Ten samouczek Hadoop to wszystko o tasowaniu i sortowaniu MapReduce. Tutaj przedstawimy Ci szczegółowy opis fazy tasowania i sortowania Hadoop.
Najpierw omówimy, czym jest tasowanie MapReduce, następnie o sortowaniu MapReduce, a następnie omówimy szczegółowo drugą fazę sortowania MapReduce.
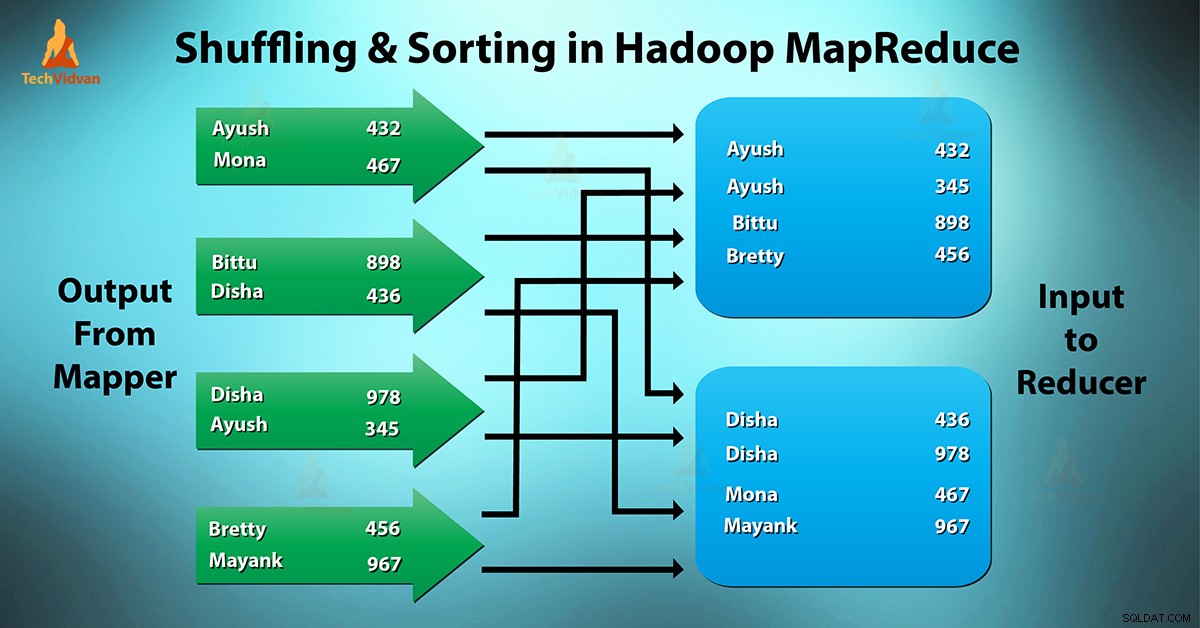
Co to jest tasowanie i sortowanie MapReduce?
Tasowanie to proces, w którym przenosi mapery wyjście pośrednie do reduktora. Reduktor otrzymuje 1 lub więcej kluczy i powiązanych wartości na podstawie reduktorów.
Klucz pośredniczący – wartość generowana przez maper jest sortowana automatycznie według klucza. W fazie sortowania następuje scalanie i sortowanie danych wyjściowych mapy.
Tasowanie i sortowanie w Hadoop odbywa się jednocześnie.
Tasowanie w MapReduce
Proces przesyłania danych z maperów do reduktorów przebiega tasowo. Jest to również proces, w którym system dokonuje sortowania. Następnie przekazuje dane wyjściowe mapy do reduktora jako dane wejściowe. To jest powód, dla którego faza tasowania jest konieczna dla reduktorów.
W przeciwnym razie nie mieliby żadnych danych wejściowych (lub danych wejściowych z każdego programu mapującego). Ponieważ tasowanie może rozpocząć się jeszcze przed zakończeniem fazy mapy. Dzięki temu oszczędza się trochę czasu i wykonuje zadania w krótszym czasie.
Sortowanie w MapReduce
MapReduce Framework automatycznie sortuje klucze wygenerowane przez program odwzorowujący. Dlatego przed uruchomieniem reduktora wszystkie pośrednie pary klucz-wartość są sortowane według klucza, a nie według wartości. Nie sortuje wartości przekazanych do każdego reduktora. Mogą być w dowolnej kolejności.
Sortowanie w zadaniu MapReduce pomaga firmie Reduce łatwo odróżnić, kiedy powinno rozpocząć się nowe zadanie redukcji.
Oszczędza to czas reduktora. Reduktor w MapReduce uruchamia nowe zadanie redukcji, gdy następny klucz w posortowanych danych wejściowych jest inny niż poprzedni. Każde zadanie redukcji przyjmuje pary klucz-wartość jako dane wejściowe i generuje parę klucz-wartość jako dane wyjściowe.
Należy zauważyć, że tasowanie i sortowanie w Hadoop MapReduce w ogóle nie będzie miało miejsca, jeśli określisz zero reduktorów (setNumReduceTasks(0)).
Jeśli reduktor wynosi zero, zadanie MapReduce zatrzymuje się w fazie mapy. A faza mapy nie obejmuje żadnego sortowania (nawet faza mapy jest szybsza).
Wtórne sortowanie w MapReduce
Jeśli chcemy posortować wartości reduktora, stosujemy technikę sortowania wtórnego. Ta technika umożliwia nam sortowanie wartości (w kolejności rosnącej lub malejącej) przekazywanych do każdego reduktora.
Wniosek
Podsumowując, MapReduce Tasowanie i sortowanie odbywa się jednocześnie, aby podsumować pośrednie dane wyjściowe programu Mapper. Hadoop Tasowanie-Sortowanie nie będzie miało miejsca, jeśli określisz zero reduktorów (setNumReduceTasks (0)).
Framework sortuje wszystkie pośrednie pary klucz-wartość według klucza, a nie według wartości. Używa sortowania wtórnego do sortowania według wartości. Jeśli masz jakieś sugestie lub pytania związane z fazą tasowania i sortowania MapReduce, zostaw komentarz w polu komentarza.
Z przyjemnością je rozwiążemy.



