Prowadzenie klastra Galera w chmurze hybrydowej powinno składać się z co najmniej dwóch różnych lokalizacji geograficznych, łączących hosty w chmurze lokalnej lub prywatnej z tymi w chmurze publicznej. Niezależnie od tego, czy korzystasz z niezniszczalnych chmur prywatnych, czy chmur publicznych, odzyskiwanie po awarii (DR) jest rzeczywiście kluczową kwestią. Nie chodzi o kopiowanie danych do lokalizacji kopii zapasowej i możliwość ich przywrócenia, chodzi o ciągłość biznesową i o to, jak szybko można odzyskać usługi w przypadku awarii.
W tym poście na blogu przyjrzymy się różnym sposobom projektowania klastrów Galera pod kątem odporności na awarie w środowisku chmury hybrydowej.
Aktywna-aktywna konfiguracja
Galera Cluster powinien działać z nieparzystą liczbą węzłów w klastrze i zwykle zaczyna się od 3 węzłów. Dzieje się tak, ponieważ Galera Cluster używa kworum do automatycznego określania podstawowego komponentu, w którym większość połączonych węzłów powinna być w stanie obsłużyć klaster jednocześnie, w przypadku partycjonowania klastra.
W przypadku konfiguracji chmury hybrydowej typu aktywna-aktywna, Galera wymaga co najmniej 3 różnych lokalizacji, tworząc klaster Galera w sieci WAN. Ogólnie rzecz biorąc, potrzebna jest trzecia witryna, która będzie działać jako arbiter, głosując za kworum i zachowując „podstawowy element”, jeśli którakolwiek z witryn jest niedostępna. Można to skonfigurować jako co najmniej 3-węzłowy klaster w 3 różnych lokacjach (1 węzeł na lokację), podobnie jak na poniższym diagramie:
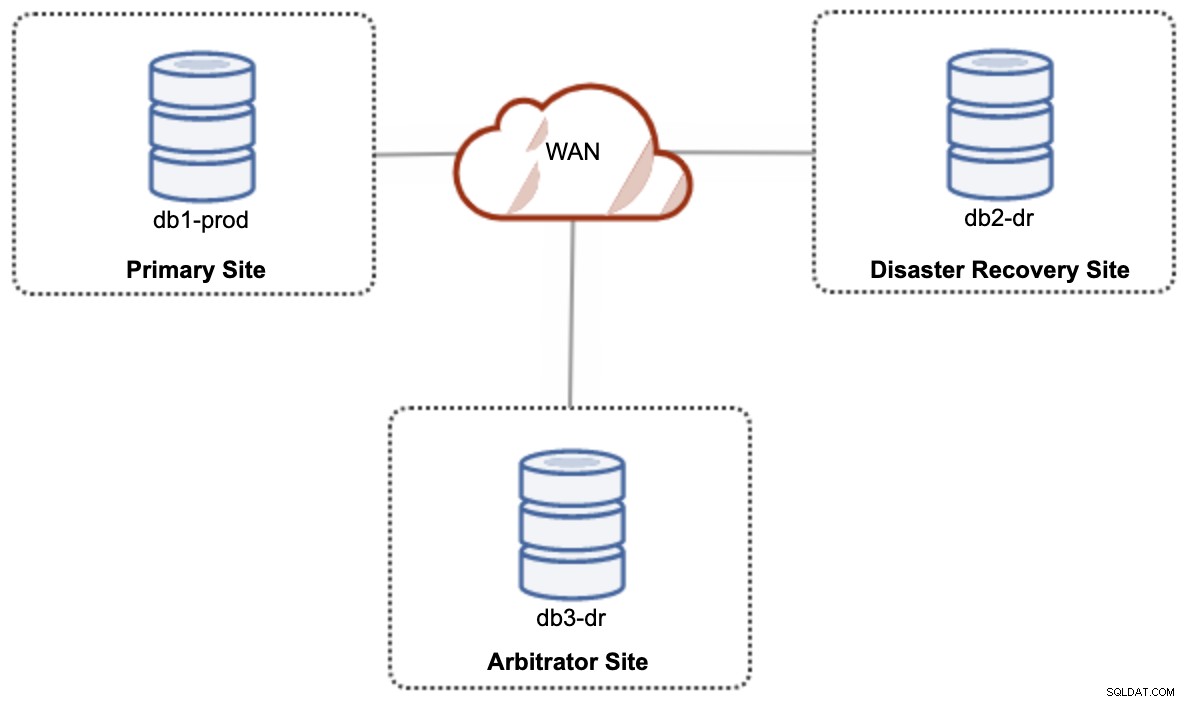
Jednak ze względu na wydajność i niezawodność zaleca się posiadanie 7 - klaster węzłów, jak pokazano na poniższym diagramie:
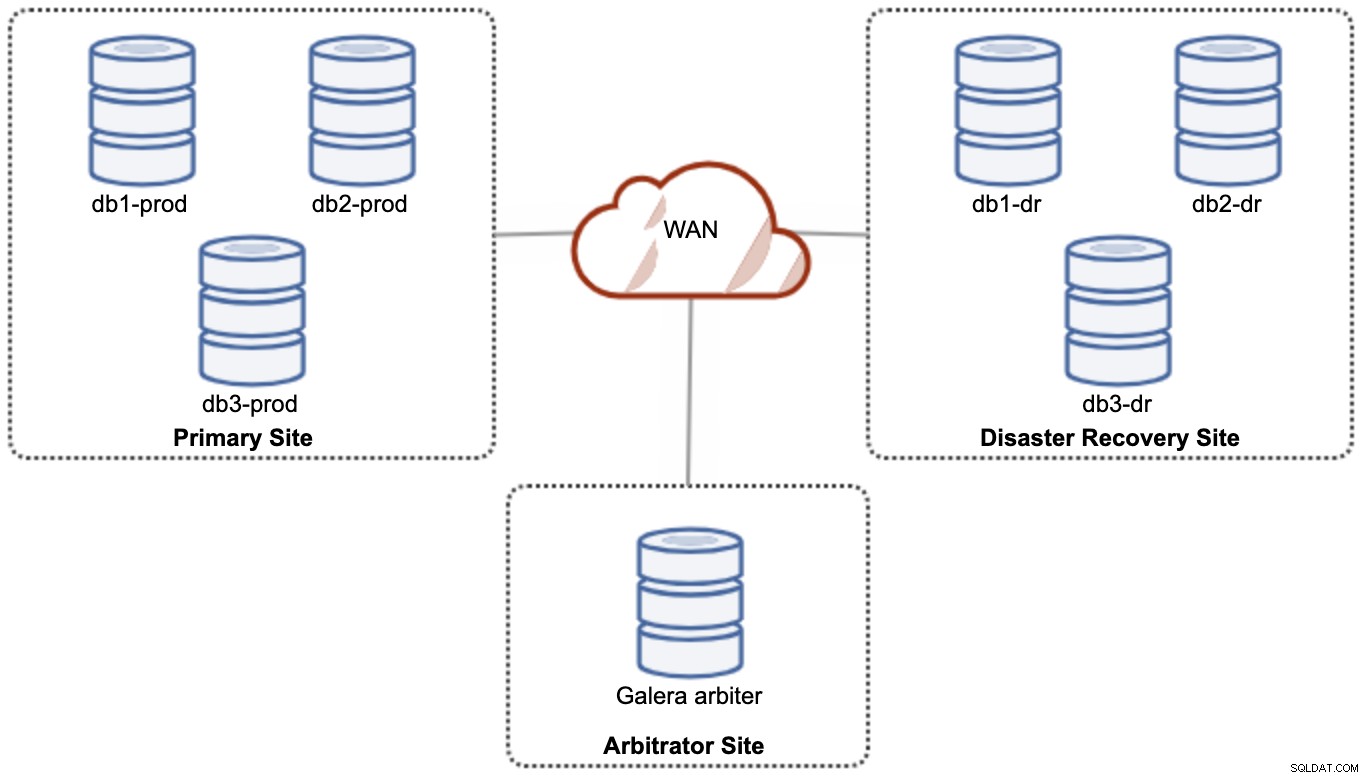
Uznaje się, że jest to najlepsza topologia do obsługi konfiguracji aktywny-aktywny, w której strona DR powinna być dostępna niemal natychmiast, bez jakiejkolwiek interwencji. Obie witryny mogą odbierać odczyty/zapisy w dowolnym momencie, pod warunkiem, że klaster znajduje się w kworum.
Jednak posiadanie 3 witryn i 7 węzłów bazy danych jest bardzo kosztowne (siódmy węzeł można zastąpić garbd, ponieważ jest bardzo mało prawdopodobne, aby służył do obsługi danych klientom/aplikacjom). To zwykle nie jest popularne wdrożenie na początku projektu ze względu na ogromne koszty początkowe i wrażliwość komunikacji grupy Galera i replikacji na opóźnienia w sieci.
