Zważywszy, że wysoka dostępność jest najważniejsza w dzisiejszej rzeczywistości biznesowej, jednym z najczęstszych scenariuszy, z którymi muszą sobie radzić użytkownicy, jest zapewnienie, że baza danych będzie zawsze dostępna dla aplikacji.
Każdy dostawca usług wiąże się z dziedzicznym ryzykiem zakłócenia usług, dlatego jednym z kroków, które można podjąć, jest poleganie na wielu dostawcach w celu złagodzenia ryzyka i dodatkowej redundancji.
Dostawcy usług w chmurze nie różnią się od siebie - mogą zawieść i należy to zaplanować z wyprzedzeniem. Jakie opcje są dostępne dla klastra MariaDB? Przyjrzyjmy się temu w tym poście na blogu.
Klastrowanie bazy danych MariaDB w środowiskach wielu chmur
Jeśli umowa SLA zaproponowana przez jednego dostawcę usług w chmurze nie jest wystarczająca, zawsze istnieje możliwość utworzenia witryny odzyskiwania po awarii poza tym dostawcą. Dzięki temu, gdy tylko jeden z dostawców chmury doświadczy pewnego pogorszenia jakości usług, zawsze możesz przełączyć się na innego dostawcę i utrzymać swoją bazę danych w stanie gotowości i dostępności.
Jednym z problemów typowych dla konfiguracji wielochmurowych jest opóźnienie sieci, którego nie da się uniknąć, jeśli mówimy o większych odległościach lub, ogólnie, wielu geograficznie oddzielonych lokalizacjach. Prędkość światła jest dość duża, ale skończona, każdy przeskok, każdy router dodaje też opóźnienia w infrastrukturze sieciowej.
Klaster MariaDB działa świetnie w sieciach o niskich opóźnieniach. Jest to klaster oparty na kworum, w którym wymagana jest szybka komunikacja między wszystkimi węzłami, aby zapewnić płynność operacji. Zwiększenie opóźnień w sieci wpłynie na działanie klastra, zwłaszcza na wydajność zapisów. Istnieje kilka sposobów rozwiązania tego problemu.
Najpierw mamy możliwość korzystania z oddzielnych klastrów połączonych za pomocą asynchronicznych łączy replikacyjnych. Pozwala nam to prawie zapomnieć o opóźnieniach, ponieważ replikacja asynchroniczna jest znacznie lepiej przystosowana do pracy w środowiskach o dużych opóźnieniach.
Inną opcją jest to, że biorąc pod uwagę sieci o małych opóźnieniach między centrami danych, nadal możesz całkiem dobrze uruchomić klaster MariaDB obejmujący kilka centrów danych. W końcu wiele centrów danych nie zawsze oznacza ogromne odległości pod względem geograficznym – możesz równie dobrze korzystać z wielu dostawców zlokalizowanych w tym samym obszarze metropolitalnym, połączonych szybkimi sieciami o niskim opóźnieniu. Wtedy będziemy mówić o wzroście opóźnień do co najwyżej dziesiątek milisekund, a na pewno nie setek. Wszystko zależy od aplikacji, ale taki wzrost może być do zaakceptowania.
Asynchroniczna replikacja między klastrami MariaDB
Rzućmy okiem na podejście asynchroniczne. Pomysł jest prosty - dwa klastry połączone ze sobą za pomocą replikacji asynchronicznej.
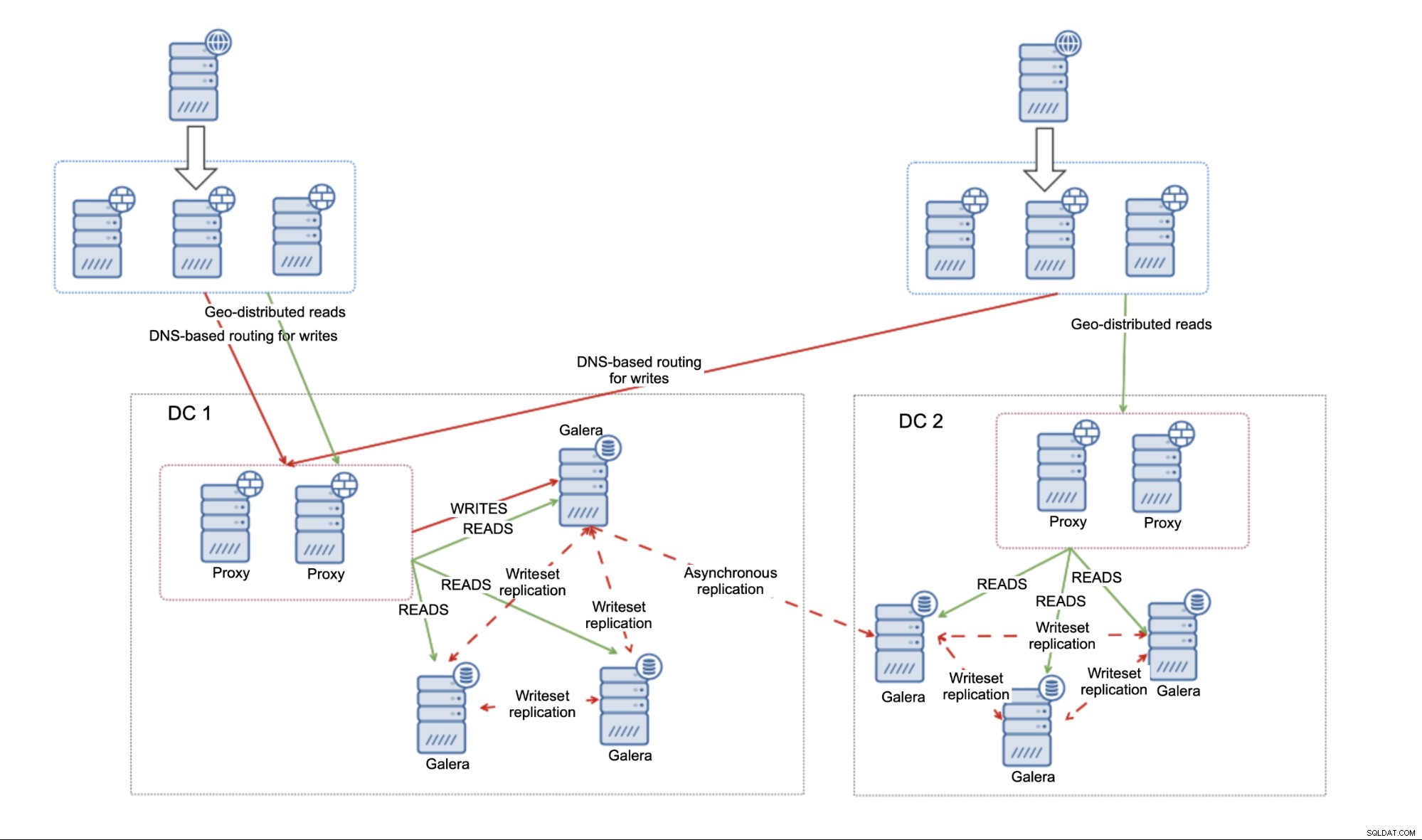
Wiąże się to z kilkoma ograniczeniami. Na początek musisz zdecydować, czy chcesz używać multi-mastera, czy też chcesz kierować cały ruch tylko do jednego centrum danych. Zalecamy unikanie pisania do obu centrów danych i używania replikacji master-master. Może to prowadzić do poważnych problemów, jeśli nie zachowasz ostrożności.
