Wydajność bazy danych wpływa na wydajność organizacji i zwykle szukamy szybkiego rozwiązania. Istnieje wiele różnych sposobów poprawy wydajności w MongoDB. Na tym blogu pomożemy Ci lepiej zrozumieć obciążenie bazy danych i rzeczy, które mogą jej szkodzić. Wiedza o tym, jak korzystać z ograniczonych zasobów, jest niezbędna dla każdego, kto zarządza produkcyjną bazą danych.
Pokażemy Ci, jak zidentyfikować czynniki ograniczające wydajność bazy danych. Aby baza danych działała zgodnie z oczekiwaniami, zaczniemy od bezpłatnego narzędzia monitorującego MongoDB Cloud. Następnie sprawdzimy, jak zarządzać plikami logów i jak badać zapytania. Aby móc osiągnąć optymalne wykorzystanie zasobów sprzętowych, przyjrzymy się optymalizacji jądra i innym kluczowym ustawieniom systemu operacyjnego. Na koniec przyjrzymy się replikacji MongoDB i sposobom badania wydajności.
Bezpłatne monitorowanie wydajności
MongoDB wprowadziło bezpłatne narzędzie do monitorowania wydajności w chmurze dla samodzielnych instancji i zestawów replik. Po włączeniu monitorowane dane są okresowo przesyłane do usługi w chmurze dostawcy. Nie wymaga to żadnych dodatkowych agentów, funkcjonalność jest wbudowana w nowy MongoDB 4.0+. Proces jest dość prosty w konfiguracji i zarządzaniu. Po aktywacji jednym poleceniem otrzymasz unikalny adres internetowy, aby uzyskać dostęp do najnowszych statystyk wydajności. Możesz uzyskać dostęp tylko do monitorowanych danych, które zostały przesłane w ciągu ostatnich 24 godzin.
Oto jak aktywować tę funkcję. Możesz włączyć/wyłączyć bezpłatne monitorowanie w czasie wykonywania za pomocą:
-- Enable Free Monitoring
db.enableFreeMonitoring()
-- Disable Free Monitoring
db.disableFreeMonitoring()Możesz także włączyć lub wyłączyć bezpłatne monitorowanie podczas uruchamiania mongod za pomocą ustawienia pliku konfiguracyjnego cloud.monitoring.free.state lub opcji wiersza poleceń --enableFreeMonitoring
db.enableFreeMonitoring()Po aktywacji zobaczysz komunikat z aktualnym statusem.
{
"state" : "enabled",
"message" : "To see your monitoring data, navigate to the unique URL below. Anyone you share the URL with will also be able to view this page. You can disable monitoring at any time by running db.disableFreeMonitoring().",
"url" : "https://cloud.mongodb.com/freemonitoring/cluster/XEARVO6RB2OTXEAHKHLKJ5V6KV3FAM6B",
"userReminder" : "",
"ok" : 1
}Po prostu skopiuj/wklej adres URL z danych wyjściowych stanu do przeglądarki i możesz zacząć sprawdzać wskaźniki wydajności.
