W tym samouczku Hadoop , mamy zamiar zapewnić Państwu pełne wprowadzenie do Federacji HDFS. W tym samouczku omówimy architekturę HDFS, ograniczenia obecnej architektury HDFS.
Następnie szczegółowo omówimy architekturę HDFS Federation wraz z jej zaletami w ramach Hadoop.
Co to jest Federacja HDFS?
Federacja ulepsza istniejący Hadoop HDFS architektura. Wcześniejsza architektura HDFS umożliwia korzystanie z jednej przestrzeni nazw dla całego klastra. W tej architekturze pojedynczy NameNode zarządza przestrzenią nazw.
Jeśli NameNode ulegnie awarii, cały klaster przestanie działać. A klaster będzie niedostępny, dopóki NameNode nie zostanie ponownie uruchomiony lub przeniesiony na osobną maszynę.
Federacja HDFS została wprowadzona w celu przezwyciężenia tego ograniczenia. Pokonuje to, dodając obsługę wielu NameNode/Namespaces do HDFS.
Obecna architektura HDFS
HDFS ma dwie główne warstwy podane poniżej:
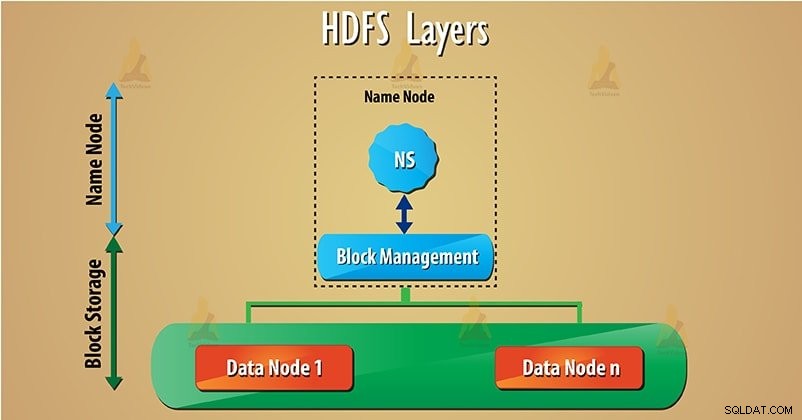
a) Przestrzeń nazw – Ta warstwa zarządza plikami, katalogami i blokami . Ta warstwa obsługuje podstawowe operacje systemu plików, takie jak tworzenie, usuwanie plików.
b) Zablokuj pamięć – Składa się z dwóch części-
- Zarządzanie blokami – Obsługuje operacje związane z blokami, takie jak tworzenie, usuwanie bloków. Zarządza węzłami danych w klastrze i zajmuje się zarządzaniem replikacją.
- Przechowywanie fizyczne – To przechowuje bloki w lokalnym systemie plików i zapewnia dostęp do operacji odczytu lub zapisu. Kliknij ten link, aby dowiedzieć się, jak czytać i zapisywać dane HDFS.
Ten obecny system HDFS działa dobrze w mniejszych konfiguracjach. Jednak w przypadku dużych organizacji, w których musimy zadbać o ogromną ilość danych, ma to pewne ograniczenia. Federacja Hadoop radzi sobie z tymi ograniczeniami.
Ograniczenia obecnej architektury HDFS
Ograniczenia obecnej architektury HDFS podano poniżej:
1. Ściśle powiązane przechowywanie bloków i przestrzeń nazw
Warstwa przestrzeni nazw i warstwa pamięci są ściśle powiązane. To sprawia, że alternatywna implementacja namenode jest trudna. I ogranicza inne usługi do korzystania z pamięci blokowej.
2. Skalowalność przestrzeni nazw
Przestrzeń nazw nie jest skalowalna jak datanode. Skalowanie w klastrze HDFS odbywa się w poziomie poprzez dodawanie węzłów danych. Ale nie możemy dodać więcej przestrzeni nazw do istniejącego klastra. Możemy pionowo skalować przestrzeń nazw na pojedynczym węźle nazw.
3. Wydajność
Cała wydajność usługi Hadoop zależy od przepustowości nazwy węzła. Działanie bieżącego systemu plików zależy od przepustowości pojedynczego węzła nazw. NameNode obsługuje obecnie 60 000 jednoczesnych zadań.
Nadchodzące MapReduce będzie obsługiwać ponad 100 000 jednoczesnych zadań. A to będzie wymagało więcej nazw.
