tl;dr:Elasticache zmusza do korzystania z pojedynczej instancji redis, co jest nieoptymalne.
Długa wersja:
Zdaję sobie sprawę, że to stary post (2 lata w momencie pisania tego tekstu), ale myślę, że ważne jest, aby zwrócić uwagę na punkt, którego tutaj nie widzę.
W przypadku elasticache Twoim wdrożeniem redis zarządza Amazon. Oznacza to, że utkniesz z tym, jak zdecydują się na uruchomienie Twojego redis.
Redis używa pojedynczego wątku wykonania dla odczytów/zapisów. Zapewnia to spójność bez blokowania. Jest to główny atut pod względem wydajności, który nie pozwala na zarządzanie zamkami i zatrzaskami. Niefortunną konsekwencją jest jednak to, że jeśli twój EC2 ma więcej niż 1 vCPU, nie będą one używane. Tak jest w przypadku wszystkich instancji Elasticache z więcej niż jednym procesorem wirtualnym.
Domyślny rozmiar instancji elasticache to cache.r3.large , który ma dwa rdzenie.
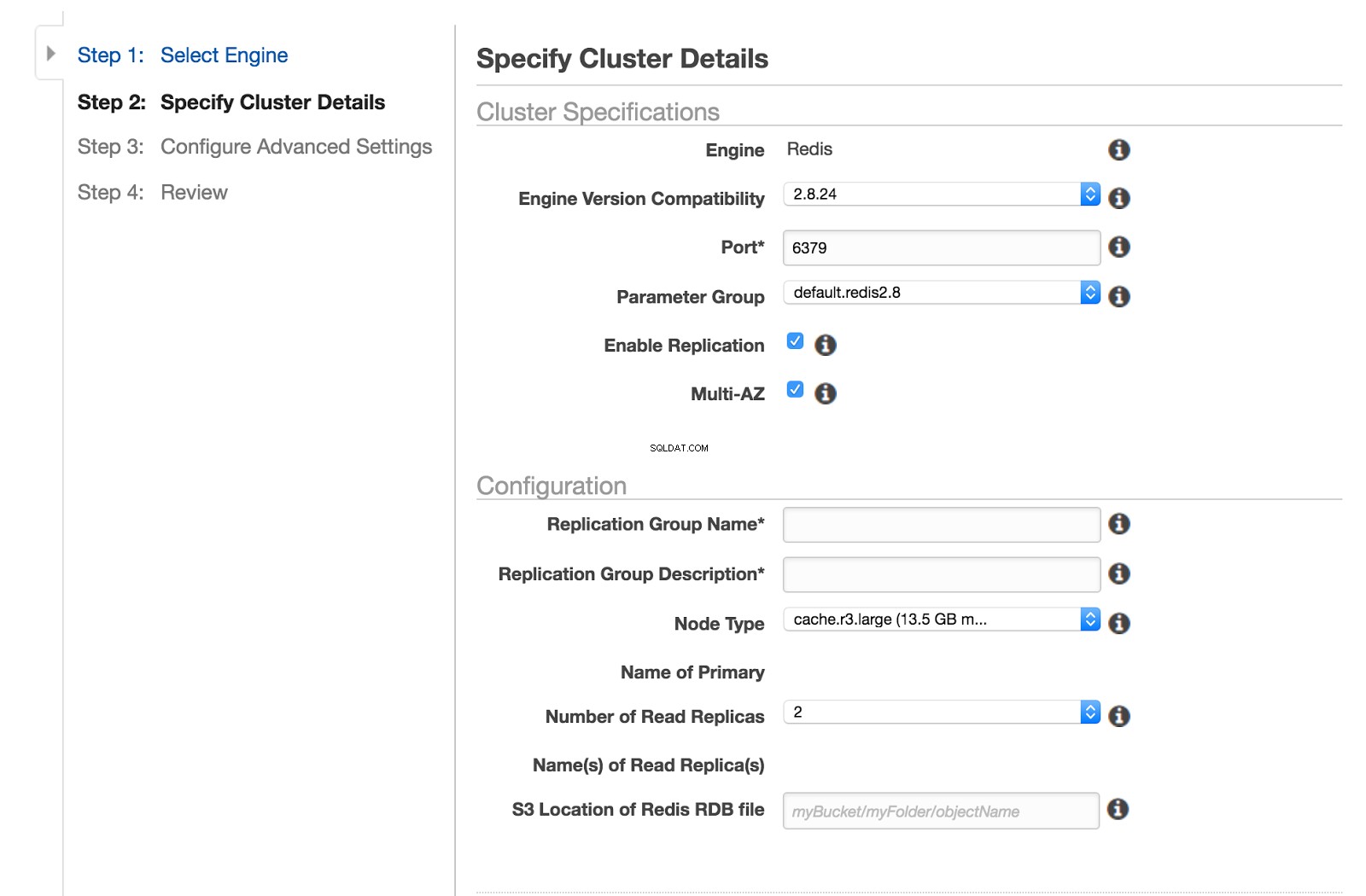
W rzeczywistości istnieje wiele rozmiarów instancji z wieloma procesorami wirtualnymi. Wiele okazji do zamanifestowania się tego problemu.
Wygląda na to, że Amazon jest już świadomy tego problemu, ale wydaje się go nieco lekceważyć.

Częścią, która sprawia, że jest to szczególnie istotne w przypadku tego pytania, jest to, że w EC2 (ponieważ zarządzasz własnym wdrożeniem) możesz zaimplementować wielodostępność . Oznacza to, że masz wiele instancji procesu redis nasłuchujących na różnych portach. Wybierając port do odczytu/zapisu do/z w aplikacji na podstawie skrótu klucza rekordu, możesz wykorzystać wszystkie swoje procesory wirtualne.
Na marginesie; Wdrożenie redis elasticache na maszynie wielordzeniowej powinno zawsze być niewystarczające w porównaniu z wdrożeniem memcached elasticache w rozmiarze instancji. W przypadku wielu najemców redis jest zwykle zwycięzcą.
Aktualizacja:
Amazon udostępnia teraz oddzielne metryki dla procesora instancji redis, EngineCPUUtilization. Nie musisz już obliczać swojego procesora za pomocą tandetnego mnożenia, ale multi-tenancy nadal nie jest zaimplementowane.



