Ocena, który wzorzec architektury przesyłania strumieniowego najlepiej pasuje do przypadku użycia, jest warunkiem wstępnym udanego wdrożenia produkcyjnego.
Ekosystem Apache Hadoop stał się preferowaną platformą dla przedsiębiorstw, które chcą przetwarzać i rozumieć dane na dużą skalę w czasie rzeczywistym. Technologie takie jak Apache Kafka, Apache Flume, Apache Spark, Apache Storm i Apache Samza coraz bardziej przesuwają granice tego, co jest możliwe. Często kuszące jest łączenie przypadków użycia strumieniowania na dużą skalę, ale w rzeczywistości mają one tendencję do rozbijania się na kilka różnych wzorców architektonicznych, z różnymi komponentami ekosystemu lepiej dostosowanymi do różnych problemów.
W tym poście przedstawię cztery główne wzorce przesyłania strumieniowego, które napotkaliśmy u klientów korzystających z korporacyjnych centrów danych w środowisku produkcyjnym, i wyjaśnię, jak zaimplementować te wzorce architektonicznie w Hadoop.
Wzorce przesyłania strumieniowego
Cztery podstawowe wzorce przesyłania strumieniowego (często używane w tandemie) to:
- Przetwarzanie strumienia: Obejmuje utrzymywanie zdarzeń z małymi opóźnieniami w HDFS, Apache HBase i Apache Solr.
- Przetwarzanie zdarzeń w czasie rzeczywistym (NRT) z kontekstem zewnętrznym: Podejmuje działania, takie jak ostrzeganie, oznaczanie, przekształcanie i filtrowanie zdarzeń, gdy nadejdą. Działania mogą być podejmowane w oparciu o wyrafinowane kryteria, takie jak modele wykrywania anomalii. Typowe przypadki użycia, takie jak wykrywanie oszustw i rekomendacje NRT, często wymagają niskich opóźnień poniżej 100 milisekund.
- Przetwarzanie partycjonowane zdarzeń NRT: Podobne do przetwarzania zdarzeń NRT, ale czerpie korzyści z partycjonowania danych — na przykład przechowywanie bardziej istotnych informacji zewnętrznych w pamięci. Ten wzorzec wymaga również przetwarzania opóźnień poniżej 100 milisekund.
- Złożona topologia dla agregacji lub ML: Święty Graal przetwarzania strumieniowego:otrzymuje odpowiedzi w czasie rzeczywistym z danych za pomocą złożonego i elastycznego zestawu operacji. Tutaj, ponieważ wyniki często zależą od obliczeń w oknach i wymagają większej liczby aktywnych danych, nacisk przenosi się z bardzo niskiego opóźnienia na funkcjonalność i dokładność.
W kolejnych sekcjach zapoznamy się z zalecanymi sposobami implementacji takich wzorców w przetestowany, sprawdzony i łatwy w utrzymaniu sposób.
Przetwarzanie strumieniowe
Tradycyjnie Flume był zalecanym systemem do przesyłania strumieniowego. Jego duża biblioteka źródeł i zlewów obejmuje wszystkie podstawy tego, co należy konsumować i gdzie pisać. (Szczegółowe informacje na temat konfiguracji i zarządzania Flume, Korzystanie z Flume , książka O’Reilly Media autorstwa Cloudera Software Engineer/członka Flume PMC, Hariego Shreedharana, jest doskonałym źródłem informacji.)
W ciągu ostatniego roku Kafka stała się popularna również dzięki zaawansowanym funkcjom, takim jak odtwarzanie i replikacja. Ze względu na nakładanie się celów Flume'a i Kafki, ich związek jest często mylący. Jak one do siebie pasują? Odpowiedź jest prosta:Kafka jest rurą podobną do abstrakcji Flume's Channel, aczkolwiek lepszą rurą ze względu na obsługę wyżej wymienionych funkcji. Jednym z powszechnych rozwiązań jest użycie Flume jako źródła i zlewu, a Kafki jako rury między nimi.