Jeżeli zdecydujesz się na użycie konfiguracji aktywny - pasywny, prawdopodobnie będziesz chciał zaimplementować jakiś rodzaj routingu opartego na DNS dla zapisów, aby upewnić się, że serwery aplikacji zawsze będą łączyć się z zestawem serwery proxy znajdujące się w aktywnym centrum danych. Można to osiągnąć albo dosłownie wpisując DNS, który zostanie zmieniony, gdy wymagane jest przełączenie awaryjne, albo można to zrobić za pomocą jakiegoś rozwiązania do wykrywania usług, takiego jak Consul lub etcd.
Główną wadą środowiska zbudowanego przy użyciu replikacji asynchronicznej jest brak możliwości radzenia sobie z podziałami sieci między centrami danych. Jest to dziedziczone z replikacji — bez względu na to, co chcesz połączyć z replikacją (pojedyncze węzły, klastry MariaDB), nie ma sposobu na obejście faktu, że replikacja nie uwzględnia kworum. Nie ma mechanizmu do śledzenia stanu węzłów i zrozumienia ogólnego obrazu całej topologii. W rezultacie za każdym razem, gdy połączenie między dwoma centrami danych zostanie przerwane, otrzymujesz dwa oddzielne klastry MariaDB, które nie są połączone i oba są gotowe do przyjmowania ruchu. Od użytkownika zależy, co zrobić w takim przypadku. Możliwe jest zaimplementowanie dodatkowych narzędzi, które monitorowałyby stan baz danych z zewnątrz (tj. z trzeciego datacenter), a następnie podejmowały działania (lub nie podejmowały działań) w oparciu o te informacje. Możliwa jest również kolokacja narzędzi, które współdzielą infrastrukturę z bazami danych, ale są świadome klastrów i mogą śledzić stan łączności w centrum danych i mogą być wykorzystywane jako źródło prawdy dla skryptów zarządzających środowiskiem. Na przykład ClusterControl można wdrożyć w klastrze z trzema węzłami, węzeł na centrum danych, który używa protokołu RAFT w celu zapewnienia kworum. Jeśli węzeł utraci łączność z resztą klastra, można założyć, że w centrum danych doszło do partycjonowania sieci.
Klastry Multi-DC MariaDB
Alternatywą dla replikacji asynchronicznej może być rozwiązanie oparte wyłącznie na klastrze MariaDB, które obejmuje wiele centrów danych.
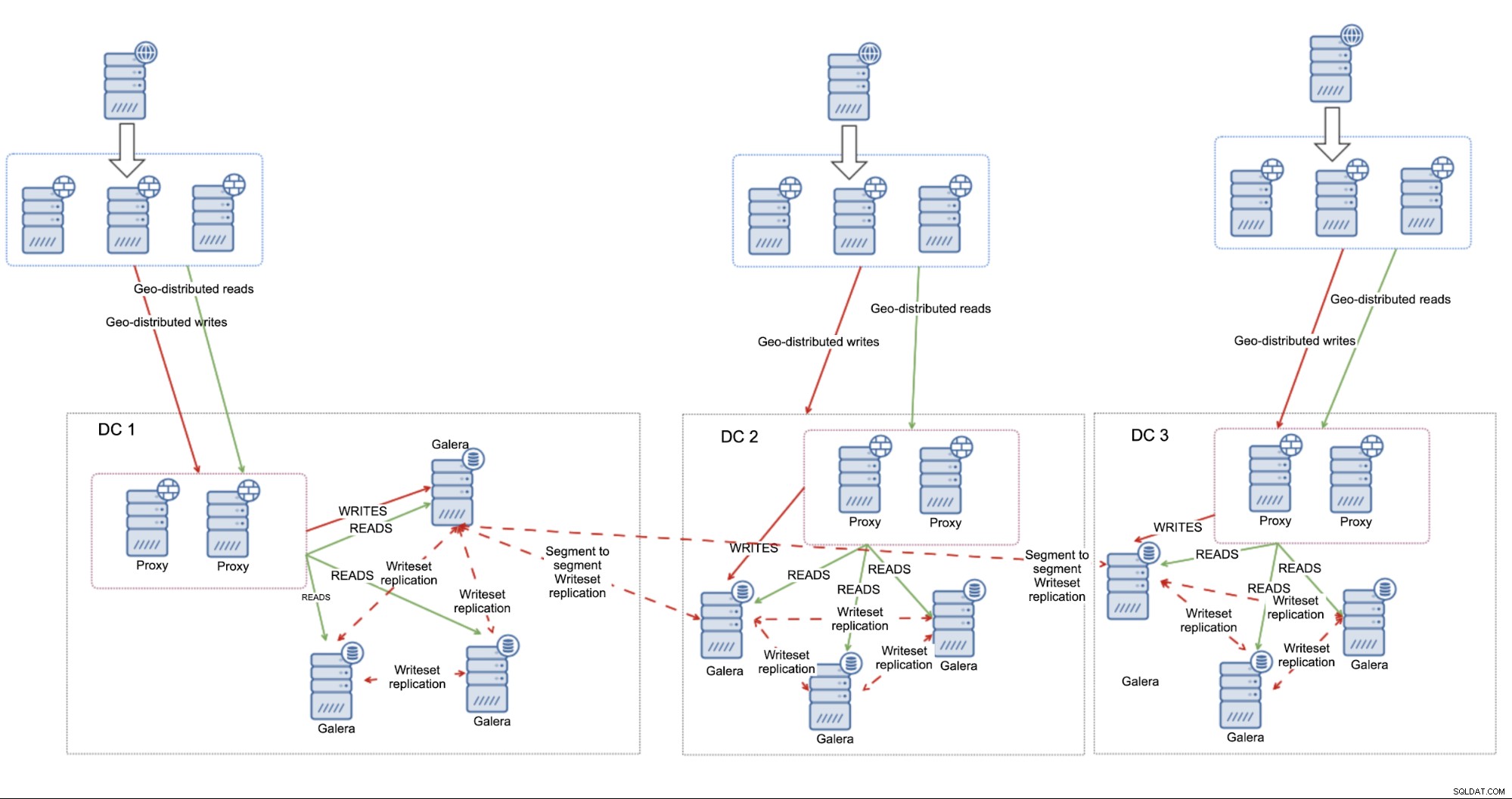
Jak wspomniano na początku tego bloga, Klaster MariaDB, podobnie jak każdy Klaster oparty na Galera będzie miał wpływ na wysokie opóźnienia. To powiedziawszy, całkowicie akceptowalne jest uruchamianie go w środowiskach o „niezbyt wysokich” opóźnieniach i oczekiwanie, że będzie zachowywał się prawidłowo, zapewniając akceptowalną wydajność. Wszystko zależy od przepustowości i konstrukcji sieci, odległości między centrami danych i wymagań aplikacji. Takie podejście sprawdzi się znakomicie zwłaszcza, jeśli użyjemy segmentów do odróżnienia oddzielnych centrów danych. Pozwala klasterowi MariaDB zoptymalizować łączność wewnątrz klastra i zredukować do minimum ruch między DC.
