W naszym poprzednim blogu omówiliśmy wprowadzenie Hadoop i Funkcje Hadoop , Teraz w tym blogu omówimy szczegółowo funkcję HDFS NameNode High Availability.
Najpierw omówimy architekturę wysokiej dostępności HDFS NemNode, a następnie implementację architektury wysokiej dostępności Hadoop przy użyciu węzłów dziennika Quorum i współdzielonej pamięci masowej.
Wysoka dostępność HDFS NameNode
W HDFS , dane są wysoce dostępne i dostępne pomimo awarii sprzętu. HDFS to najbardziej niezawodny system przechowywania przeznaczony do przechowywania bardzo dużych plików.
HDFS podąża za topologią master/slave. W którym masterze jest NameNode a niewolnikami jest DataNode . NameNode przechowuje metadane. Metadane obejmują liczbę bloków, ich lokalizację, repliki i inne szczegóły. Aby przyspieszyć pobieranie danych, metadane są dostępne w masterze. NameNode utrzymuje i przydziela zadania do węzła podrzędnego.
NameNode był pojedynczym punktem awarii (SPOF) przed Hadoop 2.0. Klaster HDFS miał jeden NameNode. Jeśli NameNode ulegnie awarii, cały klaster przestanie działać.
Pojedynczy punkt awarii ogranicza wysoką dostępność w następujący sposób:
- Jeśli jakiekolwiek nieplanowane zdarzenia wyzwolą się, takie jak awarie węzła, klaster będzie niedostępny, chyba że operator zrestartuje nowy nazwanode.
- Również zaplanowane działania konserwacyjne, takie jak aktualizacje sprzętu w NameNode, spowodują przestój klastra Hadoop.
Architektura wysokiej dostępności HDFS NameNode
Wprowadzenie Hadoop 2.0 przezwyciężyło tenSPOF zapewniając obsługę wielu NameNode. Architektura HDFS NameNode High Availability zapewnia opcję uruchamiania dwóch nadmiarowych NameNode w tym samym klastrze w konfiguracji aktywnej/pasywnej z gorącym trybem gotowości.
- Aktywny NameNode – Obsługuje wszystkie operacje klienta HDFS w klastrze HDFS.
- Pasywny węzeł nazwy – To jest zapasowy namenode. Ma podobne dane jak aktywny NameNode.
Tak więc, gdy tylko Active NameNode ulegnie awarii, pasywny NameNode przejmie całą odpowiedzialność za aktywny węzeł. W ten sposób klaster HDFS nadal działa.
Problemy z utrzymaniem spójności w klastrze HDFS High Availability są następujące:
- Aktywny i oczekujący NameNode powinny być zawsze zsynchronizowane ze sobą, tj. powinny mieć te same metadane. Pozwala to na przywrócenie klastra Hadoop do tego samego stanu przestrzeni nazw, w którym uległ awarii. A to zapewni nam szybkie przełączanie awaryjne.
- W danym momencie powinien być aktywny tylko jeden NameNode. W przeciwnym razie dwa NameNode doprowadzą do uszkodzenia danych. Nazywamy ten scenariusz „Scenariuszem podziału mózgu ”, gdzie klaster zostaje podzielony na klaster mniejszy. Każdy uważa, że jest to jedyny aktywny klaster. „Ogrodzenie” pozwala uniknąć takiego ogrodzenia to proces zapewniający, że tylko jeden NameNode pozostaje aktywny w określonym czasie.
Wdrożenie architektury wysokiej dostępności Hadoop
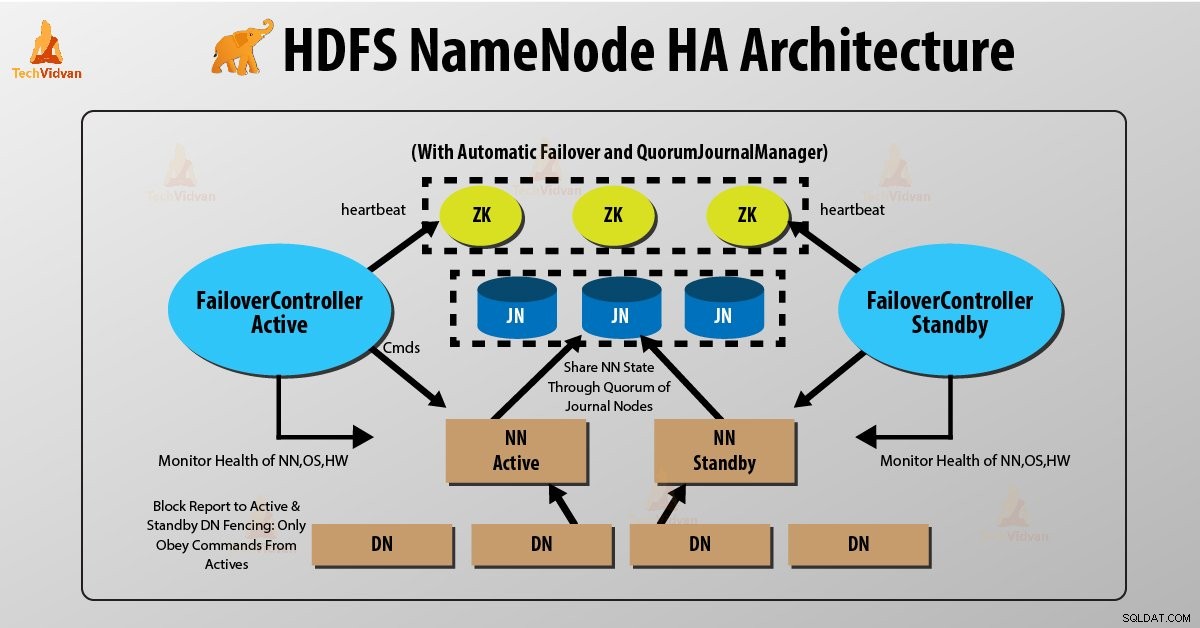
Dwa NameNode działają jednocześnie w architekturze wysokiej dostępności NameNode HDFS. Klient HDFS może zaimplementować konfigurację Active i Standby NameNode na dwa sposoby:
- Korzystanie z węzłów dziennika kworum
- Korzystanie ze współdzielonej pamięci
1. Korzystanie z węzłów dziennika kworum
Węzły dziennika kworum to implementacja HDFS. QJN zapewnia dzienniki edycji. Pozwala na udostępnianie tych dzienników edycji między aktywnym i oczekującym NameNode.