Darmowy monitoring MongoDB dostarcza informacji o następujących wskaźnikach:
- Czasy wykonania operacji (ODCZYT, ZAPIS, POLECENIA)
- Wykorzystanie dysku (MAKS. % UTIL KAŻDEGO DYSKÓW, ŚREDNI % UTIL WSZYSTKICH DYSKÓW)
- Pamięć (MIESZKANA, WIRTUALNA, MAPOWANA)
- Sieć - Wejście / Wyjście (BYTES IN, BYTES OUT)
- Sieć – liczba żądań (NUM REQUESTS)
- Operatorzy (WSTAW, ZAPYTAJ, AKTUALIZUJ, USUŃ, POBIERZ, POLECAĆ)
- Opcounters — replikacja (WSTAW, ZAPYTANIE, AKTUALIZACJA, USUŃ, POBIERZ, POLECENIE)
- Kierowanie zapytań (ZESKANOWANE / ZWRÓCONE, ZESKANOWANE OBIEKTY / ZWRÓCONE)
- Kolejki (CZYTELNIKI, PISARZE, RAZEM)
- Wykorzystanie procesora systemowego (USER, NICE, KERNEL, IOWAIT, IRQ, SOFT IRQ, STEAL, GUEST)
 MongoDB Darmowe monitorowanie pierwsze użycie
MongoDB Darmowe monitorowanie pierwsze użycie  Wykorzystanie procesora przez bezpłatny system monitorowania MongoDB
Wykorzystanie procesora przez bezpłatny system monitorowania MongoDB 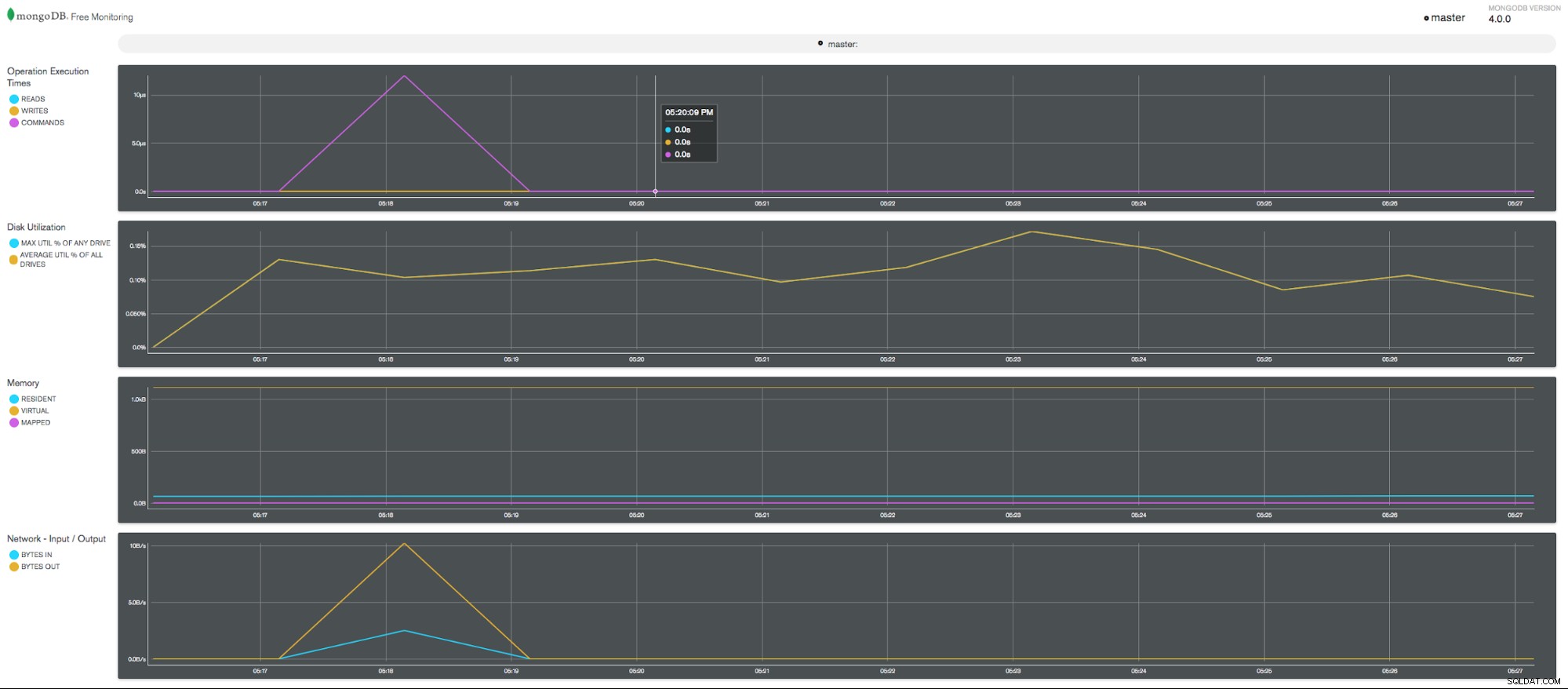 Bezpłatne wykresy monitorowania MongoDB
Bezpłatne wykresy monitorowania MongoDB Aby wyświetlić stan bezpłatnej usługi monitorowania, użyj następującej metody:
db.getFreeMonitoringStatus()ServerStatus i helper db.serverStatus() zawierają również darmowe statystyki monitorowania w darmowym polu Monitoring.
