Jeśli chodzi o analizę wykorzystania pamięci przez instancję Redis, na rynku dostępnych jest wiele bezpłatnych narzędzi o otwartym kodzie źródłowym, a także kilka płatnych produktów. Niektóre z najpopularniejszych to walety (ze wszystkich sławnych branż), ale jeśli szukasz głębszej analizy problemów z pamięcią, może być lepiej, jeśli skorzystasz z jednego z bardziej ukierunkowanych i mniej znanych narzędzi.
W tym poście przygotowaliśmy listę 6 najlepszych bezpłatnych narzędzi, które uznaliśmy za najbardziej przydatne do analizy wykorzystania pamięci naszych instancji Redis:
- Analizator pamięci Redis (RMA)
- Próbnik Redis
- Narzędzia RDB
- Ponowny audyt
- Zestaw narzędzi Redis
- Żniwa
1) Analizator pamięci Redis

Redis Memory Analyzer (RMA) to jeden z najbardziej wszechstronnych analizatorów pamięci FOSS dostępnych dla Redis. Obsługuje trzy różne poziomy szczegółów:
- Globalny – Przegląd informacji o wykorzystaniu pamięci.
- Skaner – Informacje o wykorzystaniu pamięci najwyższego poziomu przestrzeni klawiszy/prefiksu – innymi słowy, używany jest najkrótszy wspólny prefiks.
- RAM – Przestrzeń klawiszy/prefiks najniższego poziomu – innymi słowy, używany jest najdłuższy wspólny prefiks.
Każdy tryb ma swoje własne zastosowania — dalsze szczegóły można znaleźć w RMA ReadMe.

RMA – tryb globalny
W trybie globalnym RMA zapewnia pewne statystyki wysokiego poziomu, takie jak liczba kluczy, pamięć systemowa, rozmiar zestawu rezydentnego, rozmiar przestrzeni kluczy itp. Unikalną cechą jest „ narzut przestrzeni klawiszy”, który jest pamięcią używaną przez system Redis do przechowywania informacji związanych z przestrzenią klawiszy, takich jak wskaźniki do struktur danych list.
RMA – Tryb skanera

W trybie skanera otrzymujemy przegląd naszej przestrzeni klawiszy. Podaje przestrzenie nazw wysokiego poziomu (więc a:b:1 i a:c:1 są połączone razem jako a:*), wraz z typami jego elementów i procentem pamięci zużywanej przez tę przestrzeń nazw. Warto zacząć od tych informacji, a następnie użyć zachowania „RAM” w połączeniu ze wzorcem przestrzeni nazw, aby przeprowadzić szczegółową analizę.
RMA – tryb RAM
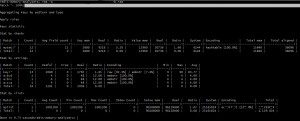
W trybie pamięci RAM uzyskujemy zużycie pamięci na poziomie przestrzeni kluczy, jak zapewnia większość innych analizatorów pamięci FOSS. Tak więc tutaj a:b:1 i a:c:1 są traktowane oddzielnie jako a:b:* i a:c:* i otrzymujemy szczegółowe informacje o wykorzystanej pamięci, rzeczywistym rozmiarze danych, narzutu, kodowaniu, minimalnym i maksymalnym TTL , itp. Pomaga to zlokalizować największych „hoggerów” pamięci w naszym systemie.
Niestety, to narzędzie nie zawsze jest aktualizowane (ostatnie zatwierdzenie na GitHub jest ponad rok temu). Mimo to jest to jeden z najlepszych, jakie znaleźliśmy do szczegółowej analizy.
Instalacja i użytkowanie RMA:
RMA wymaga zainstalowania w systemie Pythona i PIP (oba są dostępne dla wszystkich głównych systemów operacyjnych). Po ich zainstalowaniu możesz wykonać jedno polecenie, aby zainstalować narzędzia RDB – ` pip install rma`
Jest całkiem prosty w użyciu z wiersza poleceń. Składnia to `rma [-s HOST] [-p PORT] [-a HASŁO] [-d DB] [-m wzorzec do dopasowania] [-l liczba-klawiszy do skanowania] [-b ZACHOWANIE] [-t lista-oddzielonych przecinkami-typów-danych-do-skanowania]`
Zalety RMA:
- Działa w czasie rzeczywistym.
- Używa polecenia skanowania do przeglądania bazy danych, stąd wpływ na wydajność jest ograniczony, a analiza bardzo dokładna.
- Dobrze udokumentowane – łatwo znaleźć przykłady użycia.
- Obsługuje zaawansowane opcje dostosowywania i filtrowania, w tym analizowanie tylko określonych typów danych lub uwzględnianie tylko kluczy pasujących do określonego wzorca).
- Może dostarczać szczegółów na różnych poziomach – przestrzeni nazw, kluczy lub wartości globalnych.
- Unikalne wśród wszystkich narzędzi, które skontrolowaliśmy, ponieważ pokazuje narzut struktury danych (czyli ilość pamięci używanej do przechowywania wewnętrznych informacji Redis, takich jak wskaźniki do typu danych listy ).
Wady RMA:
- Nie obsługuje próbkowania probabilistycznego. Liniowe skanowanie bazy danych może być bardzo powolne w przypadku dużych baz danych; istnieje opcja zatrzymania skanowania po zwróceniu określonej liczby kluczy w celu poprawy wydajności.
- W wyniku jest dużo szczegółów; choć pomocny dla ekspertów, może służyć tylko do zmylenia nowicjuszy.
2) Próbnik Redis

