Dowiedz się o architekturze pozyskiwania danych niemal w czasie rzeczywistym do przekształcania i wzbogacania strumieni danych za pomocą Apache Flume, Apache Kafka i RocksDB w Santander UK.
Cloudera Professional Services współpracuje z Santander UK nad stworzeniem systemu analizy transakcyjnej w czasie zbliżonym do rzeczywistego (NRT) na Apache Hadoop. Celem jest uchwycenie, przekształcenie, wzbogacenie, zliczenie i przechowywanie transakcji w ciągu kilku sekund od zakupu karty. System odbiera transakcje kartami klientów detalicznych banku i oblicza powiązane informacje o trendach, agregowane według posiadacza rachunku oraz według wielu wymiarów i taksonomii. Informacje te są następnie bezpiecznie przesyłane do aplikacji Santander „Spendlytics” (patrz poniżej), aby umożliwić klientom analizę ich najnowszych wzorców wydatków.
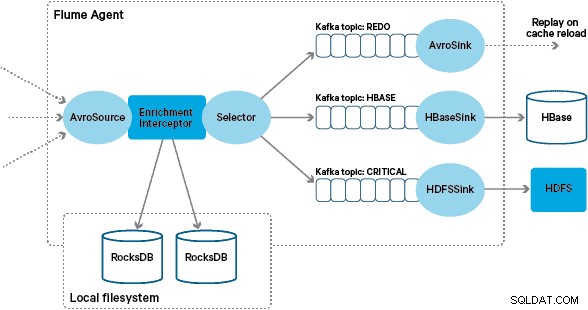
Apache HBase został wybrany jako podstawowe rozwiązanie pamięci masowej ze względu na jego zdolność do obsługi losowych zapisów o wysokiej przepustowości i losowych odczytów o niskim opóźnieniu. Jednak wymaganie NRT wykluczało wykonywanie transformacji i wzbogacania transakcji wsadowo, więc muszą one być wykonywane podczas przesyłania transakcji do HBase. Obejmuje to przekształcanie wiadomości z XML do Avro i wzbogacanie ich o informacje, które są trendy, takie jak informacje o marce i sprzedawcy.
Ten post opisuje, w jaki sposób Santander używa Apache Flume, Apache Kafka i RocksDB do przekształcania, wzbogacania i przesyłania strumieniowego transakcji do HBase. To jest implementacja przetwarzania zdarzeń NRT z kontekstem zewnętrznym wzorzec przesyłania strumieniowego opisany przez Teda Malaskę w tym poście.
flafka
Pierwszą decyzją, jaką musiał podjąć Santander, było jak najlepsze przesyłanie danych do HBase. Flume jest prawie zawsze najlepszym wyborem do przesyłania strumieniowego do Hadoop, biorąc pod uwagę jego prostotę, niezawodność, bogatą gamę źródeł i odbiorników oraz nieodłączną skalowalność.
Ostatnio dodano doskonałą integrację z Kafką, prowadząc do nieuchronnie nazwanego Flafka. Flume może natywnie zapewnić gwarantowane dostarczanie zdarzeń za pośrednictwem swojego kanału plików, ale możliwość odtwarzania zdarzeń oraz dodatkowa elastyczność i zabezpieczenie na przyszłość, jakie zapewnia Kafka, były kluczowymi czynnikami integracji.
W tej architekturze Santander używa kanałów Kafka, aby zapewnić niezawodny, samobalansujący i skalowalny bufor pozyskiwania, w którym wszystkie przekształcenia i przetwarzanie są reprezentowane w powiązanych tematach Kafki. W szczególności szeroko wykorzystujemy źródło i ujście Flafki oraz zdolność Flume do wykonywania przetwarzania w locie za pomocą Interceptorów. Uniemożliwiło nam to kodowanie naszego własnego producenta i konsumenta Kafki, a także pozwoliło Santanderowi w pełni wykorzystać Cloudera Manager do konfigurowania, wdrażania i monitorowania agentów i brokerów.
Transformacja
Transakcje przechwycone przez podstawowe systemy bankowe są dostarczane do Flume jako komunikaty XML po odczytaniu ze źródłowej bazy danych za pomocą replikacji dzienników. (Dopasowywanie dziennika bazy danych do tematów Kafki w ten sposób jest coraz bardziej powszechnym wzorcem i w połączeniu z kompaktowaniem dziennika może dać „najnowszy widok” bazy danych w celu zmiany przypadków użycia przechwytywania danych).
Flume przechowuje te wiadomości XML w „surowym” temacie Kafki. Stąd, jako prekursor wszystkich innych procesów przetwarzania, zdecydowano o przekształceniu częściowo ustrukturyzowanego XML w ustrukturyzowane rekordy binarne, aby ułatwić ustandaryzowane przetwarzanie w dół. Przetwarzanie to jest wykonywane przez niestandardowy Flume Interceptor, który przekształca komunikaty XML w ogólną reprezentację Avro, stosując określone typy tam, gdzie jest to właściwe, i powracając do reprezentacji łańcuchowej, jeśli nie. Całe późniejsze przetwarzanie NRT następnie przechowuje uzyskane wyniki w Avro w dedykowanych tematach Kafki, co ułatwia dostęp do strumienia i uzyskanie strumienia zdarzeń w dowolnym punkcie łańcucha przetwarzania.
