Poznaj architekturę Hadoop, która jest najczęściej stosowaną platformą do przechowywania i przetwarzania ogromnych danych.
W tym artykule przyjrzymy się architekturze Hadoop. W artykule wyjaśniono architekturę Hadoop i składniki architektury Hadoop, którymi są HDFS, MapReduce i YARN. W artykule szczegółowo omówimy architekturę Hadoop wraz z diagramem Architektury Hadoop.
Zacznijmy teraz od architektury Hadoop.
Architektura Hadoop
Celem projektowania Hadoop jest opracowanie niedrogiego, niezawodnego i skalowalnego frameworka, który przechowuje i analizuje rosnące dane big data.
Apache Hadoop to platforma programowa zaprojektowana przez Apache Software Foundation do przechowywania i przetwarzania dużych zbiorów danych o różnych rozmiarach i formatach.
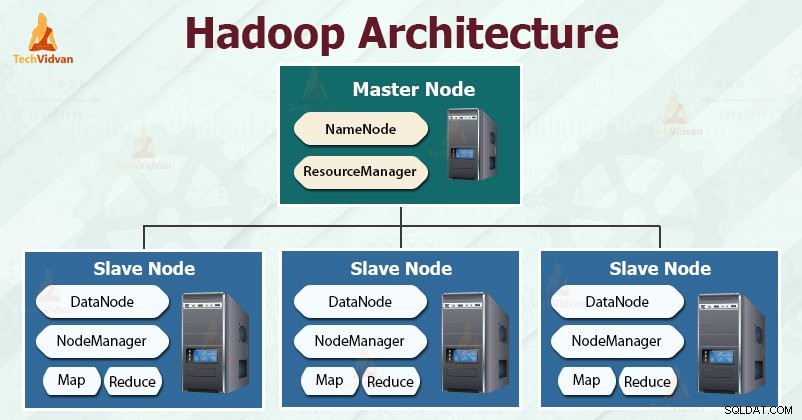
Hadoop podąża za master-slave architektura umożliwiająca efektywne przechowywanie i przetwarzanie ogromnych ilości danych. Węzły nadrzędne przydzielają zadania węzłom podrzędnym.
Węzły podrzędne są odpowiedzialne za przechowywanie rzeczywistych danych i wykonywanie rzeczywistych obliczeń/przetwarzania. Węzły główne są odpowiedzialne za przechowywanie metadanych i zarządzanie zasobami w klastrze.
Węzły podrzędne przechowują rzeczywiste dane biznesowe, podczas gdy węzły główne przechowują metadane.
Architektura Hadoop składa się z trzech warstw. Są to:
- Warstwa pamięci (HDFS)
- Warstwa zarządzania zasobami (YARN)
- Warstwa przetwarzania (MapReduce)
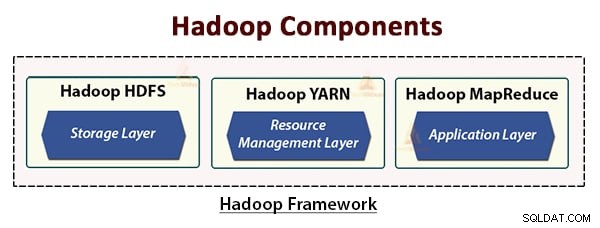
HDFS, YARN i MapReduce to podstawowe składniki platformy Hadoop.
Przeanalizujmy teraz szczegółowo te trzy podstawowe komponenty.
1. HDFS
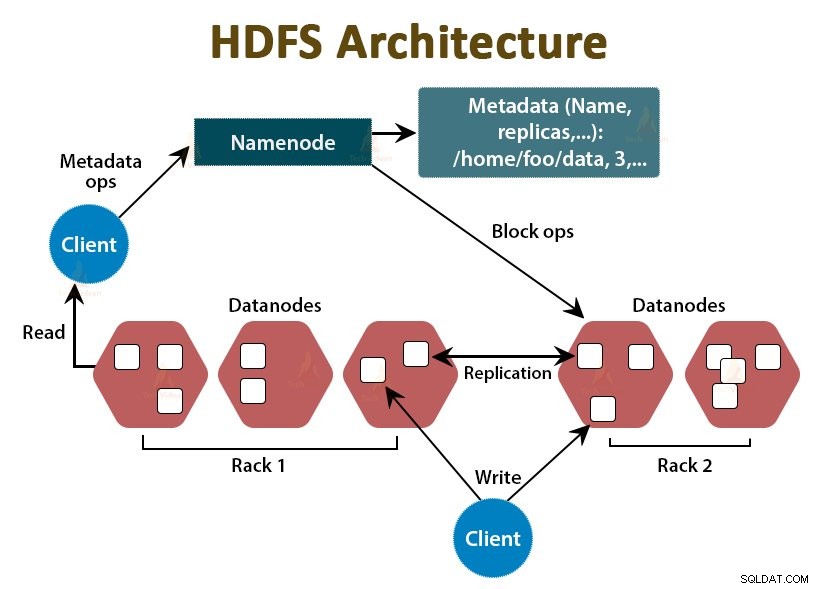
HDFS to rozproszony system plików Hadoop , który działa na niedrogim, standardowym sprzęcie. Jest to warstwa magazynująca Hadoop. Pliki w HDFS są podzielone na porcje wielkości bloków, zwane blokami danych.