Redis Sampler to bardzo potężne narzędzie, które może dać głęboki wgląd w wykorzystanie pamięci przez instancję Redis. Jest utrzymywany przez antireza, programistę stojącego za Redis, i ta głęboka wiedza o Redis pokazuje się w tym narzędziu. Narzędzie nie jest aktualizowane zbyt często – ale i tak nie zgłoszono zbyt wielu problemów.

Redis Sampler wykonuje probabilistyczne skanowanie bazy danych i zgłasza następujące informacje:
- Procentowy rozkład kluczy wśród różnych typów danych – na podstawie liczby kluczy, a nie rozmiaru obiektów.
- Największe klucze typu string, na podstawie strlen i procentu zajmowanej przez nie pamięci.
- Dla wszystkich innych typów danych największe klucze są obliczane i wyświetlane jako dwie oddzielne listy:jedna oparta na rozmiarze obiektu, a druga na podstawie liczby elementów w obiekt.
- Dla każdego typu danych pokazuje również „Rozkład mocy 2”. Jest to naprawdę przydatne w zrozumieniu rozkładu rozmiaru w typie danych. Dane wyjściowe zasadniczo określają, jaki procent kluczy danego typu ma rozmiar w zakresie> 2^x i <=2^x+1.
Instalacja i użytkowanie próbnika Redis:
To jest pojedynczy skrypt Rubiego. Wymaga, aby Ruby był już zainstalowany. Potrzebujesz również zainstalowanych klejnotów `rubygems` i `redis`. Użycie jest dość proste – z wiersza poleceń uruchom `./redis-sampler.rb `
Zalety próbników Redis:
- Bardzo prosty w użyciu – brak opcji do zbadania i zrozumienia.
- Wyniki są łatwe do zrozumienia nawet dla nowicjuszy, ale zawierają wystarczającą ilość informacji do bardzo szczegółowych analiz instancji Redis przez ekspertów. Sekcje są wyraźnie rozgraniczone i łatwe do odfiltrowania.
- Działa we wszystkich wersjach Redis.
- Nie używa żadnych uprzywilejowanych poleceń, takich jak DEBUG OBJECT, więc może być używany w dowolnym systemie, w tym ElastiCache firmy Amazon.
- Wykorzystuje polecenia długości specyficzne dla typu danych w celu określenia rozmiaru danych, więc na raportowane użycie nie ma wpływu serializacja.
- Działa na aktualnych danych. Chociaż zaleca się uruchamianie na interfejsie pętli zwrotnej, obsługuje on próbkowanie systemów zdalnych.
Wady próbnika Redis:
- Jeśli rozmiar próbki jest większy niż kardynalność bazy danych, nadal będzie używany RANDOMKEYS, a nie SCAN.
- Brak dostępnego pakietu lub obrazu Docker. Musisz ręcznie zainstalować zależności (chociaż z drugiej strony są tylko 2 zależności).
- Zgłasza rozmiar danych, który nie odpowiada dokładnie przestrzeni zajmowanej w pamięci RAM z powodu narzutów na przechowywanie struktury danych.
- Nie działa od razu po zainstalowaniu, jeśli instancja Redis wymaga uwierzytelnienia. Musisz zmodyfikować skrypt, aby przyjmował hasło; w najprostszej formie możesz wyszukać:
redis =Redis.new(:host => ARGV[0], :port => ARGV[1].to_i, :db => ARGV[2].to_i)
i zmień go na:
redis =Redis.new(:host => ARGV[0], :port => ARGV[1].to_i, :db => ARGV[2].to_i, :hasło => „dodaj-swoje-hasło-tutaj”)
3) Narzędzia RDB