Jeśli wymagane byłoby bardziej złożone przetwarzanie zdarzeń — na przykład agregacje z użyciem Spark Streaming — byłoby trywialną sprawą wykorzystać jeden lub więcej z tych tematów i opublikować je w nowych tematach pochodnych. (Apache Avro jest naturalnym wyborem dla tego formatu:jest to kompaktowy protokół binarny obsługujący ewolucję schematu, ma elastyczną definicję schematu i jest obsługiwany w całym stosie Hadoop. Avro szybko staje się de facto standardem do tymczasowego i ogólnego przechowywania danych w centrum danych korporacyjnych i doskonale nadaje się do przekształcenia w Apache Parquet na potrzeby obciążeń analitycznych).
Wzbogacanie
Inspiracją do zaprojektowania rozwiązania do wzbogacania strumieniowego był post O’Reilly Radar napisany przez Jaya Krepsa. W swoim poście Jay opisuje korzyści płynące z używania lokalnego sklepu, aby umożliwić procesorowi strumienia wysyłanie zapytań lub modyfikowanie lokalnego stanu w odpowiedzi na jego dane wejściowe, w przeciwieństwie do wykonywania zdalnych wywołań do rozproszonej bazy danych.
W Santander dostosowaliśmy ten wzorzec, aby zapewnić lokalne magazyny referencyjne, które są używane do odpytywania i wzbogacania transakcji przesyłanych strumieniowo przez Flume. Dlaczego nie używać HBase jako sklepu referencyjnego? Cóż, typowym wzorcem dla tego typu problemu jest po prostu przechowywanie stanu w HBase i bezpośrednie zapytanie mechanizmu wzbogacania. Zrezygnowaliśmy z takiego podejścia z kilku powodów. Po pierwsze, dane referencyjne są stosunkowo małe i zmieściłyby się w jednym regionie HBase, prawdopodobnie powodując hotspot regionu. Po drugie, HBase obsługuje aplikację Spendlytics skierowaną do klienta, a Santander nie chciał, aby dodatkowe obciążenie wpływało na opóźnienia aplikacji i odwrotnie. Jest to również powód, dla którego zdecydowaliśmy się nie używać HBase nawet do ładowania lokalnych sklepów podczas uruchamiania.
Tak więc, zapewniając każdemu agentowi Flume szybki lokalny sklep w celu wzbogacenia wydarzeń podczas lotu, Santander jest w stanie zapewnić lepsze gwarancje wydajności zarówno w zakresie wzbogacania podczas lotu, jak i aplikacji Spendlytics. Zdecydowaliśmy się na wykorzystanie RocksDB do implementacji lokalnych sklepów, ponieważ jest w stanie zapewnić szybki dostęp do dużej ilości danych poza stertą (eliminując obciążenie GC) oraz fakt, że posiada Java API ułatwiające korzystanie z niestandardowy Flume Interceptor. Dzięki takiemu podejściu nie musieliśmy kodować własnego sklepu ze stertą. RocksDB można łatwo wymienić na inną implementację lokalnego sklepu, ale w tym przypadku było to idealne dopasowanie do przypadku użycia Santandera.
Niestandardowa implementacja Interceptora wzbogacania Flume przetwarza zdarzenia z wcześniejszego „przekształconego” tematu, wysyła zapytania do lokalnego sklepu, aby je wzbogacić, i zapisuje wyniki w dalszych tematach Kafki w zależności od wyniku. Ten proces jest zilustrowany bardziej szczegółowo poniżej.
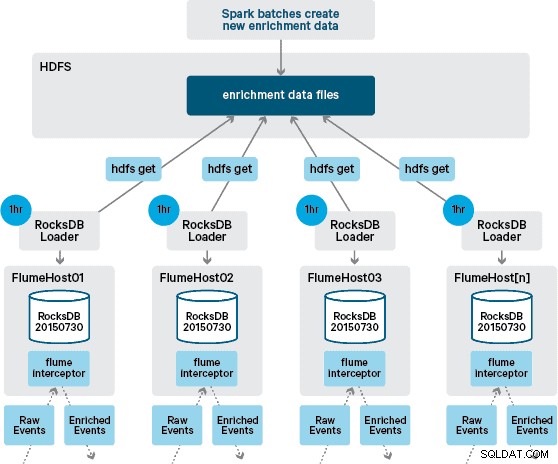
W tym momencie możesz się zastanawiać:w jaki sposób generowane są lokalne magazyny bez trwałości zapewnianej przez HBase? Dane referencyjne obejmują wiele różnych zestawów danych, które należy ze sobą połączyć. Te zestawy danych są codziennie odświeżane w HDFS i stanowią dane wejściowe do zaplanowanej aplikacji Apache Spark, która generuje magazyny RocksDB. Nowo wygenerowane magazyny RocksDB są umieszczane w HDFS, dopóki nie zostaną pobrane przez agentów Flume, aby zapewnić wzbogacenie strumienia zdarzeń o najnowsze informacje.