Konfiguracja aktywna-pasywna
W konfiguracji aktywna-pasywna wymagane są co najmniej 2 lokacje i tylko jedna lokacja jest aktywna w danym momencie, zwana lokacją główną, a węzły w lokacji dodatkowej replikują tylko dane pochodzące z lokacji głównej serwer/klaster. W przypadku Galera Cluster możemy użyć replikacji asynchronicznej MySQL (replikacja master-slave) lub możemy również użyć replikacji wirtualnie synchronicznej Galera z pewnym dostrojeniem, aby stonować replikację zbioru zapisów, aby działała jako replikacja asynchroniczna.
Lokalizacja dodatkowa musi być chroniona przed przypadkowymi zapisami za pomocą flagi tylko do odczytu, zapory aplikacji, zwrotnego serwera proxy lub innych środków, ponieważ przepływ danych zawsze pochodzi z witryny głównej do dodatkowej, chyba że przełączenie awaryjne zainicjowało i promowało lokację dodatkową jako główną.
Korzystanie z replikacji asynchronicznej
Dobrą rzeczą w replikacji asynchronicznej jest to, że replikacja nie wpływa na serwer/klaster źródłowy, ale może pozostawać w tyle za masterem. Taka konfiguracja sprawi, że główna i DR będą niezależne od siebie, luźno połączone z replikacją asynchroniczną. Można to skonfigurować jako co najmniej 4-węzłowy klaster w 2 różnych lokacjach, podobnie jak na poniższym diagramie:
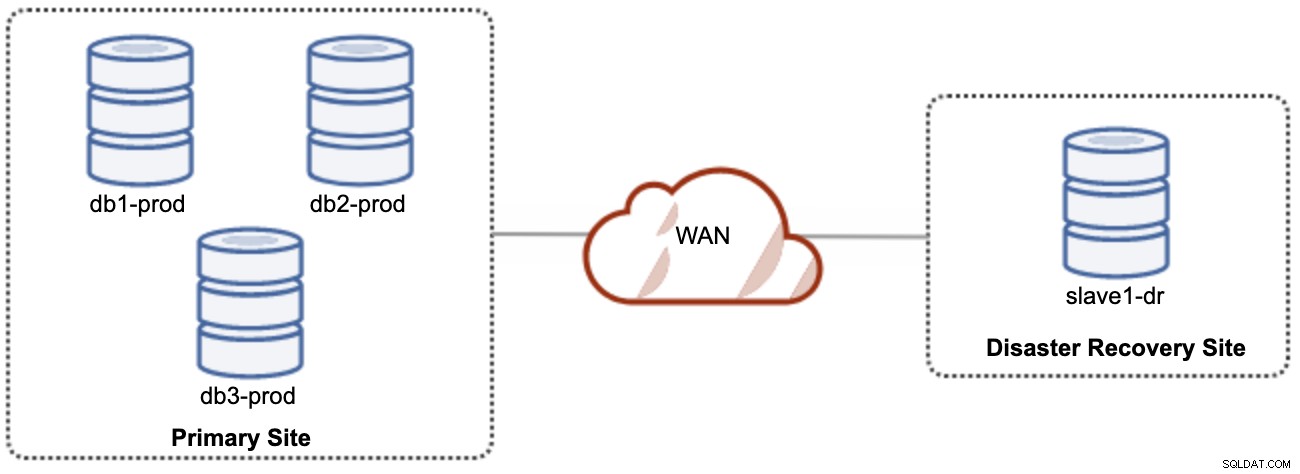
Jeden z węzłów Galera w witrynie DR będzie serwerem podrzędnym, który replikuje się z jednego z węzłów Galera (głównego) w witrynie głównej. Obie lokacje muszą generować dzienniki binarne z identyfikatorem GTID i włączonymi funkcjami log_slave_updates — aktualizacje pochodzące ze strumienia replikacji asynchronicznej zostaną zastosowane do innych węzłów w klastrze. Jednak do użytku produkcyjnego zalecamy posiadanie dwóch zestawów klastrów w obu witrynach, jak pokazano na poniższym diagramie:
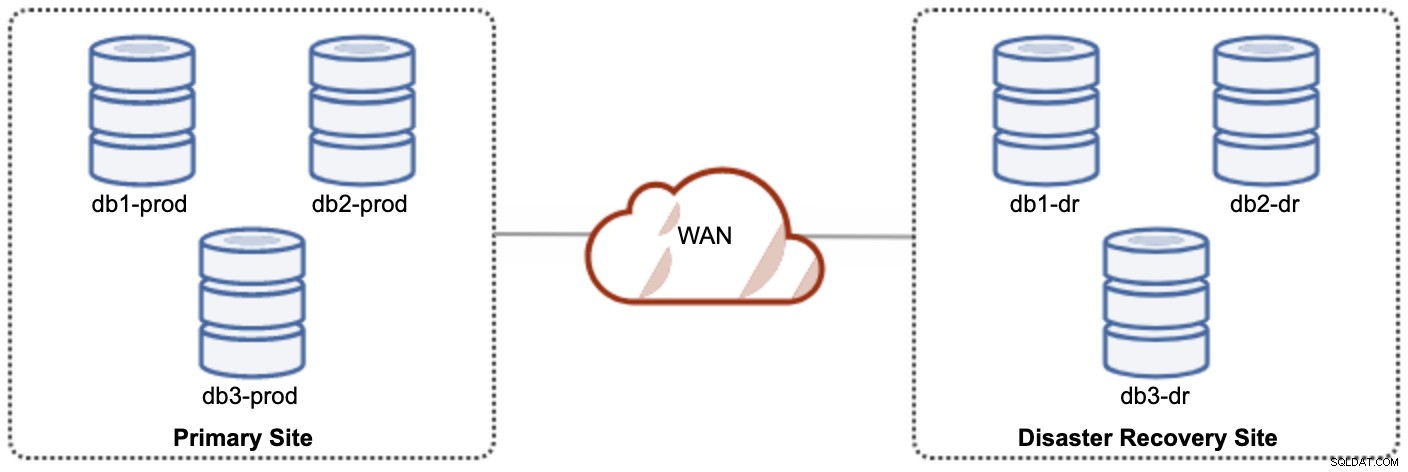