Narzędzia RDB to bardzo przydatny zestaw narzędzi dla każdego poważnego administratora Redis. Istnieje narzędzie dla prawie każdego przypadku użycia, o którym moglibyśmy pomyśleć, ale w tym poście skoncentrujemy się wyłącznie na narzędziu do analizy pamięci.
Chociaż nie jest to tak wszechstronne, jak RMA lub Redis Sampler, narzędzia RDB dają 3 ważne informacje:

1) Wszystkie klucze, w których wartość ma (serializowany) rozmiar większy niż B bajtów [B określony przez użytkownik].

2) Największe N kluczy [N określone przez użytkownika].

3) Rozmiar konkretnego klucza:jest on odczytywany na żywo z bazy danych.
Ten pakiet ma wielu aktywnych współtwórców na GitHub i jest dość często aktualizowany. Narzędzia RDB są również dobrze udokumentowane w Internecie. Opiekun sripathikrishnan jest dobrze znany w społeczności Redis z wielu narzędzi, które dostarczał przez lata.
Instalacja i użytkowanie narzędzi RDB:
Narzędzia RDB wymagają zainstalowania w systemie Pythona i PIP (oba są dostępne dla wszystkich głównych systemów operacyjnych). Po ich zainstalowaniu możesz wykonać jedno polecenie, aby zainstalować narzędzia RDB – `pip install rdbtools python-lz`
Stosowanie jest dość proste:
- Aby uzyskać 200 największych kluczy:rdb -c pamięć /var/redis/6379/dump.rdb –largest 200 -f memory.csv
- Aby uzyskać wszystkie klucze większe niż 128 bajtów:rdb -c pamięć /var/redis/6379/dump.rdb –bytes 128 -f memory.csv
- Aby uzyskać rozmiar klucza:redis-memory-for-key -s localhost -p 6379 -a mojehasło osoba:1
Zalety narzędzi RDB:
- Wyprowadza plik CSV, który może być używany z innymi narzędziami FOSS do łatwego tworzenia wizualizacji danych, a także może być importowany do systemów RDBMS w celu prowadzenia analiz.
- Bardzo dobrze udokumentowane.
- Obsługuje opcje dostosowywania i filtrowania, dzięki czemu możesz uzyskać bardziej przydatne raporty.
Wady narzędzi RDB:
- Ich analiza nie działa na aktualnych danych; musisz zrobić zrzut RDB. W rezultacie zgłoszone użycie pamięci to pamięć serializowana, która nie jest dokładnie tym samym, co pamięć zajmowana przez pamięć RAM.
- Nie ma wbudowanej obsługi grupowania, więc nie może znaleźć największych przestrzeni nazw.
4) Ponowny audyt

Redis-Audit to narzędzie probabilistyczne, które pozwala uzyskać szybki przegląd wykorzystania pamięci. Wyświetla przydatne informacje o grupach kluczy, takie jak całkowite zużycie pamięci, maksymalny czas TTL w grupie, średni czas ostatniego dostępu, procent kluczy w grupie, które wygasają itp. Jest to idealne narzędzie, jeśli chcesz znaleźć najwięcej pamięci przejmowanie grupy kluczy w Twojej aplikacji.