Standby Namenode komunikuje się i synchronizuje z aktywnym NameNode w celu zapewnienia wysokiej dostępności. Stanie się to przez grupę demonów zwanych „węzłami dziennika”. Węzły dziennika kworum działają jako grupa węzłów dziennika. Powinny tam być co najmniej trzy węzły dziennika.
W przypadku N węzłów dziennika system może tolerować co najwyżej (N-1)/2 awarie. W ten sposób system nadal działa. Tak więc dla trzech węzłów dziennika system może tolerować awarię jednego {(3-1)/2} z nich.
Za każdym razem, gdy aktywny węzeł wykonuje jakąkolwiek modyfikację, rejestruje modyfikacje we wszystkich węzłach dziennika.
Węzeł rezerwowy odczytuje zmiany z węzłów dziennika i stosuje się do własnej przestrzeni nazw w sposób ciągły. W przypadku przełączenia awaryjnego, rezerwa upewni się, że odczytała wszystkie edycje z węzłów dziennika przed przejściem do stanu Aktywny. Zapewnia to całkowitą synchronizację stanu przestrzeni nazw przed wystąpieniem awarii.
Aby zapewnić szybkie przełączanie awaryjne, węzeł rezerwowy musi mieć aktualne informacje o lokalizacji bloków danych w klastrze. Aby tak się stało, adres IP obu NameNode jest dostępny dla wszystkich węzłów danych i wysyłają one informacje o lokalizacji bloku i pulsy do obu NameNode.
Ogrodzenie NameNode
Aby zapewnić prawidłowe działanie klastra HA, tylko jeden z NameNodes powinien być aktywny naraz. W przeciwnym razie stan przestrzeni nazw różniłby się między dwoma NameNodes. Tak więc ogrodzenie jest procesem zapewniającym tę właściwość w klastrze.
- Węzły dziennika wykonują to ogrodzenie, zezwalając tylko jednemu NameNode na pisanie na raz.
- Standby NameNode bierze odpowiedzialność za zapis do węzłów dziennika i zabrania innym NameNode pozostania aktywnym.
- Wreszcie, nowy aktywny NameNode może wykonywać swoje działania.
2. Korzystanie ze współdzielonej pamięci masowej
Tryb gotowości i aktywny NameNode synchronizują się ze sobą za pomocą „udostępnionego urządzenia pamięci masowej”. W przypadku tej implementacji zarówno aktywny NameNode, jak i oczekujący Namenode muszą mieć dostęp do określonego katalogu na współdzielonym urządzeniu pamięci (tj. Sieciowy system plików).
Gdy aktywny NameNode wykonuje jakąkolwiek modyfikację przestrzeni nazw, rejestruje rekord modyfikacji w pliku dziennika edycji przechowywanym w katalogu współdzielonym. Węzeł NameNode w stanie gotowości obserwuje ten katalog w poszukiwaniu edycji, a gdy nastąpi edycja, NameNode w stanie gotowości stosuje je do własnej przestrzeni nazw. W przypadku awarii rezerwowy NameNode upewni się, że odczytał wszystkie edycje z udostępnionego magazynu przed przejściem do stanu Aktywny. Gwarantuje to, że stan przestrzeni nazw jest całkowicie zsynchronizowany, zanim nastąpi przełączenie awaryjne.
Aby zapobiec „scenariuszowi podziału mózgu”, w którym stan przestrzeni nazw różni się między dwoma NameNode, administrator musi skonfigurować co najmniej jedną metodę ogrodzenia dla współdzielonej pamięci masowej.
Wniosek
W związku z tym Hadoop 2.0 HDFS HA zapewnia pojedynczy aktywny NameNode i jeden rezerwowy NameNode. Jednak niektóre wdrożenia wymagają wysokiego stopnia odporności na błędy . Hadoop w nowej wersji 3.0, pozwala użytkownikowi na uruchomienie wielu oczekujących NameNodes.
Na przykład konfigurowanie pięciu węzłów dziennika i trzech węzłów NameNode. W rezultacie klaster hadoop jest w stanie tolerować awarię dwóch węzłów zamiast jednego.
Podziel się swoimi doświadczeniami i sugestiami związanymi z wysoką dostępnością HDFS NameNode w sekcji komentarzy poniżej.