Główną zaletą tej konfiguracji jest to, że do obsługi błędów opiera się ona na klastrze MariaDB. Jeśli korzystasz z trzech centrów danych, jesteś prawie całkowicie zabezpieczony przed sytuacją rozszczepienia mózgu – dopóki istnieje większość, będzie nadal działać. Nie jest wymagane posiadanie pełnego węzła w trzecim datacenter – równie dobrze można użyć Galera Arbitrator, demona, który działa jako część klastra, ale nie musi obsługiwać żadnych operacji bazodanowych. Łączy się z węzłami, bierze udział w obliczaniu kworum i może być używany do przekazywania ruchu, jeśli bezpośrednie połączenie między dwoma centrami danych nie działa.
W takim przypadku cały proces przełączania awaryjnego można opisać jako:zdefiniuj wszystkie węzły w load balancerach (wszystko, jeśli centra danych są blisko siebie, w innym przypadku możesz chcieć dodać priorytet dla węzły znajdujące się bliżej systemu równoważenia obciążenia) i to prawie wszystko. Węzły klastra MariaDB, które stanowią większość, będą dostępne przez dowolny serwer proxy.
Wdrażanie klastra Multi-Cloud MariaDB przy użyciu ClusterControl
Przyjrzyjmy się dwóm opcjom, których możesz użyć do wdrożenia wielochmurowych klastrów MariaDB przy użyciu ClusterControl. Należy pamiętać, że ClusterControl wymaga łączności SSH ze wszystkimi węzłami, którymi będzie zarządzał, więc od Ciebie zależy zapewnienie łączności sieciowej w wielu centrach danych lub dostawcach chmury. Dopóki istnieje łączność, możemy skorzystać z dwóch metod.
Wdrażanie klastrów MariaDB przy użyciu replikacji asynchronicznej
