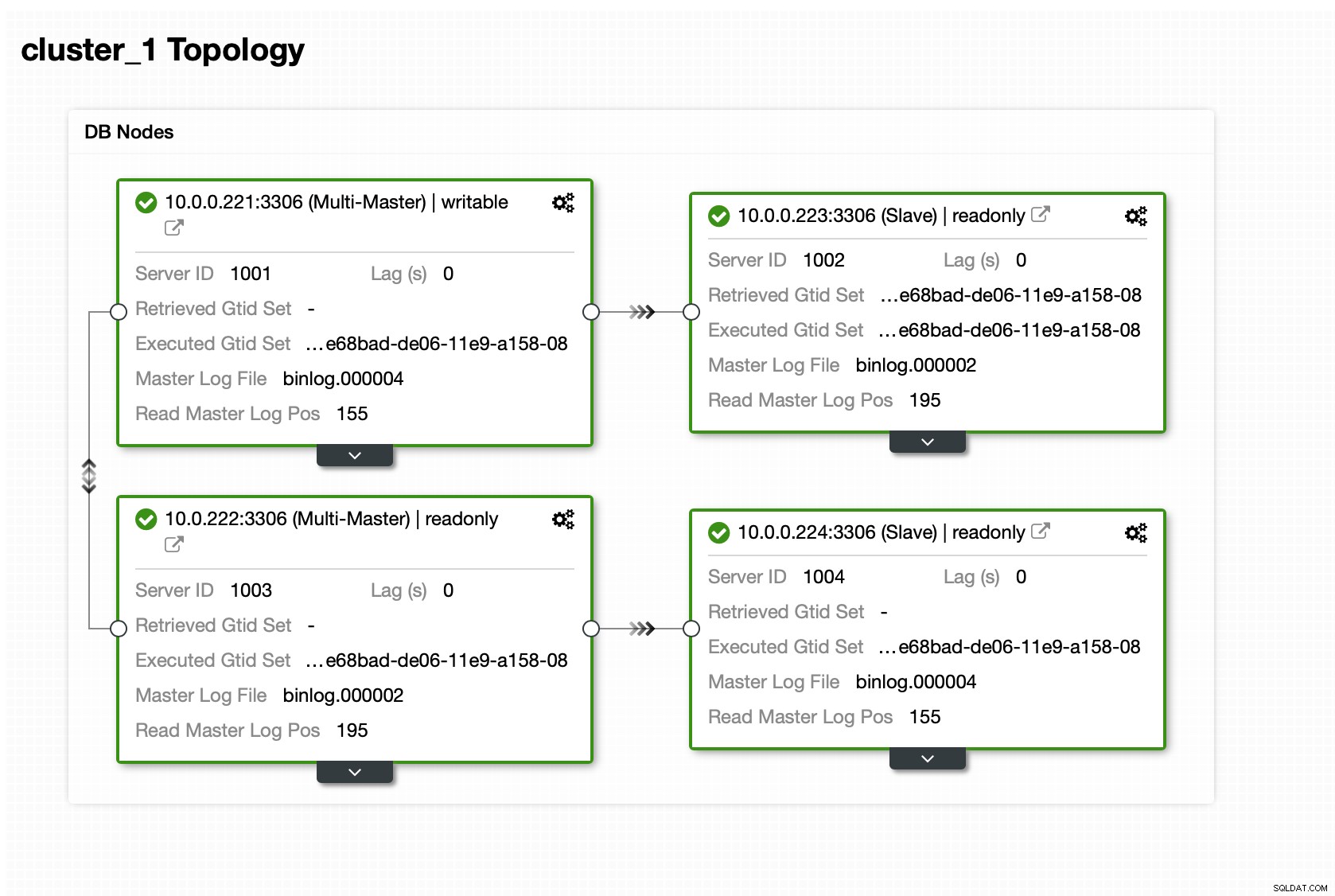
Tutaj użyjemy ProxySQL, który zrobi za nas brudną robotę - zrozumie topologię, wysyła zapisy tylko do urządzenia głównego i zapytania tylko do odczytu równoważące obciążenie we wszystkich posiadanych replikach.
Aby wdrożyć ProxySQL, przejdziemy do Zarządzaj -> Systemy równoważenia obciążenia.