Poniższy diagram ilustruje, w jaki sposób Kafka może służyć jako źródło danych w górę strumienia do Flume, miejsce docelowe strumienia Flume lub kanał Flume.
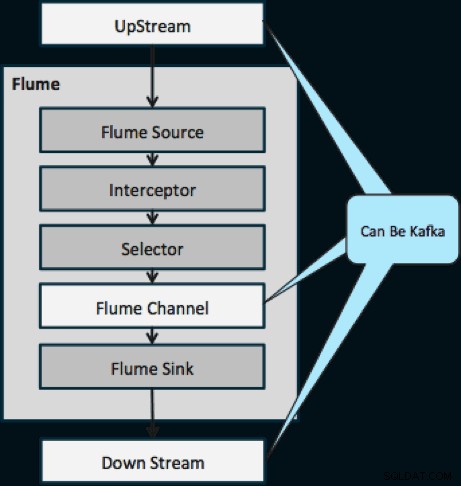
Przedstawiony poniżej projekt jest niezwykle skalowalny, zahartowany w bojach, centralnie monitorowany przez Cloudera Manager, odporny na błędy i obsługuje odtwarzanie.
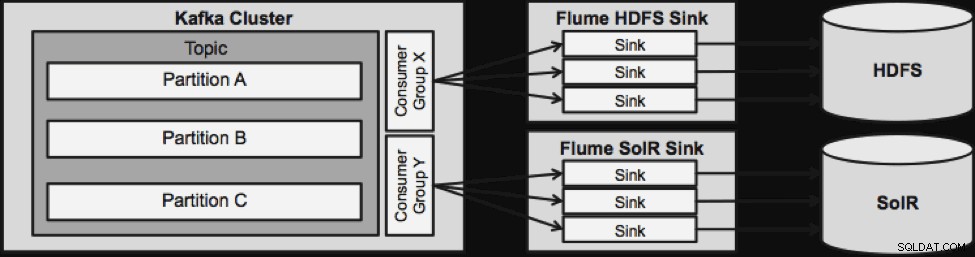
Zanim przejdziemy do następnej architektury strumieniowania, należy zwrócić uwagę na to, jak ten projekt z wdziękiem radzi sobie z awariami. Zlewozmywaki Flume pochodzą z grupy konsumenckiej Kafka. Grupa Konsumentów śledzi przesunięcie tematu z pomocą Apache ZooKeeper. W przypadku zgubienia zlewu Flume Sink, konsument Kafki przeniesie obciążenie do pozostałych zlewów. Kiedy Flume Sink powróci, grupa Konsumentów ponownie się rozprowadzi.
Przetwarzanie zdarzeń NRT z kontekstem zewnętrznym
Powtarzając, typowym przypadkiem użycia tego wzorca jest przyjrzenie się napływającym zdarzeniom i podjęcie natychmiastowych decyzji dotyczących przekształcenia danych lub podjęcia działań zewnętrznych. Logika decyzji często zależy od profili zewnętrznych lub metadanych. Łatwym i skalowalnym sposobem wdrożenia tego podejścia jest dodanie modułu przechwytującego Source lub Sink Flume do architektury Kafka/Flume. Przy skromnym dostrojeniu nie jest trudno osiągnąć opóźnienia w krótkich milisekundach.
Flume Interceptory przejmują zdarzenia lub partie zdarzeń i pozwalają kodowi użytkownika na modyfikowanie lub podejmowanie działań na ich podstawie. Kod użytkownika może wchodzić w interakcje z pamięcią lokalną lub zewnętrznym systemem pamięci masowej, takim jak HBase, aby uzyskać informacje o profilu potrzebne do podejmowania decyzji. HBase zwykle może dostarczyć nam nasze informacje w około 4-25 milisekund, w zależności od sieci, projektu schematu i konfiguracji. Możesz także skonfigurować HBase w taki sposób, aby nigdy nie było wyłączone ani przerywane, nawet w przypadku awarii.