ClusterControl może pomóc we wdrożeniu dwóch klastrów połączonych za pomocą replikacji asynchronicznej. Po wdrożeniu jednego klastra MariaDB należy upewnić się, że jeden z węzłów ma włączone dzienniki binarne. Umożliwi to użycie tego węzła jako głównego dla drugiego klastra, który wkrótce utworzymy.
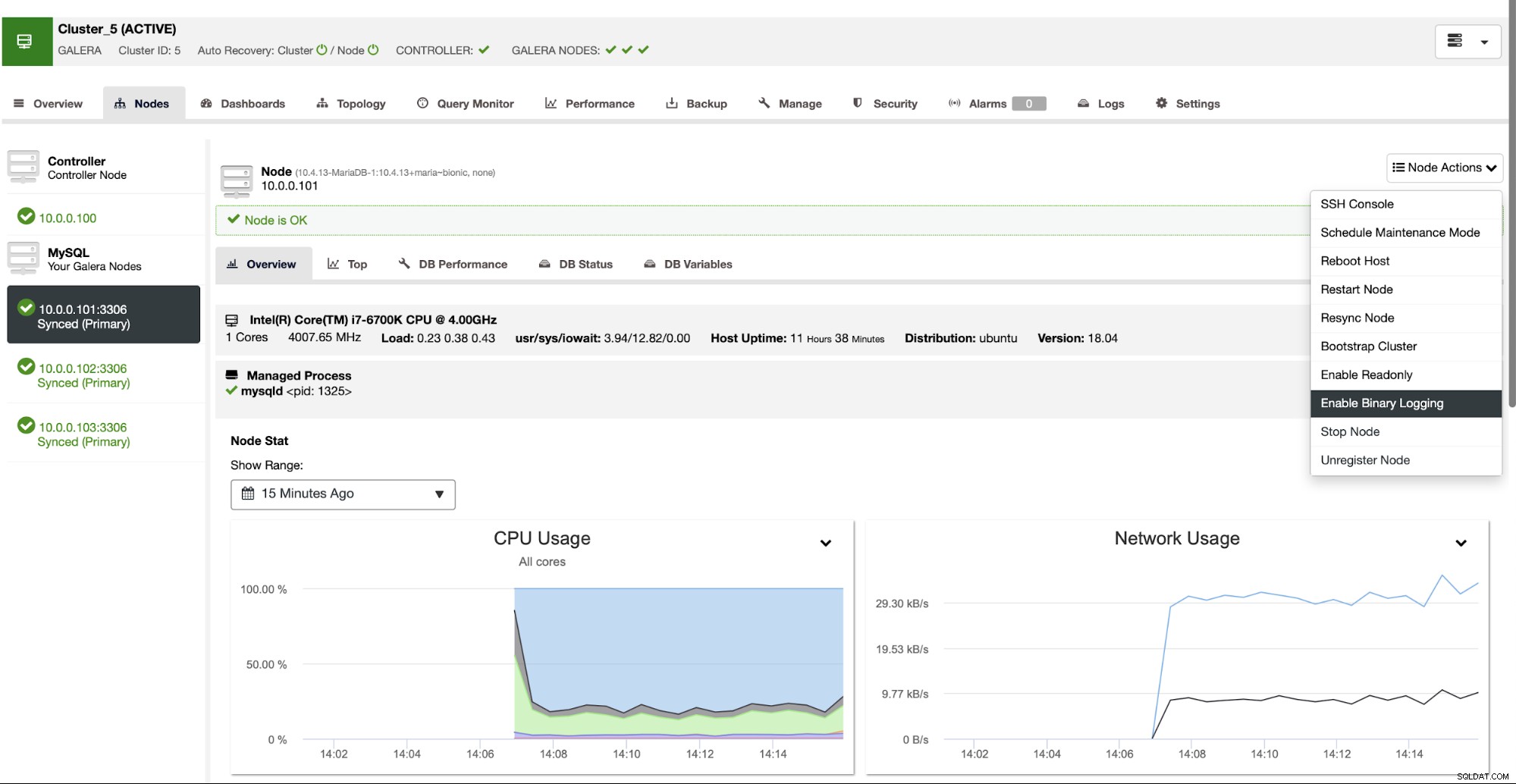
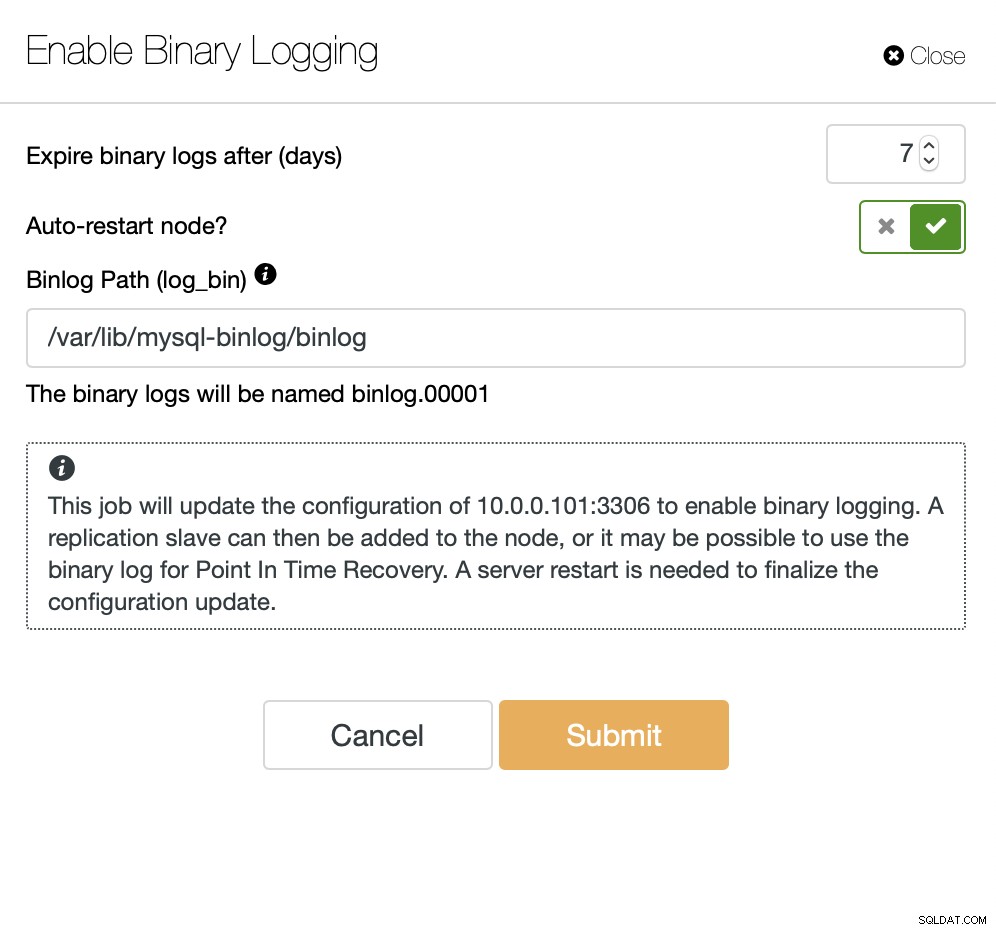
Po włączeniu dziennika binarnego możemy użyć zadania Utwórz klaster podrzędny aby uruchomić kreator wdrażania.
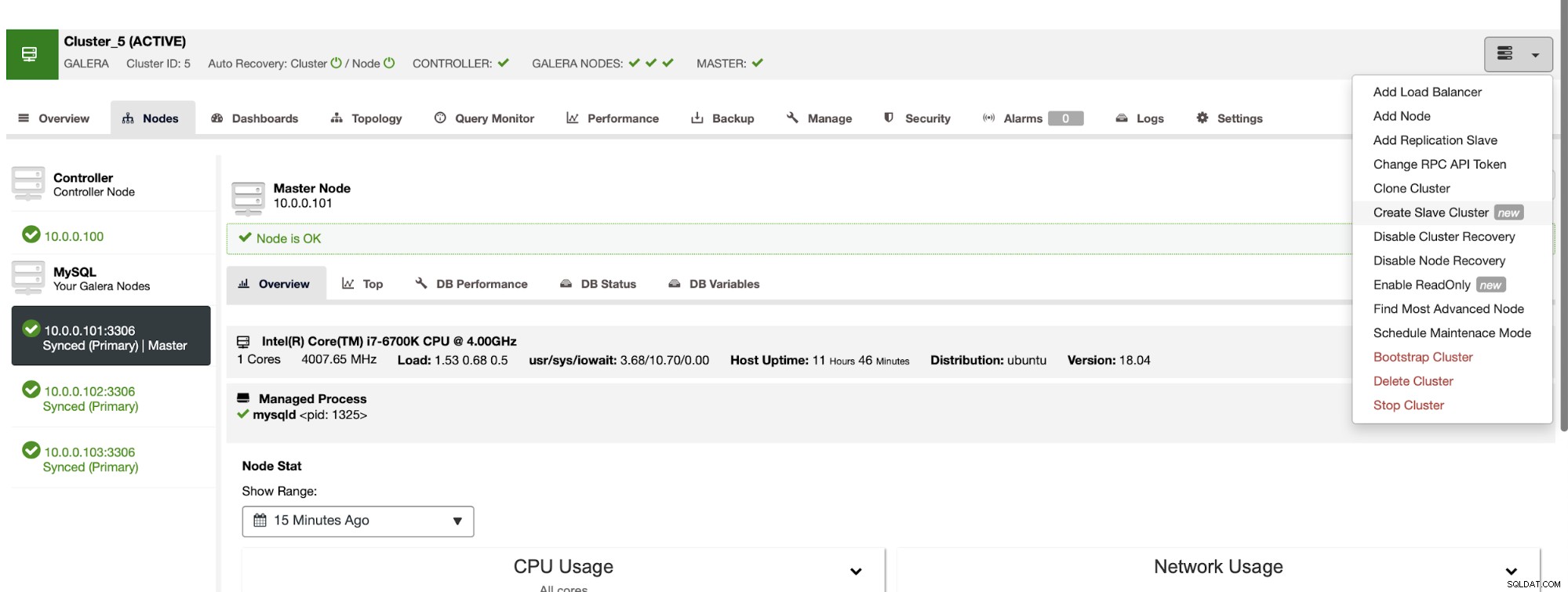
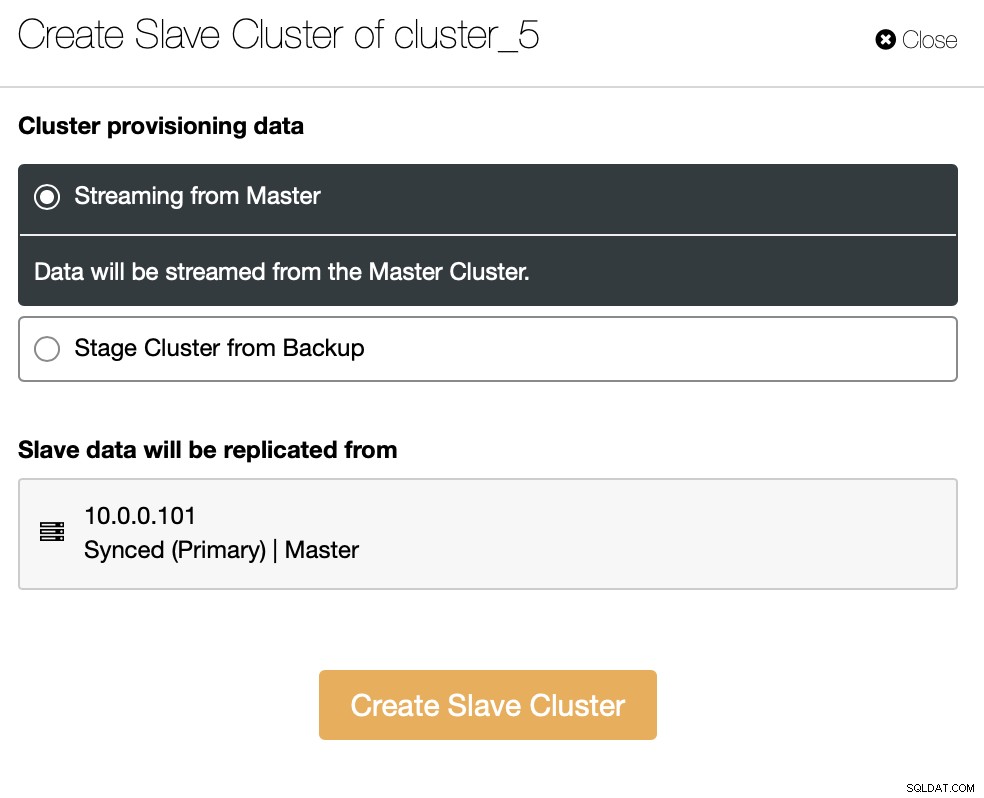
Możemy przesyłać dane bezpośrednio z mastera lub możesz użyć jednego kopii zapasowych w celu udostępnienia danych.
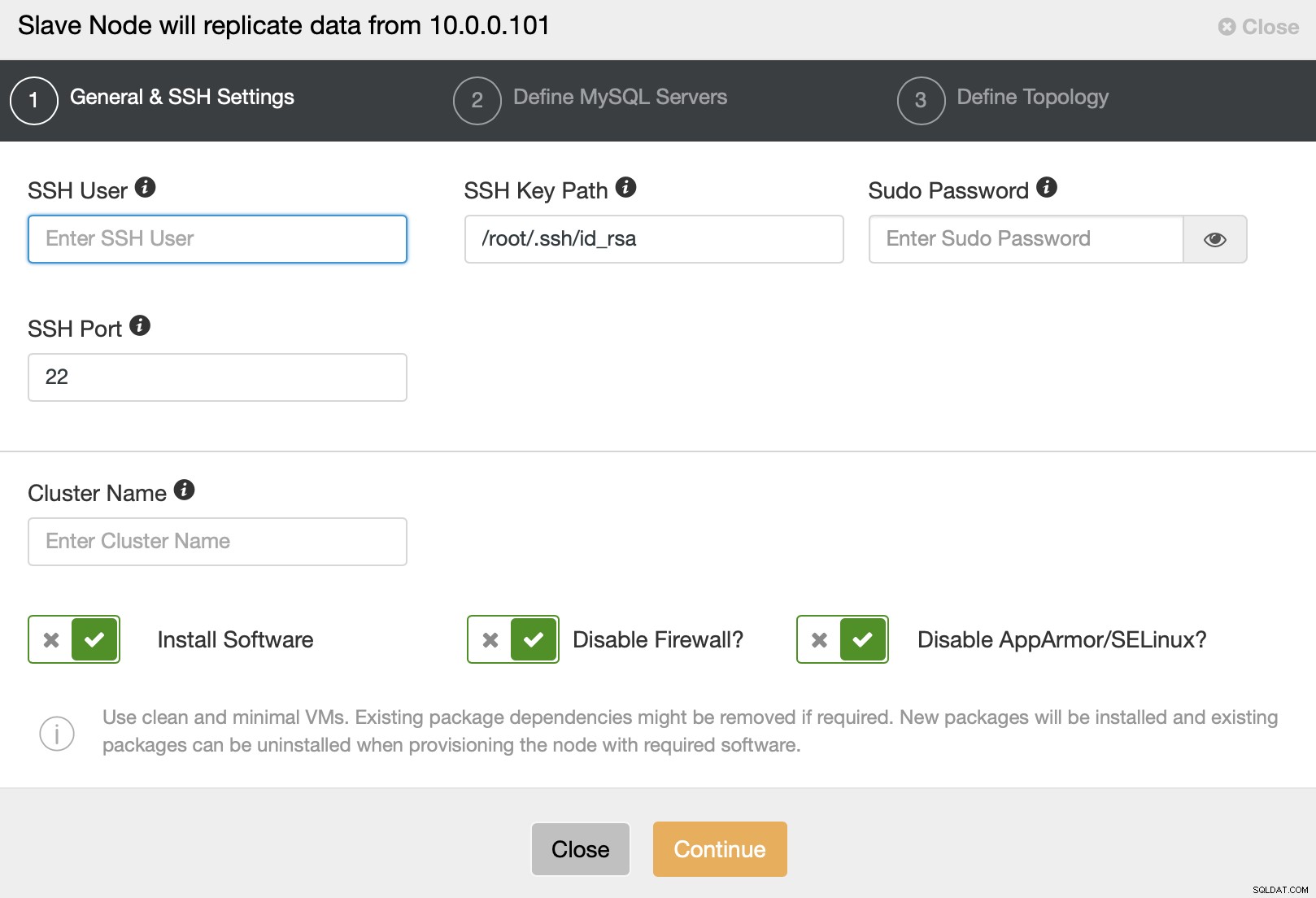
Następnie pojawia się standardowy kreator wdrażania klastra, do którego należy przejść Szczegóły połączenia SSH.