Dzięki posiadaniu dwóch oddzielnych klastrów będą one luźno połączone i nie będą na siebie oddziaływać, np. awaria klastra w lokacji głównej nie wpłynie na lokację DR. Pod względem wydajności opóźnienie WAN nie wpłynie na aktualizacje w aktywnym klastrze. Są one wysyłane asynchronicznie do witryny kopii zapasowej. Klaster DR może potencjalnie działać na mniejszych instancjach w środowisku chmury publicznej, o ile nadąża za klastrem podstawowym. W razie potrzeby instancje można uaktualnić. Aplikacje powinny wysyłać zapisy do lokacji głównej, a lokacja dodatkowa musi być ustawiona do uruchamiania w trybie tylko do odczytu. Witryna odzyskiwania po awarii może być używana do innych celów, takich jak tworzenie kopii zapasowych bazy danych, tworzenie kopii zapasowych dzienników binarnych oraz raportowanie lub przetwarzanie zapytań analitycznych (OLAP).
Z drugiej strony istnieje ryzyko utraty danych podczas przełączania awaryjnego, jeśli urządzenie podrzędne jest opóźnione. Dlatego zaleca się włączenie replikacji półsynchronicznej, aby zmniejszyć ryzyko utraty danych. Należy zauważyć, że korzystanie z replikacji półsynchronicznej nadal nie zapewnia silnych gwarancji przed utratą danych w porównaniu z replikacją wirtualnie synchroniczną Galera. Przeczytaj uważnie ten podręcznik MySQL, na przykład następujące zdania:
"W przypadku replikacji półsynchronicznej, jeśli źródło ulegnie awarii i nastąpi przełączenie awaryjne na replikę, uszkodzone źródło nie powinno zostać ponownie użyte jako źródło replikacji i powinno zostać odrzucone. Może zawierać transakcje, które zostały niepotwierdzone przez żadną replikę, które w związku z tym nie zostały zatwierdzone przed przełączeniem awaryjnym."
Proces przełączania awaryjnego jest dość prosty. Aby promować witrynę odzyskiwania po awarii, po prostu wyłącz flagę tylko do odczytu i rozpocznij kierowanie aplikacji do węzłów bazy danych w witrynie DR. Strategia rezerwowa jest jednak nieco trudna i wymaga pewnej wiedzy w zakresie umieszczania danych w obu witrynach, przełączania roli master/slave w klastrze i przekierowywania przepływu replikacji slave w przeciwnym kierunku.