Ponowny audyt instalacji i użytkowania:
Musisz mieć już zainstalowane Ruby i Bundle. Po zainstalowaniu możesz sklonować repozytorium Redis-Audit do folderu lub pobrać plik zip i rozpakować go do folderu. Z tego folderu uruchom `bundle install`, aby zakończyć instalację.
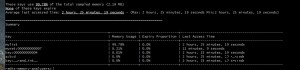
Użycie jest dość proste:z wiersza poleceń wykonaj ` redis-audit.rb hostname [port] [hasło] [dbnum] [rozmiar_przykładu]`

Zalety ponownego audytu:
- Pozwala zdefiniować własne wyrażenie regularne dla grupowania przestrzeni kluczy/prefiksów.
- Działa we wszystkich wersjach Redis.
- Jeśli rozmiar próbki jest większy niż rzeczywista liczba kluczy, przechodzi przez wszystkie klucze. Z drugiej strony ta operacja używa klawiszy * zamiast skanowania – prawdopodobnie blokując inne operacje.
Wady ponownego audytu:
- Używa polecenia DEBUG OBJECT (niedostępne w ElastiCache); w rezultacie zgłasza rozmiar serializowany – który różni się od rzeczywistego rozmiaru zajmowanego przez pamięć RAM.
- Wyjście nie jest łatwe do szybkiego przeanalizowania, ponieważ nie jest ujęte w formie tabelarycznej.
5) Zestaw narzędzi Redis

Redis Toolkit to podstawowe rozwiązanie do monitorowania, które można wykorzystać do analizy dwóch kluczowych wskaźników:wskaźnika trafień i zużycia pamięci. Projekt jest okresowo aktualizowany o poprawki błędów, ale nie ma wsparcia społeczności dla niektórych z bardziej znanych narzędzi.
Instalacja i użytkowanie zestawu narzędzi Redis:

Musisz mieć zainstalowany Docker w swoim systemie. Następnie sklonuj repozytorium GitHub (lub pobierz jako zip i rozpakuj do folderu). Instalacja z tego folderu jest tak prosta, jak wykonanie `./redis-toolkit install`.
Użycie odbywa się wyłącznie za pomocą wiersza poleceń, za pomocą serii prostych poleceń.
- Aby rozpocząć monitorowanie wskaźnika trafień:./redis-toolkit monitor
- Aby zgłosić współczynnik trafień:./redis-toolkit report -name NAME -type hitrate
- Aby zatrzymać monitorowanie współczynnika trafień:./redis-toolkit stop
- Aby utworzyć plik zrzutu w systemie lokalnym:./redis-toolkit dump
- Aby zgłosić użycie pamięci:./redis-toolkit report -type memory -name NAZWA
Zalety zestawu narzędzi Redis:
- Łatwy do zrozumienia interfejs, który podaje dokładne informacje, których potrzebujesz.
- Może grupować prefiksy do dowolnego poziomu, który jest dla Ciebie przydatny (więc jeśli wybierzesz a:b:1 i a:c:1, są one liczone jako a:* lub osobno) .
- Działa na wszystkich wersjach Redis; nie wymaga dostępu do uprzywilejowanych poleceń, takich jak DEBUG OBJECT.
- Dobrze udokumentowane.
Wady zestawu narzędzi Redis:
- Analiza pamięci nie jest aktywna; ponieważ działa na serializowanym zrzucie, raportowane użycie pamięci nie będzie równe rzeczywistemu zużyciu pamięci RAM.
- Na komputerze, na którym działa Redis Toolkit, należy utworzyć zrzut. Jeśli masz zdalną instancję Redis, może to chwilę potrwać.
- Monitorowanie współczynnika trafień wykorzystuje polecenie MONITOR do przechwytywania wszystkich poleceń, które zostały uruchomione na serwerze. Może to obniżyć wydajność i stanowi potencjalne zagrożenie bezpieczeństwa w produkcji.
- Współczynnik trafień jest obliczany jako |GET| / (|GET| + |SET|). Więc jeśli wartość zmienia się często, jej współczynnik trafień będzie niższy, nawet jeśli nigdy nie było rzeczywistego chybienia w pamięci podręcznej.
6) Zbiory

