Stworzyłem arkusz kalkulacyjny, aby lepiej zilustrować efekt węzłów Arbiter w zestawie replik.
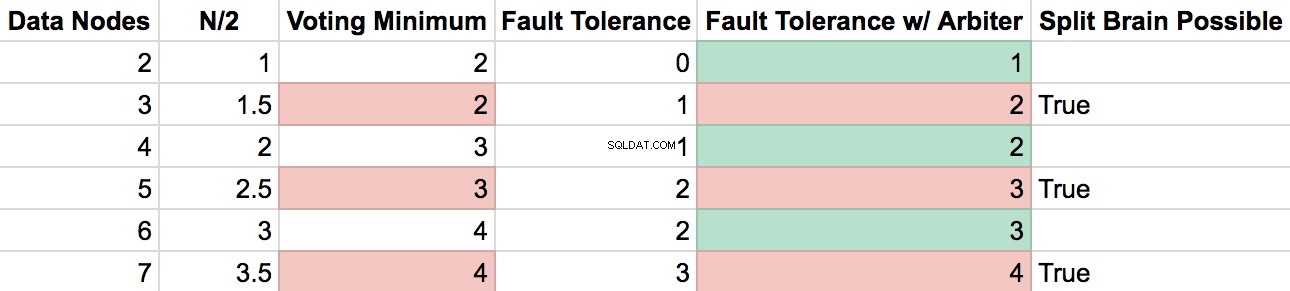
Zasadniczo sprowadza się to do tych punktów:
- Z RS z 2 węzłami danych , utrata 1 serwera spowoduje, że spadniesz poniżej minimum głosów (które jest „większe niż N/2”). Arbiter rozwiązuje to.
- Z RS parzystych węzłów danych , dodanie Arbitra zwiększa odporność na błędy o 1 bez możliwości posiadania 2 klastrów głosujących z powodu podziału.
- Z RS nieparzystych węzłów danych , dodanie Arbitra umożliwiłoby podziałowi utworzenie 2 odizolowanych klastrów z głosami „większymi niż N/2”, a zatem scenariusz podziału mózgu.
Wybory są tutaj wyjaśnione [mniej] szczegółowo. W tym dokumencie oświadcza że RS może mieć 50 członków (liczba parzysta) i 7 członków głosujących. Podkreślam „stany”, ponieważ to nie wyjaśnia jak to działa. Wydaje mi się, że jeśli dojdzie do rozłamu z 4 członkami (wszyscy głosujący) po jednej stronie i 46 członkami (3 głosujący) po drugiej, wolałbyś, aby 46 wybrało prawybory, a 4 były tylko klaster. Ale właśnie to uniemożliwia „ograniczone głosowanie”. W takiej sytuacji faktycznie będziesz mieć 4-członowy klaster z podstawowym i 46-członowym klastrem, który jest tylko do odczytu. Wyjaśnienie, jak to ma sens, wykracza poza zakres tego pytania i jest poza moją wiedzą.