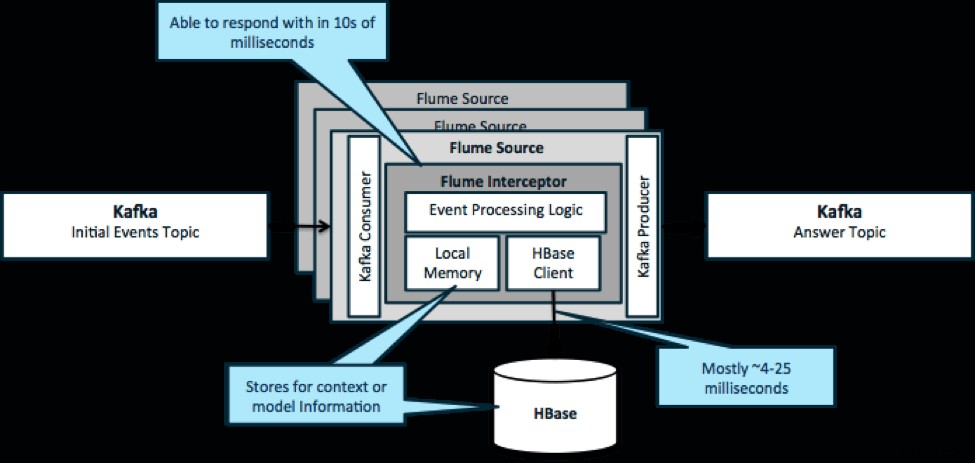
Implementacja prawie nie wymaga kodowania poza logiką specyficzną dla aplikacji w przechwytywaczu. Cloudera Manager oferuje intuicyjny interfejs użytkownika do wdrażania tej logiki za pośrednictwem paczek, a także podłączania, konfigurowania i monitorowania usług.
Przetwarzanie zdarzeń partycjonowanych NRT z kontekstem zewnętrznym
W architekturze zilustrowanej poniżej (rozwiązanie niepartycjonowane) należałoby często odwoływać się do HBase, ponieważ kontekst zewnętrzny związany z konkretnymi zdarzeniami nie mieści się w pamięci lokalnej na przechwytywaczach Flume.
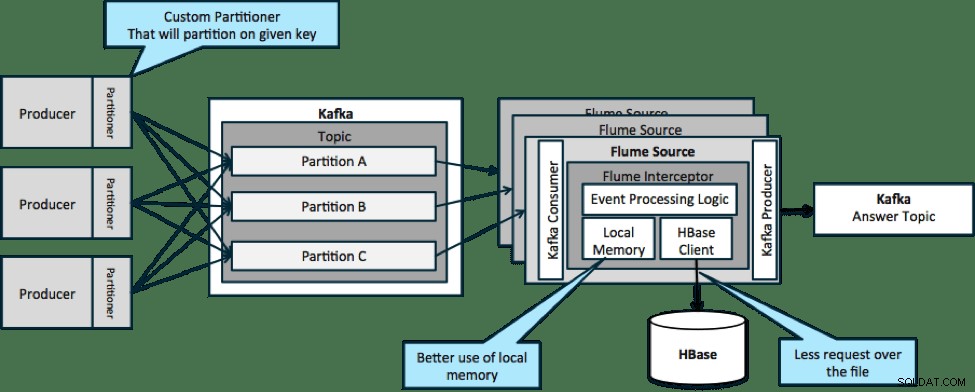
Jeśli jednak zdefiniujesz klucz do partycjonowania danych, możesz dopasować dane przychodzące do odpowiedniego podzbioru danych kontekstowych. Jeśli podzielisz dane 10 razy, wystarczy przechowywać w pamięci tylko 1/10 profili. HBase jest szybki, ale pamięć lokalna jest szybsza. Kafka umożliwia zdefiniowanie niestandardowego partycjonera, którego używa do dzielenia danych.