Podczas uruchamiania z kontrolą dostępu użytkownik musi mieć następujące uprawnienia, aby włączyć bezpłatne monitorowanie i uzyskać status:
{ resource: { cluster : true }, actions: [ "setFreeMonitoring", "checkFreeMonitoringStatus" ] }To narzędzie może być dobrym początkiem dla tych, którym trudno jest odczytać stan serwera MongoDB z wiersza poleceń:
db.serverStatus()Darmowe monitorowanie to dobry początek, ale ma bardzo ograniczone opcje, jeśli potrzebujesz bardziej zaawansowanego narzędzia, możesz sprawdzić MongoDB Ops Manager lub ClusterControl.
Logowanie operacji na bazie danych
Sterowniki MongoDB i aplikacje klienckie mogą wysyłać informacje do pliku dziennika serwera. Taka informacja zależy od rodzaju wydarzenia. Aby sprawdzić bieżące ustawienia, zaloguj się jako administrator i wykonaj:
db.getLogComponents()Komunikaty dziennika zawierają wiele komponentów. Ma to na celu zapewnienie funkcjonalnej kategoryzacji wiadomości. Dla każdego składnika można ustawić inną szczegółowość dziennika. Aktualna lista komponentów to:
ACCESS, COMMAND, CONTROL, FTD, GEO, INDEX, NETWORK, QUERY, REPL_HB, REPL, ROLLBACK, REPL, SHARDING, STORAGE, RECOVERY, JOURNAL, STORAGE, WRITE.Aby uzyskać więcej informacji na temat każdego z komponentów, zapoznaj się z dokumentacją.
Przechwytywanie zapytań — Database Profiler
MongoDB Database Profiler zbiera informacje o operacjach wykonywanych na instancji mongod. Profiler domyślnie nie zbiera żadnych danych. Możesz wybrać zbieranie wszystkich operacji (wartość 2) lub tych, które trwają dłużej niż wartość slowms . Ten ostatni jest parametrem instancji, który można kontrolować za pomocą pliku konfiguracyjnego mongodb. Aby sprawdzić aktualny poziom:
db.getProfilingLevel()Aby przechwycić wszystkie zestaw zapytań:
db.setProfilingLevel(2)W pliku konfiguracyjnym możesz ustawić:
profile = <0/1/2>
slowms = <value>To ustawienie zostanie zastosowane w jednej instancji i nie będzie propagowane w zestawie replik ani w udostępnionym klastrze, więc jeśli chcesz przechwycić wszystkie działania, musisz powtórzyć to polecenie dla wszystkich węzłów. Profilowanie bazy danych może mieć wpływ na wydajność bazy danych. Włącz tę opcję dopiero po dokładnym rozważeniu.
Następnie lista 10 najnowszych:
db.system.profile.find().limit(10).sort(
{ ts : -1 }
).pretty()Aby wyświetlić wszystkie:
db.system.profile.find( { op:
{ $ne : 'command' }
} ).pretty()Aby wystawić listę dla określonej kolekcji:
db.system.profile.find(
{ ns : 'mydb.test' }
).pretty()Logowanie MongoDB
Lokalizacja dziennika MongoDB jest zdefiniowana w ustawieniach logpath konfiguracji i zwykle jest to /var/log/mongodb/mongod.log. Plik konfiguracyjny MongoDB można znaleźć w /etc/mongod.conf.