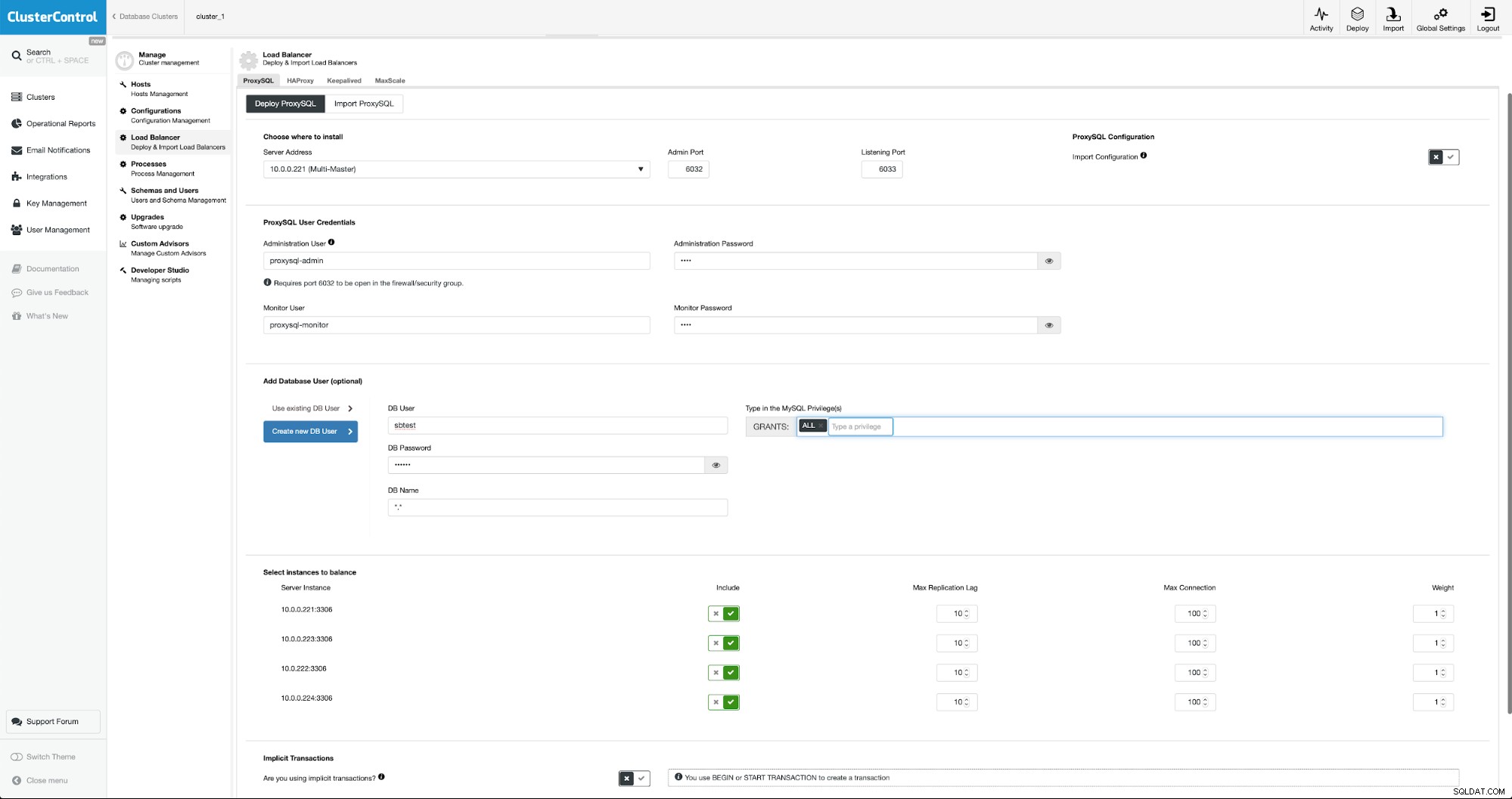
Musimy wypełnić wszystkie wymagane pola:hosty do wdrożenia, poświadczenia użytkownik administracyjny i monitorujący, możemy zaimportować istniejącego użytkownika z MySQL do ProxySQL lub stworzyć nowego. Wszystkie szczegóły dotyczące ProxySQL można łatwo znaleźć w wielu blogach w naszej sekcji blogów.
Chcemy, aby co najmniej dwa węzły ProxySQL zostały wdrożone, aby zapewnić wysoką dostępność. Następnie, po ich wdrożeniu, wdrożymy Keepalived na bazie ProxySQL. Zapewni to, że wirtualny adres IP zostanie skonfigurowany i będzie wskazywał jedną z instancji ProxySQL, o ile będzie co najmniej jeden sprawny węzeł.