Zauważ, że Flume nie jest tutaj bezwzględnie konieczne; rozwiązanie root tutaj tylko konsument Kafki. Możesz więc użyć tylko konsumenta w YARN lub aplikacji MapReduce zawierającej tylko mapę.
Złożona topologia dla agregacji lub ML
Do tego momentu badaliśmy operacje na poziomie wydarzenia. Czasami jednak potrzebne są bardziej złożone operacje, takie jak zliczanie, średnie, sesja lub budowanie modelu uczenia maszynowego, które działają na partiach danych. W tym przypadku Spark Streaming jest idealnym narzędziem z kilku powodów:
- Jest łatwy do opracowania w porównaniu z innymi narzędziami. Bogate i zwięzłe interfejsy API Sparka ułatwiają tworzenie złożonych topologii.
- Podobny kod do przesyłania strumieniowego i przetwarzania wsadowego. Po kilku zmianach kod dla małych partii w czasie rzeczywistym może być używany do dużych partii w trybie offline. Oprócz zmniejszenia rozmiaru kodu, takie podejście skraca czas potrzebny na testowanie i integrację.
- Należy znać jeden silnik. Szkolenie personelu w zakresie dziwactw i elementów wewnętrznych silników przetwarzania rozproszonego wiąże się z pewnymi kosztami. Standaryzacja w Spark konsoliduje ten koszt zarówno w przypadku przesyłania strumieniowego, jak i wsadowego.
- Mikropartie pomagają w niezawodnym skalowaniu. Potwierdzanie na poziomie partii pozwala na większą przepustowość i pozwala na rozwiązania bez obawy o podwójne wysłanie. Mikrodozowanie pomaga również w wysyłaniu zmian do HDFS lub HBase pod względem wydajności na dużą skalę.
- Integracja ekosystemu Hadoop jest zapieczętowana. Spark ma głęboką integrację z HDFS, HBase i Kafka.
- Brak ryzyka utraty danych. Dzięki WAL i Kafce Spark Streaming pozwala uniknąć utraty danych w przypadku awarii.
- Łatwo debugować i uruchomić. Możesz debugować i przechodzić przez kod Spark Streaming w lokalnym środowisku IDE bez klastra. Ponadto kod wygląda jak normalny kod programowania funkcjonalnego, więc wykonanie skoku nie zajmuje dużo czasu programiście Java lub Scala. (Obsługiwany jest również Python.)
- Transmisja strumieniowa jest natywnie stanowa. W Spark Streaming stan jest obywatelem pierwszej klasy, co oznacza, że łatwo jest pisać stanowe aplikacje do przesyłania strumieniowego, które są odporne na awarie węzłów.
- Jako de facto standard Spark otrzymuje długoterminowe inwestycje z całego ekosystemu.
W chwili pisania tego tekstu było około 700 zatwierdzeń dla Sparka jako całości w ciągu ostatnich 30 dni — w porównaniu z innymi frameworkami strumieniowymi, takimi jak Storm, z 15 zatwierdzeniami w tym samym czasie. - Masz dostęp do bibliotek ML.
Biblioteka MLlib firmy Spark staje się niezwykle popularna, a jej funkcjonalność będzie się tylko zwiększać. - W razie potrzeby możesz użyć SQL.
Dzięki Spark SQL możesz dodać logikę SQL do aplikacji do przesyłania strumieniowego, aby zmniejszyć złożoność kodu.
Wniosek
Strumieniowanie ma dużą moc i kilka możliwych wzorców, ale jak nauczyłeś się w tym poście, możesz robić naprawdę potężne rzeczy przy minimalnym kodowaniu, jeśli wiesz, który wzorzec najlepiej pasuje do twojego przypadku użycia.
Ted Malaska jest architektem rozwiązań w Cloudera, współpracownikiem firm Spark, Flume i HBase oraz współautorem książki O’Reilly, Architektura aplikacji Hadoop.