Oto przykładowe dane:
2018-07-01T23:09:27.101+0000 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to node1:27017
2018-07-01T23:09:27.102+0000 I ASIO [NetworkInterfaceASIO-Replication-0] Failed to connect to node1:27017 - HostUnreachable: Connection refused
2018-07-01T23:09:27.102+0000 I ASIO [NetworkInterfaceASIO-Replication-0] Dropping all pooled connections to node1:27017 due to failed operation on a connection
2018-07-01T23:09:27.102+0000 I REPL_HB [replexec-2] Error in heartbeat (requestId: 21589) to node1:27017, response status: HostUnreachable: Connection refused
2018-07-01T23:09:27.102+0000 I ASIO [NetworkInterfaceASIO-Replication-0] Connecting to node1:27017Możesz zmienić szczegółowość dziennika komponentu, ustawiając (przykład zapytania):
db.setLogLevel(2, "query")Plik dziennika może być istotny, więc warto go wyczyścić przed profilowaniem. W konsoli wiersza poleceń MongoDB wpisz:
db.runCommand({ logRotate : 1 });Sprawdzanie parametrów systemu operacyjnego
Limity pamięci
Aby zobaczyć ograniczenia związane z Twoim loginem, użyj polecenia ulimit -a. Następujące progi i ustawienia są szczególnie ważne w przypadku wdrożeń mongod i mongos:
-f (file size): unlimited
-t (cpu time): unlimited
-v (virtual memory): unlimited
-n (open files): 64000
-m (memory size): unlimited [1]
-u (processes/threads): 32000Nowsza wersja skryptu startowego mongod (/etc/init.d/mongod) ma domyślne ustawienia wbudowane w opcję startową:
start()
{
# Make sure the default pidfile directory exists
if [ ! -d $PIDDIR ]; then
install -d -m 0755 -o $MONGO_USER -g $MONGO_GROUP $PIDDIR
fi
# Make sure the pidfile does not exist
if [ -f "$PIDFILEPATH" ]; then
echo "Error starting mongod. $PIDFILEPATH exists."
RETVAL=1
return
fi
# Recommended ulimit values for mongod or mongos
# See https://docs.mongodb.org/manual/reference/ulimit/#recommended-settings
#
ulimit -f unlimited
ulimit -t unlimited
ulimit -v unlimited
ulimit -n 64000
ulimit -m unlimited
ulimit -u 64000
ulimit -l unlimited
echo -n $"Starting mongod: "
daemon --user "$MONGO_USER" --check $mongod "$NUMACTL $mongod $OPTIONS >/dev/null 2>&1"
RETVAL=$?
echo
[ $RETVAL -eq 0 ] && touch /var/lock/subsys/mongod
}Rolą podsystemu zarządzania pamięcią, zwanego również menedżerem pamięci wirtualnej, jest zarządzanie alokacją pamięci fizycznej (RAM) dla całego jądra i programów użytkownika. Jest to kontrolowane przez parametry vm.*. Są dwa, które należy rozważyć w pierwszej kolejności, aby dostroić wydajność MongoDB — vm.dirty_ratio i vm.dirty_background_ratio .
vm.dirty_ratio to absolutna maksymalna ilość pamięci systemowej, którą można wypełnić brudnymi stronami, zanim wszystko będzie musiało zostać zapisane na dysku. Gdy system dotrze do tego punktu, wszystkie nowe bloki we/wy do momentu zapisania na dysku brudnych stron. Jest to często źródłem długich przerw we/wy. Wartość domyślna to 30, co zwykle jest zbyt wysokie. vm.dirty_background_ratio to procent pamięci systemowej, który można wypełnić „brudnymi” stronami — stronami pamięci, które nadal wymagają zapisania na dysku. Dobrym początkiem jest przejście od 10 i pomiar wydajności. W środowisku o małej ilości pamięci 20 to dobry początek. Zalecane ustawienie dla brudnych współczynników na serwerach baz danych o dużej pamięci to vm.dirty_ratio =15 i vm.dirty_background_ratio =5 lub prawdopodobnie mniej.
Aby sprawdzić brudny bieg proporcji:
sysctl -a | grep dirtyMożesz to ustawić, dodając następujące wiersze do „/etc/sysctl.conf”:
Zamień
Na serwerach, na których MongoDB jest jedyną uruchomioną usługą, dobrą praktyką jest ustawienie vm.swapiness =1. Domyślne ustawienie to 60, co nie jest odpowiednie dla systemu bazy danych.
vi /etc/sysctl.conf
vm.swappiness = 1Przejrzyste duże strony
Jeśli używasz MongoDB na RedHat, upewnij się, że opcja Transparent Huge Pages jest wyłączona.