Korzystanie z replikacji Galera
W przypadku konfiguracji aktywny-pasywny możemy umieścić większość węzłów zlokalizowanych w lokacji podstawowej, podczas gdy mniejszość węzłów zlokalizowanych w lokacji odzyskiwania po awarii, jak pokazano na poniższym zrzucie ekranu dla 3- węzeł Klaster Galera:
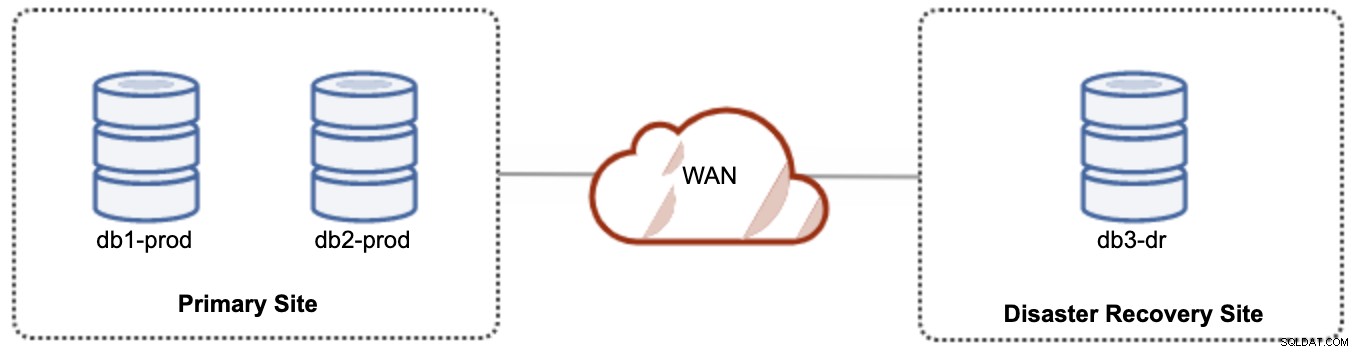
Jeśli główna lokacja nie działa, klaster ulegnie awarii, ponieważ nie ma kworum. Węzeł Galera w lokacji odzyskiwania po awarii (db3-dr) będzie musiał zostać załadowany ręcznie jako komponent podstawowy z jednym węzłem. Po utworzeniu kopii zapasowej lokacji głównej oba węzły w lokacji głównej (db1-prod i db2-prod) muszą ponownie dołączyć do galera3, aby uzyskać synchronizację. Posiadanie dość dużej pamięci podręcznej gcache powinno pomóc zmniejszyć ryzyko SST przez WAN. Ta architektura jest łatwa w konfiguracji i administrowaniu oraz bardzo opłacalna.
Przełączanie awaryjne jest ręczne, ponieważ administrator musi promować pojedynczy węzeł jako główny komponent (bootstrap db3-dr lub użyj set pc.bootstrap=1 w parametrze wsrep_provider_options. W międzyczasie nastąpi przestój .Wydajność może stanowić problem, ponieważ witryna DR będzie działać z mniejszą liczbą węzłów (ponieważ witryna DR jest zawsze w mniejszości), aby uruchomić całe obciążenie. Po przełączeniu na Witryna DR, ale uważaj na dodatkowe obciążenie.
Zauważ, że Galera Cluster jest wrażliwy na sieć ze względu na jej praktycznie synchroniczną naturę. Im dalej węzły Galera znajdują się w danym klastrze, tym większe opóźnienie i zdolność zapisu do dystrybucji i certyfikacji zestawów zapisu. Ponadto, jeśli łączność nie jest stabilna, łatwo może dojść do partycjonowania klastra, co może wyzwolić synchronizację klastra w węzłach dołączających. W niektórych przypadkach może to spowodować niestabilność klastra. Wymaga to trochę dostrojenia parametrów Galera, jak pokazano w tym poście na blogu, Wdrażanie środowiska infrastruktury hybrydowej dla klastra Percona XtraDB.
Ostateczne myśli
Galera Cluster to świetna technologia, którą można wdrożyć na różne sposoby — jeden klaster rozciągnięty na wiele lokalizacji, wiele klastrów utrzymywanych zsynchronizowanych dzięki replikacji asynchronicznej, połączenie replikacji synchronicznej i asynchronicznej i tak dalej. Rzeczywiste rozwiązanie będzie podyktowane takimi czynnikami, jak opóźnienie sieci WAN, ewentualna kontra duża spójność danych i budżet.