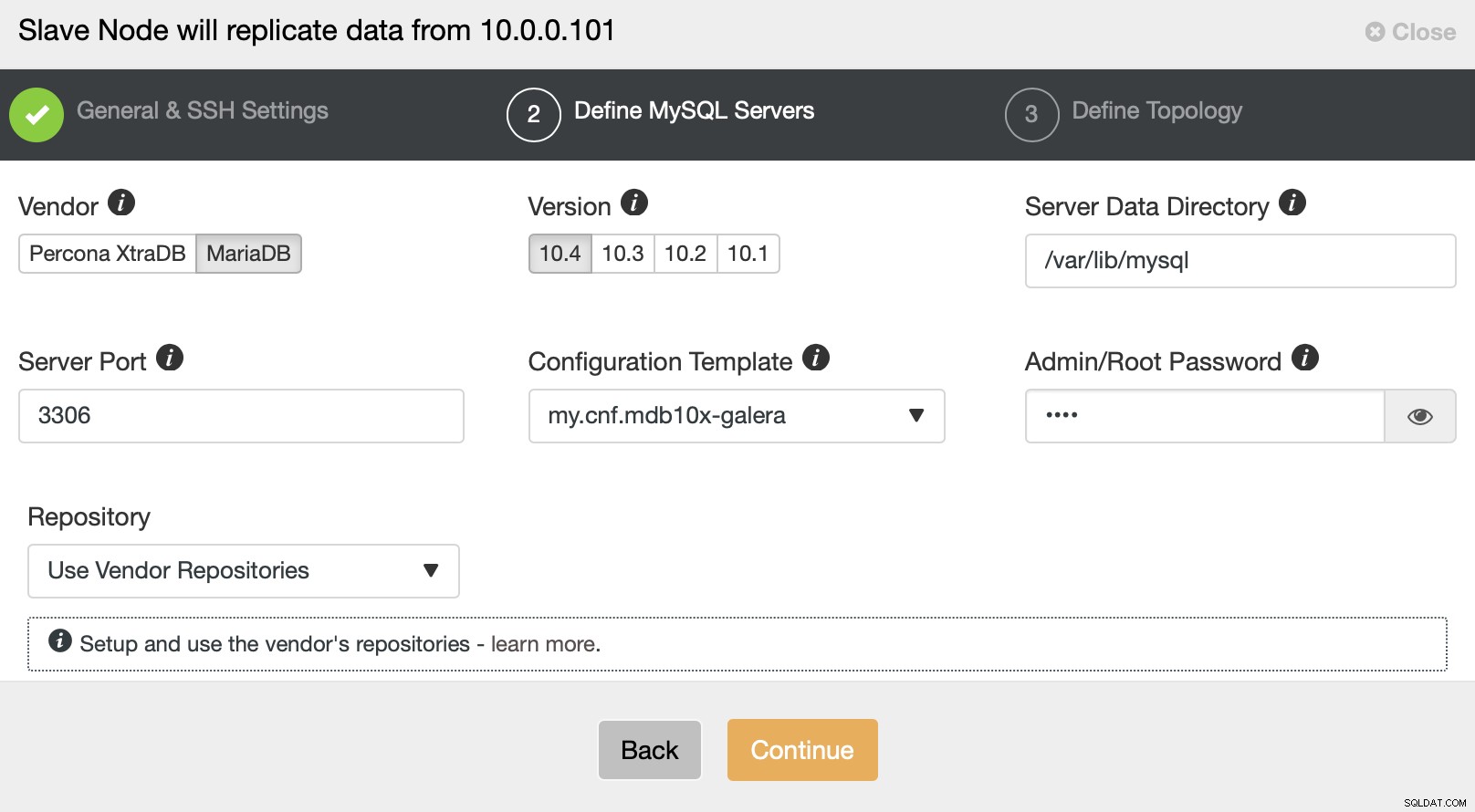
Zostaniesz również poproszony o wybranie dostawcy i wersji baz danych zapytany o hasło dla użytkownika root.
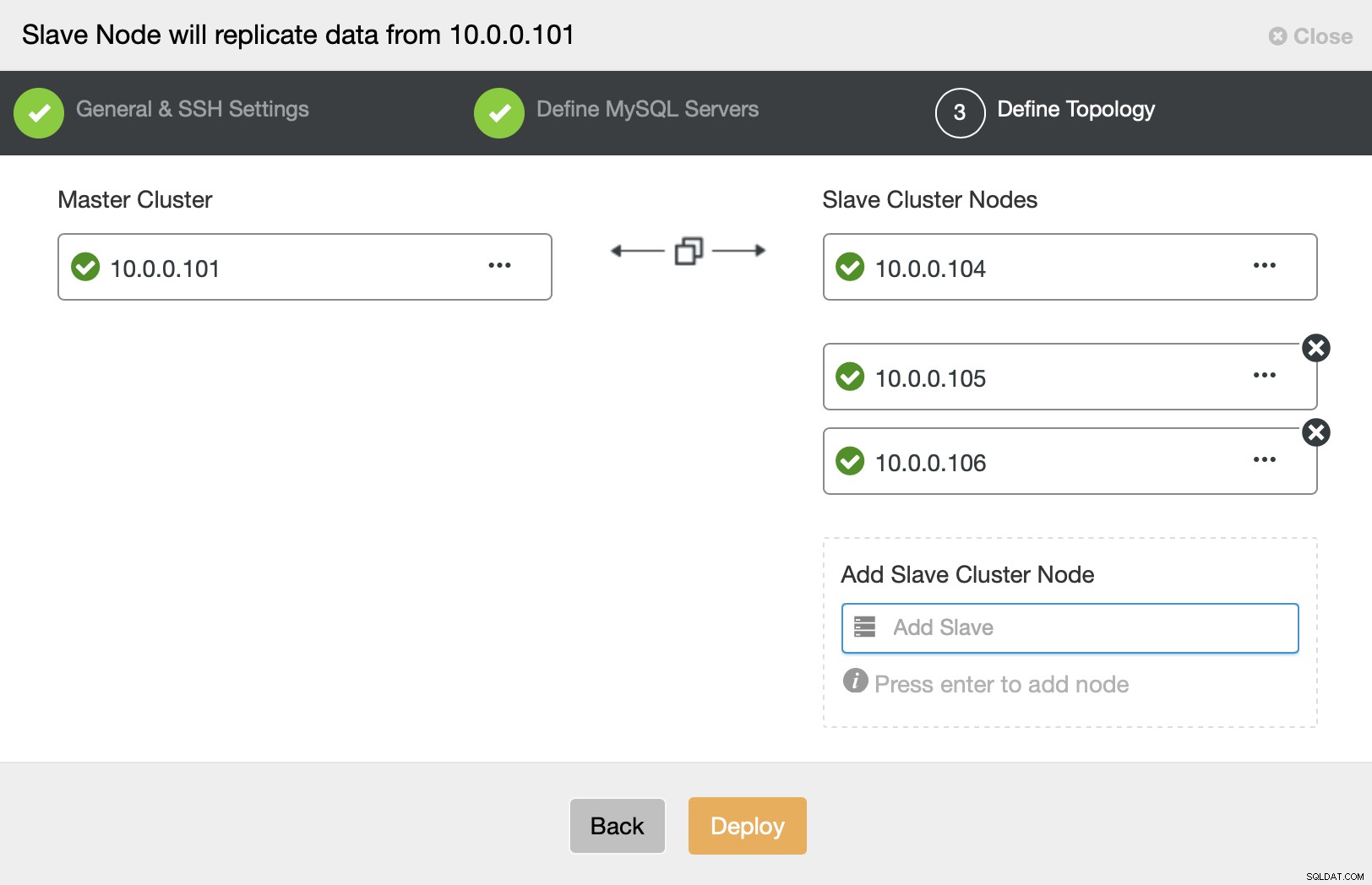
Na koniec zostaniesz poproszony o zdefiniowanie węzłów, które chcesz dodać do klaster i wszystko gotowe.