Można to sprawdzić za pomocą polecenia:
cat /proc/sys/vm/nr_hugepages
00 oznacza, że przezroczyste duże strony są wyłączone.
Opcje systemu plików
ext4 rw,seclabel,noatime,data=ordered 0 0NUMA (niejednolity dostęp do pamięci)
MongoDB nie obsługuje NUMA, wyłącz ją w BIOS-ie.
Stos sieciowy
net.core.somaxconn = 4096
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_time = 120
net.ipv4.tcp_max_syn_backlog = 4096demon NTP
Aby zainstalować demona serwera czasu NTP, użyj jednego z następujących poleceń systemowych.
#Red Hat
sudo yum install ntp
#Debian
sudo apt-get install ntpWięcej informacji na temat wydajności systemu operacyjnego dla MongoDB można znaleźć w innym blogu.
Wyjaśnij plan
Podobnie jak inne popularne systemy bazodanowe, MongoDB udostępnia funkcję wyjaśniania, która pokazuje, w jaki sposób została wykonana operacja na bazie danych. Wyniki wyjaśniania wyświetlają plany zapytań w postaci drzewa etapów. Każdy etap przekazuje swoje zdarzenia (tj. dokumenty lub klucze indeksu) do węzła nadrzędnego. Węzły liści uzyskują dostęp do kolekcji lub indeksów. Możesz dodać wyjaśnienie('executionStats') do zapytania.
db.inventory.find( {
status: "A",
$or: [ { qty: { $lt: 30 } }, { item: /^p/ } ]
} ).explain('executionStats');
or append it to the collection:
db.inventory.explain('executionStats').find( {
status: "A",
$or: [ { qty: { $lt: 30 } }, { item: /^p/ } ]
} );Klucze, na których wartości należy zwrócić uwagę w wyniku wykonania powyższego polecenia:
- totalKeysExamined:całkowita liczba wpisów indeksu zeskanowanych w celu zwrócenia zapytania.
- totalDocsExamined:całkowita liczba dokumentów zeskanowanych w celu znalezienia wyników.
- executionTimeMillis:Całkowity czas w milisekundach wymagany do wyboru planu zapytania i wykonania zapytania.
Pomiar opóźnienia replikacji
Opóźnienie replikacji to opóźnienie między operacją na podstawowym a zastosowaniem tej operacji z oploga do pomocniczego. Innymi słowy, określa, jak daleko węzeł wtórny znajduje się za węzłem głównym, co w najlepszym przypadku powinno być jak najbliżej 0.
Na proces replikacji może mieć wpływ wiele powodów. Jednym z głównych problemów może być to, że członkom pomocniczym brakuje mocy obliczeniowej serwera. Duże operacje zapisu na podstawowym elemencie, które prowadzą do tego, że drugorzędni członkowie nie są w stanie odtworzyć oplogów lub budowanie indeksu na podstawowym elemencie.
Aby sprawdzić bieżące opóźnienie replikacji, uruchom w powłoce MongoDB:
db.getReplicationInfo()
db.getReplicationInfo()
{
"logSizeMB" : 2157.1845703125,
"usedMB" : 0.05,
"timeDiff" : 4787,
"timeDiffHours" : 1.33,
"tFirst" : "Sun Jul 01 2018 21:40:32 GMT+0000 (UTC)",
"tLast" : "Sun Jul 01 2018 23:00:19 GMT+0000 (UTC)",
"now" : "Sun Jul 01 2018 23:00:26 GMT+0000 (UTC)"Dane wyjściowe stanu replikacji można wykorzystać do oceny bieżącego stanu replikacji i określenia, czy występuje niezamierzone opóźnienie replikacji.
rs.printSlaveReplicationInfo()Pokazuje opóźnienie czasowe między elementami drugorzędnymi w stosunku do elementów podstawowych.
rs.status()Pokazuje szczegółowe szczegóły replikacji. Za pomocą tych poleceń możemy zebrać wystarczającą ilość informacji o replikacji. Mamy nadzieję, że te wskazówki dają szybki przegląd, jak sprawdzić wydajność MongoDB. Daj nam znać, jeśli coś przeoczyliśmy.