W idealnym przypadku nie musielibyśmy czekać, aż wszystkie te zestawy danych będą dostępne w HDFS, zanim będą mogły zostać przetworzone. Gdyby tak było, aktualizacje danych referencyjnych mogłyby być przesyłane strumieniowo przez potok Flafka, aby stale utrzymywać lokalny stan danych referencyjnych.
W naszym początkowym projekcie planowaliśmy napisać i zaplanować za pomocą crona skrypt do odpytywania HDFS w celu sprawdzenia nowych wersji sklepów RocksDB, pobierając je z HDFS, gdy są dostępne. Chociaż ze względu na wewnętrzne kontrole i zarządzanie środowiskami produkcyjnymi Santander mechanizm ten musiał zostać włączony do tego samego Flume Interceptor, który jest używany do przeprowadzania wzbogacania (sprawdza aktualizacje raz na godzinę, więc nie jest to kosztowna operacja). Gdy dostępna jest nowa wersja sklepu, do wątku roboczego wysyłane jest zadanie pobrania nowego sklepu z HDFS i załadowania go do RocksDB. Ten proces odbywa się w tle, podczas gdy Interceptor wzbogacania kontynuuje przetwarzanie strumienia. Gdy nowa wersja sklepu zostanie załadowana do RocksDB, Interceptor przełącza się na najnowszą wersję, a wygasły sklep jest usuwany. Ten sam mechanizm jest używany do ładowania zasobów RocksDB po zimnym starcie, zanim Interceptor zacznie próbować wzbogacać zdarzenia.
Pomyślnie wzbogacone wiadomości są zapisywane w temacie Kafki, aby były idempotentnie zapisywane w HBase przy użyciu HBaseEventSerializer.
Chociaż strumień zdarzeń jest przetwarzany w sposób ciągły, nowe wersje sklepu lokalnego można generować tylko codziennie. Natychmiast po załadowaniu nowej wersji lokalnego sklepu przez Flume jest ona uważana za świeżą”, chociaż staje się coraz bardziej przestarzała przed udostępnieniem nowej wersji. W konsekwencji liczba „braków w pamięci podręcznej” wzrasta, dopóki nie będzie dostępna nowsza wersja sklepu lokalnego. Na przykład, nowe i zaktualizowane informacje o marce i sprzedawcy mogą być dodawane do danych referencyjnych, ale dopóki nie zostaną udostępnione firmie Flume wzbogacenie transakcji Interceptor może nie zostać wzbogacone lub zostać wzbogacone o nieaktualne informacje, które później muszą zostać uzgodnione po utrwaleniu w HBase.
Aby poradzić sobie z tym przypadkiem, braki w pamięci podręcznej (zdarzenia, które nie zostały wzbogacone) są zapisywane w temacie Kafki „ponownie” za pomocą selektora Flume. Temat ponawiania jest następnie odtwarzany z powrotem do tematu źródłowego Interceptora wzbogacenia, gdy dostępny jest nowy lokalny sklep.
Aby zapobiec „zatrutym wiadomościom” (wydarzeniom, które stale się nie wzbogacają), postanowiliśmy dodać licznik do nagłówka zdarzenia przed dodaniem go do tematu ponawiania. Zdarzenia, które wielokrotnie pojawiają się w tym temacie, są ostatecznie przekierowywane do „krytycznego” tematu, który jest zapisywany w HDFS w celu późniejszej kontroli i naprawy. To podejście jest zilustrowane na pierwszym diagramie.
Wniosek
Podsumowując główne punkty na wynos z tego postu:
- Używanie łańcucha tematów Kafki do przechowywania pośrednich danych współdzielonych jako części potoku pozyskiwania jest skutecznym wzorcem.
- Masz wiele opcji utrwalania i wykonywania zapytań o stan lub dane referencyjne w potoku pozyskiwania NRT. Preferuj HBase do tego celu jako wspólny wzorzec, gdy dodatkowe dane są duże, ale rozważ użycie wbudowanych lokalnych sklepów (takich jak RocksDB) lub pamięci JVM do korzystania z HBase nie jest praktyczne.
- Obsługa awarii jest ważna. (Zobacz #1, aby uzyskać pomoc na ten temat.)
W kolejnym poście opiszemy, w jaki sposób wykorzystujemy koprocesory HBase do zapewniania agregacji historycznych trendów zakupowych dla poszczególnych klientów oraz w jaki sposób transakcje offline są przetwarzane wsadowo przy użyciu (projekt Cloudera Labs) SparkOnHBase (który został niedawno zatwierdzony do pień HBase). Opiszemy również, w jaki sposób rozwiązanie zostało zaprojektowane, aby spełnić wymagania klienta dotyczące wysokiej dostępności między centrami danych.
James Kinley, Ian Buss i Rob Siwicki są architektami rozwiązań w Cloudera.