Jest to probabilistyczne narzędzie do próbkowania, którego można użyć do zidentyfikowania 10 największych przestrzeni nazw/prefiksów pod względem liczby kluczy. Jest to jedno z najnowszych narzędzi i nie cieszy się zbytnią popularnością na GitHubie. Ale jeśli jesteś nowicjuszem Redis, który chce zidentyfikować rodzaj danych aplikacji zatykających twoją instancję, nie możesz uzyskać niczego prostszego niż Harvest.
Instalacja i użytkowanie zbiorów:
To jest do pobrania jako obraz Docker. Gdy obraz jest gotowy, możesz uruchomić narzędzie za pomocą polecenia „docker run –link redis:redis -it –rm 31z4/harvest redis://redis-URL” z CLI.
Profesjonalne zbiory:
- Działa na danych na żywo.
- Używa polecenia „wykorzystanie pamięci”, aby uzyskać informacje o rozmiarze; stąd:
- Podaje dokładne informacje o rozmiarze (zamiast serializowanego rozmiaru).
- Nie wymaga dostępu do polecenia DEBUGUJ OBIEKT.
- Twoje przestrzenie nazw nie muszą być oddzielone:(dwukropkiem). Harvest identyfikuje popularne prefiksy, a nie zależy od rozpoznawania przestrzeni nazw opartej na wyrażeniach regularnych.
Wady zbiorów:
- To jednorazowy kucyk – trudno go dostosować do innego przypadku użycia.
- Narzędzie działa tylko z Redis v4.0 i nowszymi.
- Minimalna dokumentacja.
Ograniczenia bezpłatnych narzędzi
Chociaż narzędzia te okazały się bardzo przydatne do debugowania problemów z pamięcią naszych instancji Redis, należy zdawać sobie sprawę z ograniczeń tych bezpłatnych narzędzi.
Płatne narzędzia prawie zawsze mają jakiś rodzaj wizualizacji danych, która nie jest dostępna od razu po zainstalowaniu żadnego z narzędzi, które skontrolowaliśmy. Najlepsze, co otrzymasz, to wynik w formacie CSV, który możesz wykorzystać do wizualizacji za pomocą innych narzędzi FOSS, a wiele narzędzi nie ma nawet takiej opcji. To oznacza stromą krzywą uczenia się, szczególnie dla początkujących użytkowników Redis. Jeśli prawdopodobnie często przeprowadzasz analizę pamięci, warto przyjrzeć się płatnym narzędziom, które zapewniają dobrą wizualizację.
Kolejnym ograniczeniem jest możliwość przechowywania informacji historycznych. Zgodnie z ogólną filozofią *nix tworzenia małych narzędzi, które robią tylko jedną rzecz, ale robią to dobrze, narzędzia rzadko zapuszczają się w przestrzeń monitorowania. Nie ma nawet wykresu zużycia pamięci w czasie, a wiele z nich nie może nawet analizować danych na żywo.
Konkluzja
Jedno narzędzie prawdopodobnie nie wystarczy do wszystkich Twoich potrzeb, ale w połączeniu z możliwościami monitorowania jest to świetna broń, którą możesz mieć w swoim arsenale dostarczane przez rozwiązania DBaaS, takie jak hosting ScaleGrid dla Redis™*! Aby dowiedzieć się więcej o wspaniałych narzędziach dostępnych w ramach naszych w pełni zarządzanych usług hostingowych dla Redis™, zapoznaj się z naszymi funkcjami ScaleGrid dla Redis™ według planu.