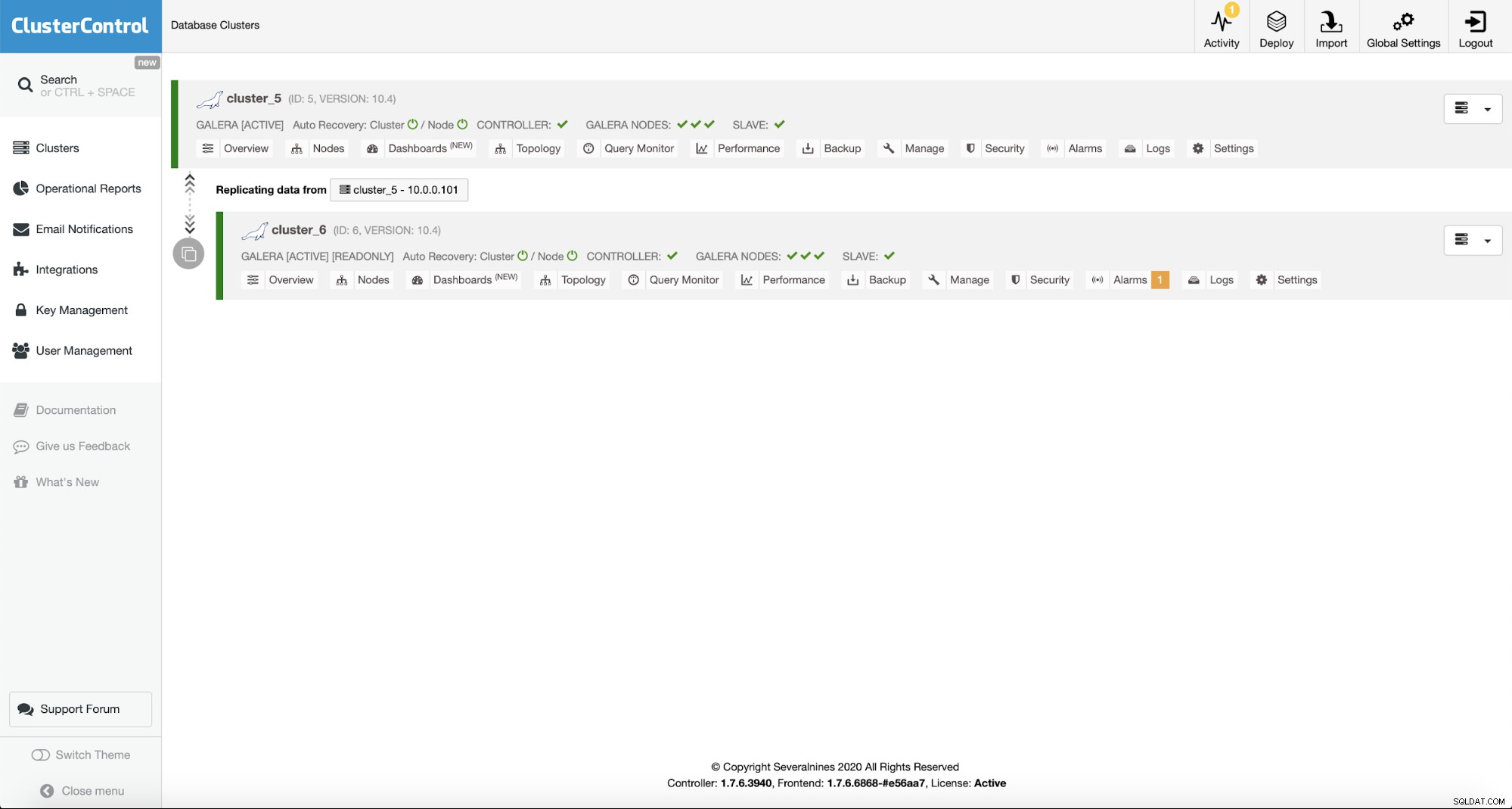
Po wdrożeniu zobaczysz go na liście klastrów w Interfejs użytkownika ClusterControl.