Bloki te są następnie przechowywane w węzłach podrzędnych w klastrze. Rozmiar bloku to domyślnie 128 MB, który możemy skonfigurować zgodnie z naszymi wymaganiami.
Podobnie jak Hadoop, HDFS jest również zgodny z architekturą master-slave. Składa się z dwóch demonów — NameNode i DataNode. NameNode jest demonem głównym, który działa w węźle głównym. DataNodes to demon podrzędny, który działa na węzłach podrzędnych.
NameNode
NameNode przechowuje metadane systemu plików, to znaczy nazwy plików, informacje o blokach pliku, lokalizacje bloków, uprawnienia itp. Zarządza Datanode.
Węzeł danych
DataNodes to węzły podrzędne, które przechowują rzeczywiste dane biznesowe. Obsługuje żądania odczytu/zapisu klienta na podstawie instrukcji NameNode.
DataNodes przechowuje bloki plików, a NameNode przechowuje metadane, takie jak lokalizacje bloków, uprawnienia itp.
2. MapReduce
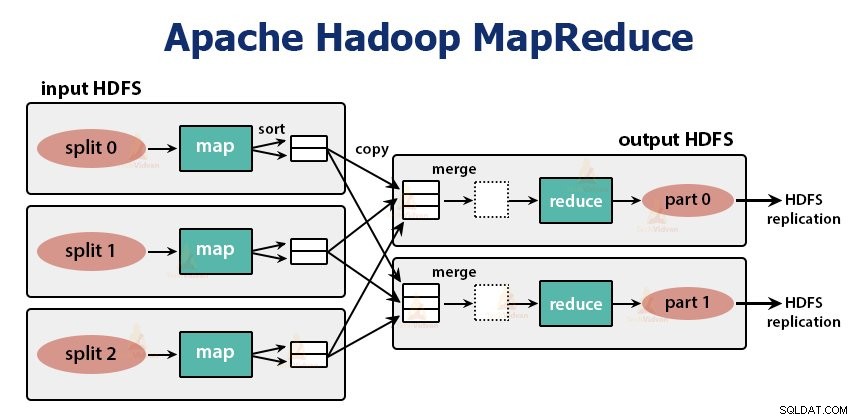
Jest to warstwa przetwarzania danych Hadoop. Jest to platforma programowa do pisania aplikacji, które przetwarzają ogromne ilości danych (od terabajtów do petabajtów w zakresie) równolegle w klastrze zwykłego sprzętu.
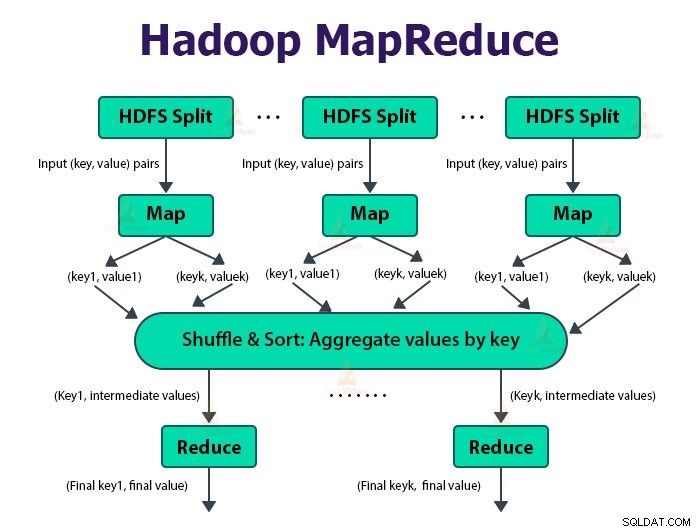
Framework MapReduce działa na parach
Zadanie MapReduce to jednostka pracy, którą klient chce wykonać. Zadanie MapReduce składa się głównie z danych wejściowych, programu MapReduce i informacji o konfiguracji. Hadoop uruchamia zadania MapReduce, dzieląc je na dwa typy zadań, które są zadaniami mapowania i ograniczenie zadań . Hadoop YARN zaplanował te zadania i jest uruchamiany na węzłach w klastrze.