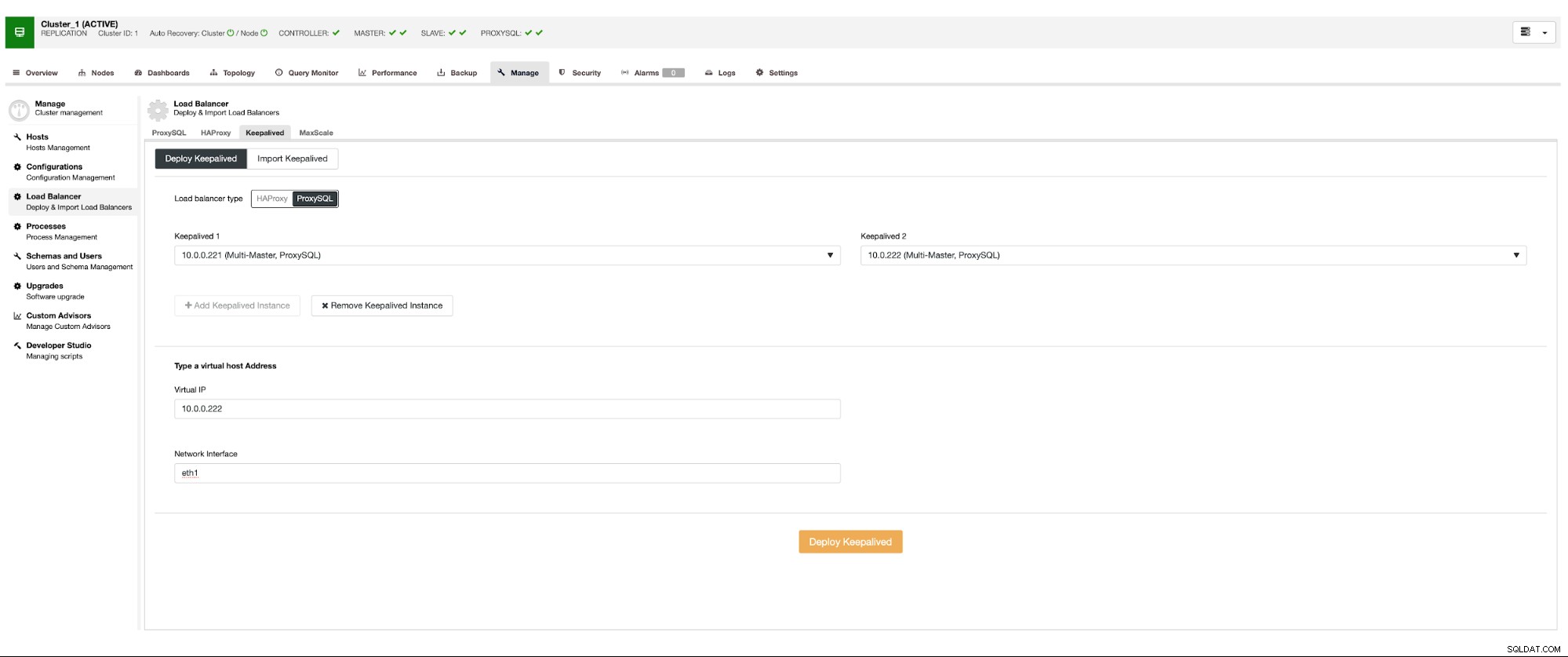
Oto jedyny potencjalny problem, jeśli korzystasz ze środowisk chmurowych, w których działa routing w sposób, który nie jest łatwy do wywołania interfejsu sieciowego. W takim przypadku będziesz musiał zmodyfikować konfigurację Keepalive, wprowadzić skrypt 'notify_master' i użyć skryptu, który dokona niezbędnych zmian IP - w przypadku EC2 musiałby odłączyć Elastic IP od jednego hosta i dołączyć go do inny gospodarz.
Istnieje wiele instrukcji, jak to zrobić, korzystając z szeroko przetestowanego oprogramowania open source w konfiguracjach wdrożonych przez ClusterControl. Możesz łatwo znaleźć dodatkowe informacje, wskazówki i poradniki, które są istotne dla Twojego konkretnego środowiska.
Wniosek
Mamy nadzieję, że ten wpis na blogu był dla Ciebie wnikliwy. Jeśli chcesz przetestować ClusterControl, otrzymasz 30-dniową wersję próbną dla przedsiębiorstw, w której dostępne są wszystkie funkcje. Możesz go pobrać za darmo i przetestować, czy pasuje do Twojego środowiska.



