Główny cel tegoSamouczka Hadoop jest dostarczenie szczegółowego opisu każdego komponentu używanego w działaniu Hadoop. W tym samouczku omówimy partycjonowanie w Hadoop.
Co to jest Partitioner Hadoop, jakie są potrzeby Partitioner w Hadoop, Jaki jest domyślny Partitioner w MapReduce, Ile MapReduce Partitioner jest używanych w Hadoop?
Na wszystkie te pytania odpowiemy w tym samouczku MapReduce.
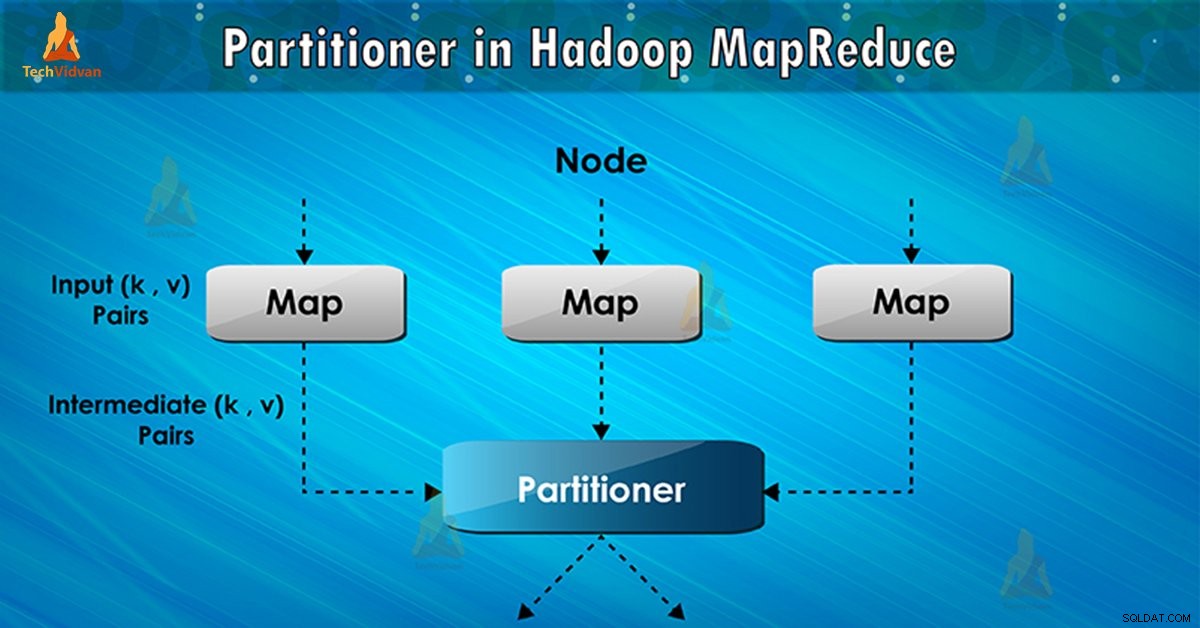
Co to jest partycjonowanie Hadoop?
Partycjonowanie w wykonaniu zadania MapReduce steruje partycjonowaniem kluczy pośrednich danych wyjściowych mapy. Za pomocą funkcji skrótu klucz (lub podzbiór klucza) wyprowadza partycję. Całkowita liczba partycji jest równa liczbie zadań redukcji.
Na podstawie wartości klucza , partycje frameworka, każdy mapujący wyjście. Rekordy mające tę samą wartość klucza trafiają do tej samej partycji (w ramach każdego programu mapującego). Następnie każda partycja jest wysyłana do reduktora .
Klasa partycji decyduje o tym, do której partycji trafi dana para (klucz, wartość). Faza partycji w przepływie danych MapReduce ma miejsce po fazie mapy i przed fazą redukcji.
Potrzeba partycji MapReduce w Hadoop
Podczas wykonywania zadania MapReduce pobiera zestaw danych wejściowych i tworzy listę par klucz-wartość. Ta para klucz-wartość jest wynikiem fazy mapy. W którym dane wejściowe są dzielone, a każde zadanie przetwarza podział i każdą mapę, wyświetla listę par klucz-wartość.
Następnie framework wysyła dane wyjściowe mapy w celu zmniejszenia zadania. Redukcja procesów zdefiniowana przez użytkownika funkcja zmniejszania danych wyjściowych mapy. Przed fazą redukcji podział wyjścia mapy odbywa się na podstawie klucza.
Partycjonowanie Hadoop określa, że wszystkie wartości dla każdego klucza są zgrupowane razem. Zapewnia również, że wszystkie wartości jednego klucza trafiają do tego samego reduktora. Pozwala to na równomierne rozłożenie danych wyjściowych mapy na reduktor.
Partitioner w zadaniu MapReduce przekierowuje dane wyjściowe programu mapującego do reduktora poprzez określenie, który reduktor obsługuje dany klucz.
Domyślny partycjonowanie Hadoop
Hash Partitioner jest domyślnym partycjonatorem. Oblicza wartość skrótu klucza. Przypisuje również partycję na podstawie tego wyniku.
Ile partycji w Hadoop?
Całkowita liczba partycji zależy od liczby reduktorów. Hadoop Partitioner dzieli dane według liczby reduktorów. Jest ustawiany przez JobConf.setNumReduceTasks() metoda.
W ten sposób pojedynczy reduktor przetwarza dane z jednego partycji. Należy zauważyć, że framework tworzy partycje tylko wtedy, gdy istnieje wiele reduktorów.
Słabe partycjonowanie w Hadoop MapReduce
Jeśli podczas wprowadzania danych w zadaniu MapReduce jeden klucz pojawia się częściej niż jakikolwiek inny. W takim przypadku do przesłania danych na partycję wykorzystujemy dwa mechanizmy, które są następujące:
- Klucz, który pojawia się więcej razy, zostanie wysłany do jednej partycji.
- Wszystkie pozostałe klucze zostaną wysłane do partycji na podstawie ich hashCode() .
Jeśli hashCode() Metoda nie dystrybuuje innych kluczowych danych w zakresie partycji. Wtedy dane nie będą wysyłane do reduktorów.
Słabe partycjonowanie danych oznacza, że niektóre reduktory będą miały więcej danych wejściowych niż inne. Będą mieli więcej pracy niż inne reduktory. W ten sposób cała praca musi czekać, aż jeden reduktor zakończy swoją bardzo dużą część obciążenia.
Jak przezwyciężyć słabe partycjonowanie w MapReduce?
Aby rozwiązać problem słabego partycjonowania w Hadoop MapReduce, możemy utworzyć niestandardowy partycjoner. Pozwala to na współdzielenie obciążenia między różnymi reduktorami.
Wniosek
Podsumowując, Partitioner umożliwia równomierne rozłożenie wyjścia mapy na reduktor. W MapReducer Partitioner partycjonowanie danych wyjściowych mapy odbywa się na podstawie klucza i wartości.
Dlatego na tym blogu omówiliśmy pełny przegląd programu Partitioner. Mam nadzieje ze ci się podobało. Jeśli pojawią się jakiekolwiek wątpliwości dotyczące aplikacji Hadoop Partitioner, nie zapomnij podzielić się z nami.