Z powodu niesprzyjających warunków, jeśli zadania się nie powiedzą, zostaną automatycznie przełożone na inny węzeł.
Użytkownik definiuje funkcję mapy i funkcja redukcji za wykonanie zadania MapReduce.
Dane wejściowe funkcji map i dane wyjściowe funkcji zmniejszania to klucz, para wartości.
Zadaniem zadań mapy jest ładowanie, analizowanie, filtrowanie i przekształcanie danych. Dane wyjściowe zadania mapy są danymi wejściowymi zadania redukcyjnego. Zmniejsz zadanie, a następnie wykonuje grupowanie i agregację na wyjściu zadania mapy.
Zadanie MapReduce odbywa się w dwóch fazach-
1. Faza mapy
a. RekordReader
Hadoop dzieli dane wejściowe do zadania MapReduce na podziały o stałym rozmiarze zwane podziałami wejściowymi lub dzieli. RecordReader przekształca te podziały w rekordy i analizuje dane w rekordy, ale nie analizuje samych rekordów. RecordReader dostarcza dane do funkcji mapującej w parach klucz-wartość.
b. Mapa
W fazie mapy Hadoop tworzy jedno zadanie mapy, które uruchamia zdefiniowaną przez użytkownika funkcję o nazwie funkcja mapy dla każdego rekordu w podziale wejściowym. Generuje zero lub wiele pośrednich par klucz-wartość jako dane wyjściowe zadania mapy.
Zadanie mapy zapisuje swoje dane wyjściowe na dysku lokalnym. Te pośrednie dane wyjściowe są następnie przetwarzane przez zadania zmniejszania, które uruchamiają zdefiniowaną przez użytkownika funkcję zmniejszania w celu uzyskania końcowego wyniku. Po zakończeniu zadania dane wyjściowe mapy są usuwane.
c. Łącznik
Dane wejściowe do pojedynczego zadania redukcji to dane wyjściowe ze wszystkich elementów mapujących, które są wyprowadzane ze wszystkich zadań mapy. Hadoop pozwala użytkownikowi zdefiniować funkcję łączenia, która działa na wyjściu mapy.
Łącznik grupuje dane w fazie mapy przed przekazaniem ich do Reduktora. Łączy dane wyjściowe funkcji map, które są następnie przekazywane jako dane wejściowe do funkcji Reduce.
d. Partycjonowanie
Gdy istnieje wiele reduktorów, zadania map dzielą swoje dane wyjściowe, z których każdy tworzy jedną partycję dla każdego zadania redukcji. W każdej partycji może być wiele kluczy i skojarzonych z nimi wartości, ale wszystkie rekordy dla dowolnego klucza znajdują się na jednej partycji.
Hadoop umożliwia użytkownikom kontrolowanie partycjonowania przez określenie funkcji partycjonowania zdefiniowanej przez użytkownika. Ogólnie rzecz biorąc, istnieje domyślny Partitioner, który zbiera klucze za pomocą funkcji skrótu.
2. Zmniejsz fazę:
Poszczególne etapy zadania redukcyjnego są następujące:
a. Sortuj i mieszaj:
Zadanie Reduktor rozpoczyna się od kroku przetasowania i sortowania. Głównym celem tej fazy jest zebranie równoważnych kluczy. Faza sortowania i losowania pobiera dane, które są zapisywane przez partycję do węzła, w którym działa Reduktor.
Sortuje każdy fragment danych w obszerną listę danych. Struktura MapReduce wykonuje to sortowanie i tasuje, abyśmy mogli łatwo iterować w zadaniu redukcji.
sortowanie i tasowanie są wykonywane przez framework automatycznie. Deweloper za pomocą obiektu porównawczego może kontrolować sposób sortowania i grupowania kluczy.
b. Zmniejsz:
Reduktor, który jest funkcją redukcji zdefiniowaną przez użytkownika, wykonuje się raz na grupowanie kluczy. Reduktor filtruje, agreguje i łączy dane na kilka różnych sposobów. Po zakończeniu zadania redukcji daje zero lub więcej par klucz-wartość do OutputFormat. Wynik zadania zmniejszania jest przechowywany w Hadoop HDFS.
c. Format wyjściowy
Pobiera wyjście reduktora i zapisuje je do pliku HDFS przez RecordWriter. Domyślnie oddziela klucz, wartość tabulatorem, a każdy rekord znakiem nowej linii.