4. Izolacja
Nie ma separacji przestrzeni nazw. Dzięki temu nie ma izolacji między organizacją najemców korzystającą z klastra.
HDFSArchitektura federacyjna
Federacja używa wielu niezależnych Namenode/przestrzeni nazw do skalowania usługi nazw w poziomie. W architekturze Federacji HDFS na dole znajdują się węzły danych. A węzły danych są używane jako wspólne miejsce przechowywania bloków przez wszystkie węzły nazw.
Każdy datanodes rejestruje się ze wszystkimi nazwami w klastrze. Te węzły danych wysyłają okresowe uderzenia serca, blokują, raportują i obsługują polecenia z węzłów nazw.
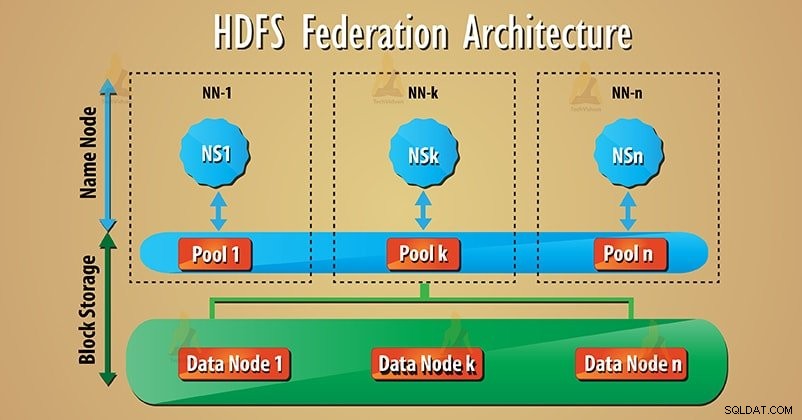
Wiele nazw (NN1, NN2…, NNn) zarządza odpowiednio wieloma przestrzeniami nazw (NS1, NS2…, NSn). Każda przestrzeń nazw ma własną pulę bloków (NS1 ma pulę 1 itd.). Blok z puli 1 jest przechowywany w węźle danych 1 i tak dalej.
1. Blokuj pulę
Zestaw bloków to Pula bloków należący do pojedynczej przestrzeni nazw. Istnieje zbiór pul w architekturze federacyjnej HDFS. A każdy blok jest zarządzany z drugiego.
Dzięki temu przestrzeń nazw może utworzyć identyfikator bloku dla nowych bloków bez koordynacji z inną przestrzenią nazw. Wszystkie Datanodes przechowują bloki danych obecne we wszystkich pulach bloków.
2. Wolumen przestrzeni nazw
Przestrzeń nazw wraz z jej pulą bloków to Wolumen przestrzeni nazw . W federacji HDFS znajduje się wiele woluminów przestrzeni nazw. Dlatego każdy wolumin przestrzeni nazw działa niezależnie. Kiedy usuniemy nazwę węzła lub przestrzeń nazw, odpowiednia pula bloków obecna w węzłach danych również zostanie usunięta.
Korzyści Federacji HDFS
Federacja HDFS pokonuje ograniczenia wcześniejszej architektury HDFS. Dlatego zapewnia:
- Izolacja – Nie ma izolacji w pojedynczym węźle nazwy w środowisku wielu użytkowników. W federacji HDFS różne kategorie aplikacji i użytkowników można odizolować od różnych przestrzeni nazw przy użyciu wielu nazw węzłów.
- Skalowalność przestrzeni nazw – W federacji wiele nazw węzłów skaluje się poziomo w przestrzeni nazw systemu plików.
- Wydajność – Możemy poprawić przepustowość operacji odczytu/zapisu, dodając więcej nazw.
Wniosek
Podsumowując Federację HDFS, możemy powiedzieć, że przezwycięża ograniczenia jednowęzłowej architektury HDFS. W poprzedniej architekturze HDFS dla całego klastra dopuszcza się tylko jedną przestrzeń nazw. Podczas gdy Federacja używa wielu niezależnych nazw Namenode/przestrzeni nazw do skalowania usługi nazw w poziomie.
Oddziela również warstwę przestrzeni nazw i pamięć warstwa. Dlatego zapewnia izolację, skalowalność i prostą konstrukcję.
Jeśli masz jakiekolwiek pytania lub sugestie związane z Federacją w Hadoop HDFS, daj nam znać, zostawiając komentarz.