Wdrażanie klastra Multi-Cloud MariaDB
Jak wspomnieliśmy wcześniej, inną opcją wdrożenia klastra MariaDB byłoby użycie oddzielnych segmentów podczas dodawania węzłów do klastra. W interfejsie użytkownika ClusterControl znajdziesz opcję „Dodaj węzeł”:
Gdy go użyjesz, zobaczysz następujący ekran:
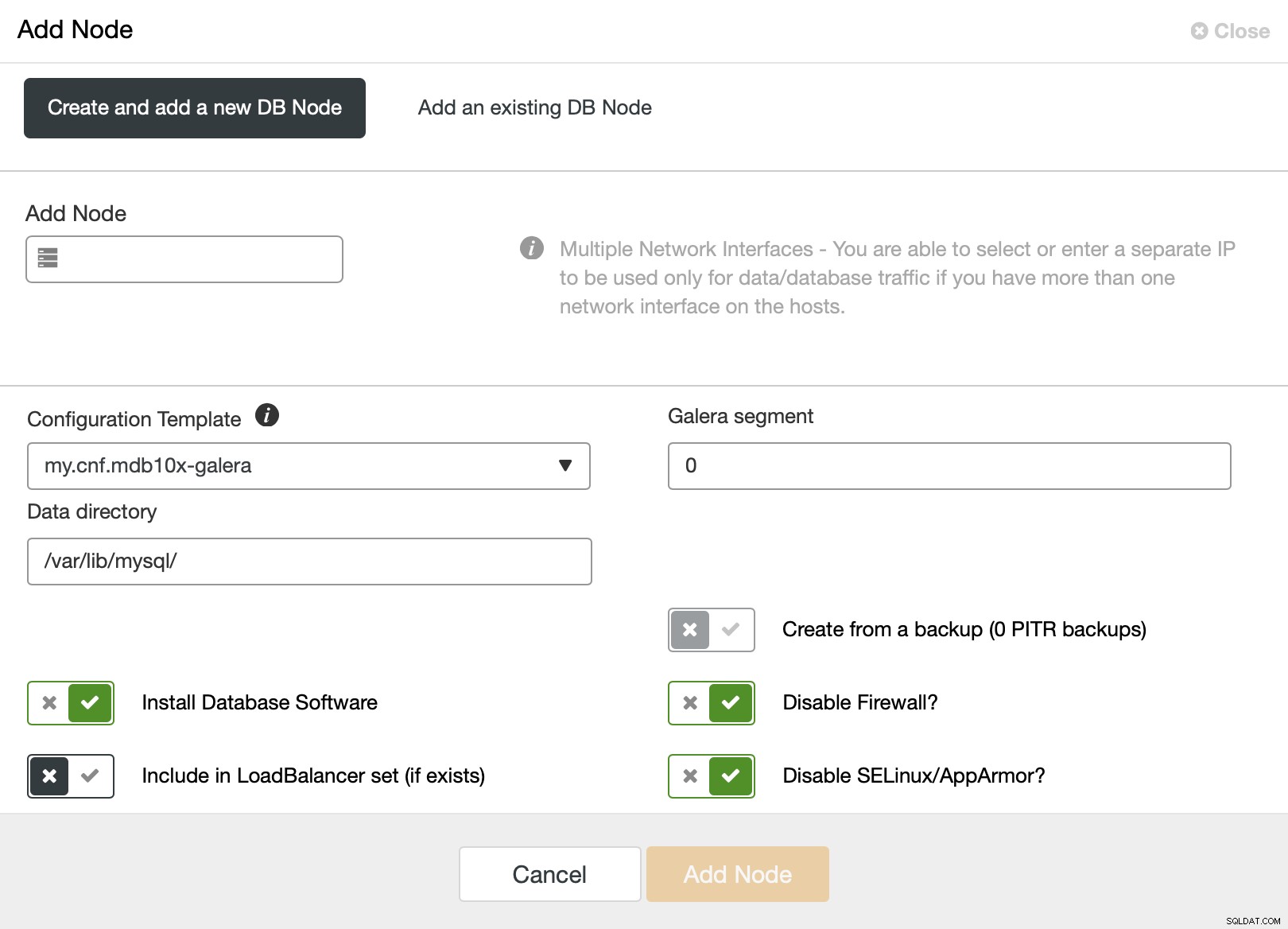
Domyślny segment to 0, więc chcesz go zmienić na inną wartość .
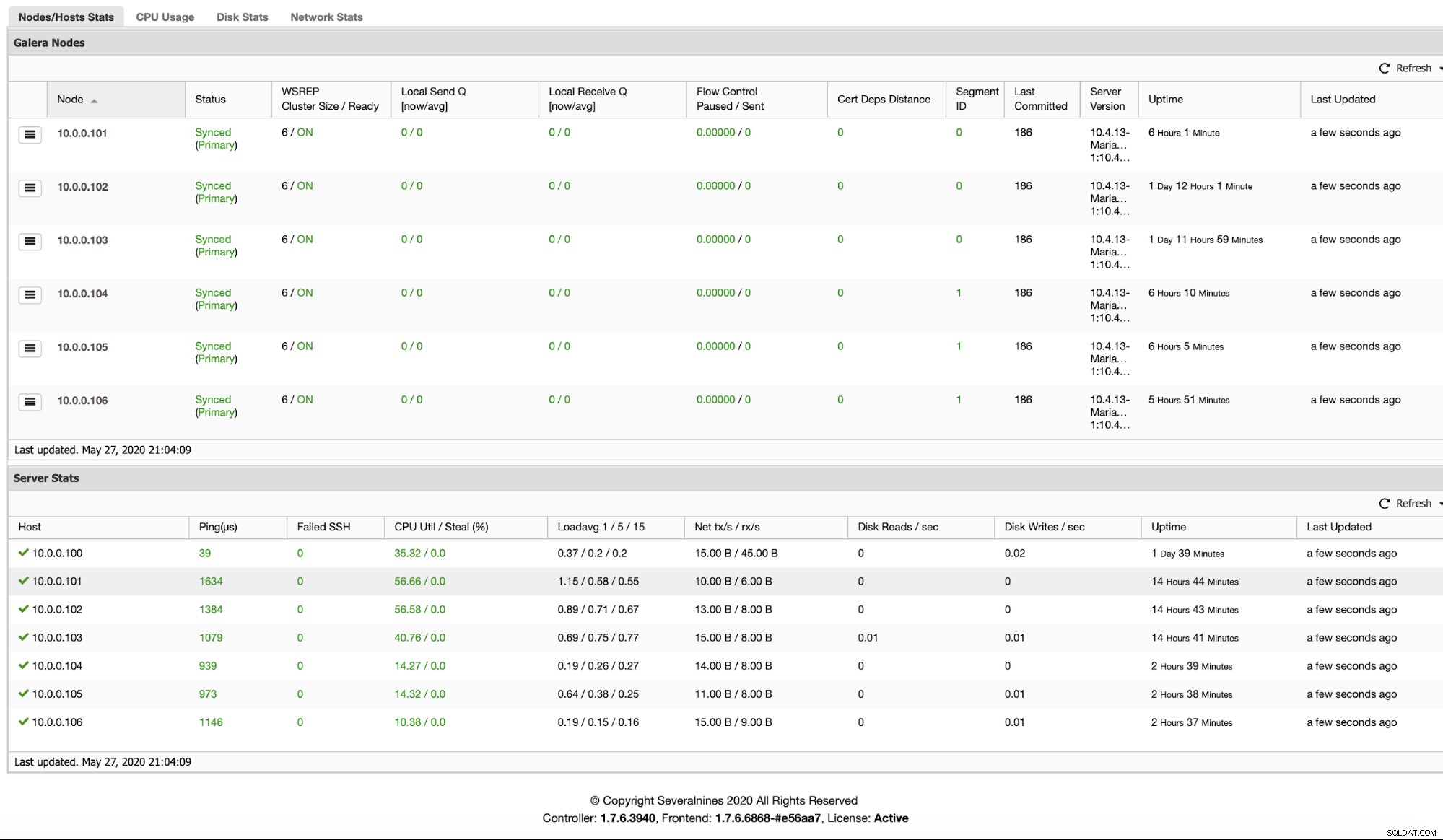
Po dodaniu węzłów możesz sprawdzić, w którym segmencie się znajdują, patrząc na kartę Przegląd:
Wnioski
Mamy nadzieję, że ten krótki blog umożliwił lepsze zrozumienie dostępnych opcji wdrożeń klastra MariaDB w wielu chmurach oraz sposobów ich wykorzystania w celu zapewnienia wysokiej dostępności infrastruktury bazy danych.