3. PRZĘDZA
YARN oznacza Yet Another Resource Negotiator . Jest to warstwa zarządzania zasobami Hadoop. Został wprowadzony w Hadoop 2.
YARN został zaprojektowany z myślą o podzieleniu funkcji planowania zadań i zarządzania zasobami na oddzielne demony. Podstawową ideą jest posiadanie globalnego menedżera zasobów i aplikacji Master na aplikację, gdzie aplikacja może być pojedynczym zadaniem lub DAGiem zadań.
YARN składa się z menedżera zasobów, menedżera węzłów i aplikacji ApplicationMaster.
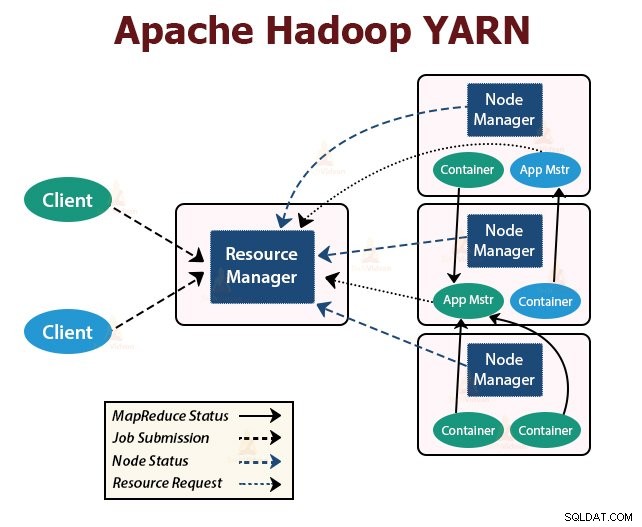
1. Menedżer zasobów
Arbitrażuje zasoby wśród wszystkich aplikacji w klastrze.
Ma dwa główne komponenty, którymi są Scheduler i ApplicationManager.
a. Harmonogram
- Harmonogram przydziela zasoby różnym aplikacjom działającym w klastrze, biorąc pod uwagę pojemność, kolejki itp.
- To czysty Scheduler. Nie monitoruje ani nie śledzi stanu aplikacji.
- Harmonogram nie gwarantuje ponownego uruchomienia nieudanych zadań, które nie powiodły się z powodu awarii aplikacji lub awarii sprzętu.
- Wykonuje planowanie w oparciu o wymagania dotyczące zasobów aplikacji.
b. Menedżer aplikacji
- Oni są odpowiedzialni za akceptację zgłoszeń pracy.
- ApplicationManager negocjuje pierwszy kontener do wykonywania ApplicationMaster specyficznego dla aplikacji.
- Zapewniają usługę ponownego uruchomienia kontenera ApplicationMaster w przypadku awarii.
- Program ApplicationMaster dla poszczególnych aplikacji jest odpowiedzialny za negocjowanie kontenerów z programu planującego. Śledzi i monitoruje ich stan i postępy.
2. NodeManager:
NodeManager działa na węzłach podrzędnych. Jest odpowiedzialny za kontenery, monitorowanie wykorzystania zasobów maszyny, czyli procesora, pamięci, dysku, wykorzystania sieci i raportowanie tego do menedżera zasobów lub harmonogramu.
3. Menedżer aplikacji:
ApplicationMaster dla aplikacji jest biblioteką specyficzną dla platformy. Odpowiada za negocjowanie zasobów od ResourceManagera. Współpracuje z NodeManager(ami) przy wykonywaniu i monitorowaniu zadań.
Podsumowanie
W tym artykule zbadaliśmy architekturę Hadoop. Hadoop podąża za topologią master-slave. Węzły główne przypisują zadania do węzłów podrzędnych. Architektura składa się z trzech warstw:HDFS, YARN i MapReduce.
HDFS to rozproszony system plików w Hadoop do przechowywania dużych zbiorów danych. MapReduce to platforma przetwarzania do przetwarzania dużych ilości danych w klastrze Hadoop w sposób rozproszony. YARN jest odpowiedzialny za zarządzanie zasobami między aplikacjami w klastrze.
Demon HDFS NameNode i demon ResourceManager YARN działają w węźle głównym w klastrze Hadoop. Demon HDFS DataNode i YARN NodeManager działają na węzłach podrzędnych.
Platforma HDFS i MapReduce działają na tym samym zestawie węzłów, co skutkuje bardzo wysoką łączną przepustowością w klastrze.
Ucz się dalej!!



